
The beginnings of a content model for future undergraduate study content
Our team has been working to create a content model for the future of prospective undergraduate online provision. In this post, I recap the initial sprints we held to begin to develop the model.
Working towards a future state for prospective student online provision
This content modelling work is part of a bigger project to improve online provision for prospective students at the University.
Read Neil Allison’s post about our future state project
Our first stage of the project will see us improving undergraduate content, largely focusing on developing a replacement for the undergraduate degree finder.
Our current undergraduate degree finder
What a content model is
To redevelop the degree finder and our overall approach to undergraduate study content at the University, we need to develop a content model.
I like this definition from content strategist Lauren Pope to describe what a content model is:
A content model documents all the different kinds of content you have on your website. It breaks content types down into their component parts, describes them in detail, and maps out how they relate to one another.
-Lauren Pope
Lauren Pope’s article on content models on GatherContent blog
Goal of the content modelling sprints
The goal of the content modelling sprints was to build up a comprehensive list of all the different component parts that could exist in a future state of the undergraduate degree finder.
By doing so, we could create a backlog of content areas to work through when we develop the new degree finder.
From auditing to content modelling
Our content modelling sprints built on the content auditing the team had been doing in the spring and summer.
Our audits looked at University service and school sites to:
- determine if any content was prospective student focused, and if so, what content
- get a sense of content on the site that was redundant, outdated or trivial
That first point was crucial to the content modelling sprints. What content were schools or other sites publishing about prospective students that should exist in the degree finder?
We know from schools that the current undergraduate degree finder cannot accommodate all the types of content they want to publish. We needed to find out what this content was to incorporate it into our model.
Setting up the sprints
Prior to the sprints, I did some prep work to develop how we would approach building the content model.
Deciding on terminology
Content modelling introduced some new terms to the team, so it was important to develop our own terminology list to make sure we were calling things by the same name.
Part of this involved using terminology I came across in my background reading, and part of this came from creating my own terms to fit our needs.
Most of my background reading was from Lauren Pope’s article mentioned previously and Cleeve Gibbon’s series content modelling posts.
Cleve Gibbon’s Content Modeling Series
The main terms to share all have to do with attributes:
- attribute: the different component parts on a degree finder entry (example: tuition fees, entry requirements)
- main attribute: the heading for a group of attributes (example: entry requirements)
- subattribute: one of the attributes within a heading (example: English language requirements is a subattribute of main attribute entry requirements)
Attribute is widely used in content modelling literature, but main and subattribute were terms I invented. I wanted a way to describe the difference between the different sections of degree finder content.
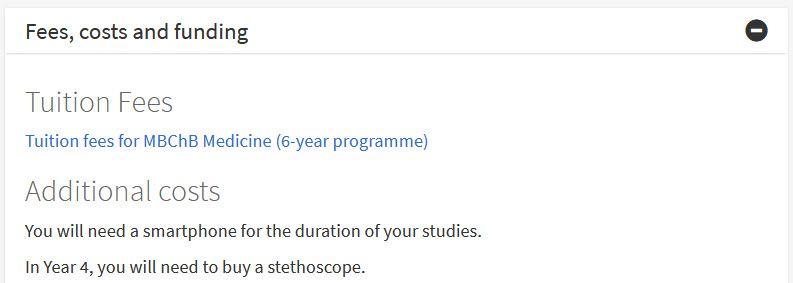
In the current undergraduate degree finder, I’d class ‘Fees, costs and funding’ as a main attribute, while ‘Tution fees’ and ‘Additional costs’ would be subattributes.
Building an initial list of attributes
Before getting to the details of our content model, I first needed to develop a list of all the attributes that could be in an undergraduate degree finder entry.
For that, I used existing work done by our user researchers to build up a priority order of attributes following our design sprints last year.
I supplemented this by going through the existing degree finder and adding any attributes not already in the priority order list. Neil, head of our team, also helped by digging out unique attributes we discovered in the audits.
I treated all these items as subattributes and developed a main attribute heading title to place these under. For example, student-generated content (like blogs and vlogs) would sit under the main attribute ‘Life at Edinburgh’, which would contain subattributes about the city of Edinburgh and the social aspects of studying here.
Creating an attribute spreadsheet
With an initial list of attributes sorted, I built a spreadsheet for us to use in the sprints. The spreadsheet was where we would list the details of each attribute. It was based on a template from Lauren Pope referenced in the GatherContent article mentioned previously.
The spreadsheet included fields for:
- attribute type: what each attribute shows as (for example, text, image, table)
- requirement: is it compulsory in the degree finder, and if so, do all programmes need this attribute?
- author: who will be responsible for writing this content?
- permissions: who will be able to edit the content?
- reusability: can it be used across other programme pages?
- rich content: can the attribute use images and videos?
- purpose: what should the attribute do?
- writing: how should the attribute be written?
- sample: are there examples from the University of Edinburgh or other universities that illustrate this attribute?
What we did in the sprints
During the sprints, each content designer was assigned a few main attributes and all their subattributes.
Our task was to look at the University of Edinburgh degree finder, other UK university course finders and University of Edinburgh school sites to build up an idea of:
- what info is displayed in these attributes
- how the attribute is displayed
We then used these insights to fill in the attribute spreadsheet. This has created a detailed list of all the things we need to know and consider about these attributes when we get to developing the new degree finder.
We also took screenshots of examples of attributes and put them on a Miro board. We included examples from all the various sites we were looking through, making notes of what was good (or not) about the examples.

Part of our Miro board where we added screenshots and notes of attributes. This how three different universities display rankings information.
Finding new potential attributes
Through auditing degree content across the HE sector, we picked up on some ideas of new attributes we could include in the degree finder.
For example, both Bath and Dundee list the main study location in the boxes where they list key facts about the programme (what we’re calling programme metadata).

Dundee lists which campus the programme is studied right at the top of the programme page.
York has a tagline to help sell the programme in one line.

The Archaeology degree at York has the tagline ‘Delve into the story of humankind’.
Finding these new attributes doesn’t mean we will ultimately include them in the new degree finder. Rather, exploring other content has helped us build a rich list of attributes to use as building blocks to try out in our new designs.
We’ll keep what works and bin what doesn’t.
What’s next
Aligning attributes with user research
Since the sprints, we have been working with Pete, our UX Specialist, to align these attributes with the user research done for the degree finder project.
We’re using the research to inform:
- whether there’s a user need for the attributes we’ve noted down
- the prioritised order attributes should show in on the degree finder
- what the attributes should be called
Mapping content relationships
We’re also looking beyond the attribute level to how degree finder content relates to other undergraduate content on the website.
Flo, content designer on the team, is working to map the relationships between:
- degree finder content
- undergraduate study site content
- prospective undergraduate content in schools and service sites across the University web estate
With a better idea of what could be going into the future degree finder, we can begin to set the vision for how and where to repurpose existing content to provide a better experience for our prospective students.
Learn more at our update event 1 December
We’ll be sharing more on this blog of how we have developed the content model further.
In the meantime, you can learn about the latest state of the content model at our update event on 1 December.


2 replies to “The beginnings of a content model for future undergraduate study content”