
How can people trust AI-generated content? Designing provenance data into our prototype AI searchbot
As AI-generated content becomes increasingly prevalent, questions of trust emerge, prompting a growing need for transparency about the creation of digital content. As part of an academic study, I designed and prototyped ways to display provenance data for synthetic content made by an AI searchbot on a University website.
Working in UX, I’m always eager to understand how people respond to digital services, systems and products. With AI fast becoming a part of all aspects of our digital lives, myself and my team have carried out UX research to understand what people expect from these new technologies and how they respond to them. Having watched students and staff interact with AI features, I’ve observed the fundamental importance of trust and learned that if people don’t trust the content from an AI chatbot or interface, they won’t use it.
Read about our UX research of AI features:
How do students respond to AI in an enquiry service? What we learned testing AskEdHelp
How do students respond to AI-powered search, and how does it compare to Google?
Initial insights from UX testing our Drupal AI content assistant tool
Transparency matters when building trustworthy AI features
A research paper looking at how people trust AI systems found that trust depended on various factors, including:
- How people already feel about AI based on previous experience (antecedent-based cognitive and emotional factors)
- Accountability – who is responsible for the AI system and its output
- Accuracy and correctness of output from the AI system
- Data considerations – what sources the AI system uses and how it handles data
- Transparency – ensuring the AI system is not a mysterious ‘black box’
Source: Omrani, N., Rivieccio, G., Fiore, U., Schiavone, F. and Garcia Agreda, S. (2022) ‘To trust or not to trust? An assessment of trust in AI-based systems: Concerns, ethics and contexts’, Technological Forecasting and Social Change, 181, August [pp 1-10] (available on DiscoverEd with University login)
It’s important to take all of these factors into account when designing AI features and it is especially crucial to recognise that trust cannot be assumed. It’s impossible to control the preconceptions a person will bring to something like an AI chatbot – everyone will come with different expectations and prior experiences.
With this in mind, including transparency in the design considerations of AI features is of paramount importance to allow users to be informed enough to make their own judgements. Being upfront and clear about how an AI feature works, what it can do, the data it uses, its accuracy, and who is accountable for it is a responsible approach to take since it enables people to make evidence-based decisions about whether to use it or not to trust it.
The University follows this maxim, highlighting the need for transparency and provenance in its staff guidance about AI use.
Be transparent. If your output is published, cite the tool, version and date, and keep a brief record of prompts/outputs where a provenance trail may be needed – excerpt from Using Generative AI in Your Work: Guidance for Staff
I was interested to consider how to design for trust by ensuring transparency in the context of one of our AI experiments, the AI searchbot built on a demonstration University website, described in this blog post:
Can AI help or hinder search? Trials with Drupal AI-boosted search and AI Assistants
View demonstration video of AI searchbot (on MediaHopper)
CP2A defined an open standard to verify the provenance of digital content
The Coalition for Content Provenance and Authenticity (C2PA) is a global initiative, formed to address issues of digital misinformation and content authenticity. It created a standard to verify the provenance of digital content. This standard sets out specifications that define a Content Credential which is essentially, a record attached to a piece of content to demonstrate its provenance. The Content Credential (or C2PA Manifest) contains different types of provenance data, including:
- Where the content came from, who made it and when it was created
- How it was created (whether AI was used)
- What edits or modifications were made to it (and with which tools)
When considering how to embed the transparency principle in the design of the AI searchbot and its AI-generated responses, it seemed appropriate to try to adopt and apply the CP2A standard. By following the standard’s specifications, I worked out how to show the verifiable history of the AI-generated search responses – which would serve as provenance data to enable people to judge whether to trust the content or not.
Read more about the formation of the CP2A and its uses in these BBC articles:
Mark the good stuff: Content provenance and the fight against disinformation (5 March 2024)
Does provenance build trust? (24 May 2024)
Read more about the CP2A on its website:
Read the full CP2A specifications in the guidance document:
C2PA User Experience Guidance for Implementers: C2PA Specifications
I took part in a study to apply the CP2A standard to our AI searchbot
As part of a research initiative led by DECaDE, the UKRI Next Stage Centre for the Decentralised Digital Economy, I completed a task to design provenance data for the AI searchbot responses. The task required me to work through multiple stages, I needed to:
- Understand how C2PA terms applied in the context of the AI searchbot responses
- Identify categories of provenance data to be displayed
- Decide which types of data would be useful to and expected by the user during their interaction with the AI searchbot
- Consider placement of the provenance data alongside the AI-generated content
I worked through each of these stages in turn.
I identified three types of provenance data for the AI searchbot responses
Before beginning the design task, I studied the C2PA specifications to understand how they applied to content from the AI searchbot. I extracted key C2PA terms and identified their relevance to the searchbot and its responses, laying this information out in a table:
| C2PA term | Application to AI searchbot |
| Asset | The AI-generated response |
| Assertions (actions that made the asset) | Indexing and search mechanisms that produced the search results
ELM, the LLM interpreting query and making a conversational response
|
| Ingredients (what is included in the asset) | Raw search results (source links)
Details of the models in ELM, used to make conversational response AI prompt used to shape response |
| Signer (party responsible for the asset) | University of Edinburgh |
| Timestamp (detailing when the asset was made) | Date and time extracted from the AI logs |
I established that a Content Credentials record for an AI response produced by the searchbot would contain three types of provenance data:
- Content certification data, including:
- Details of the signer vouching for the response (the University of Edinburgh)
- Timestamp/date showing when the response was created (from the AI logs)
- Digital source data, including:
- Raw search results (source links)
- AI model within ELM that created the response
- Transformation processing data, including;
- Search mechanisms that produced raw search results
- AI prompt used to create the conversational response
Mapping user interaction patterns guided my decisions to display provenance data
To decide how to display the provenance data about the AI response, I referred to my previous research observing students using the AI searchbot. I mapped out their needs and expectations at each stage of the interaction, and referred to levels of data disclosure described in the C2PA standard to work out what provenance data to display and when.
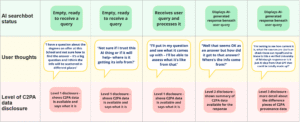
Screenshot of user journey map showing the stages of interaction with the AI searchbot, the user sentiment, searchbot displays and the levels of C2PA provenance data displayed at each interaction stage.
To begin, the user is shown that provenance data is available
At the initial stage of the interaction, the user types in a query to the AI searchbot, and expects a response to be returned. Depending on their previous experience of AI, they may be skeptical about the quality of the response they will receive. I reasoned that a ‘level 1’ C2PA disclosure – typically denoted by the C2PA Content Credentials icon – could be appropriate – as this would show them that some verification was available. If the icon was accompanied by some text which could be expanded for more detail, this would enable the user the option to learn more if they were curious to understand what a Content Credential is.
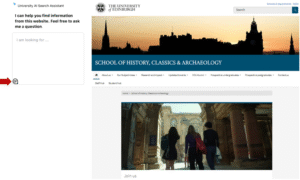
Screenshot showing the AI searchbot displaying the Content Credential logo to indicate provenance data is available
When the AI searchbot response is generated, the user is shown that the content comes with provenance
Once the user has typed a query and received an AI-generated response, (formed from the search results as part of the search and indexing process), they are in a position where they will want to assess the quality of the response, to judge whether it answered their question and whether they can trust it. I felt that C2PA disclosure at level 1 (the same as in the initial stage of the interaction) would be relevant at this stage, to show the user that there was provenance data available to accompany the synthetic content in the AI searchbot.
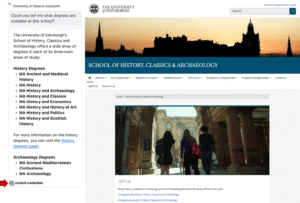
Screenshot showing AI searchbot with a response and associated Content Credential logo to indicate provenance data
When the user expands the Content Credentials they see the categories of provenance data available and can choose to expand these
I thought that some users would be satisfied knowing provenance data was available for the AI response – this would be enough for them to make decisions on whether to trust the content or not, and accordingly, decide how to use it. Other users may want to know more specific details of the content provenance before deciding how to proceed with it. To cater for users with this need, I included labels of the different categories of provenance data to indicate what was available, so the user could choose to expand one or more of them to find out more details. I labelled the categories of data ‘Content certification data’, ‘Digital source data’ and ‘Transformation processing data’ based on my earlier analysis of what was included in the Content Credentials record. Referring back to the C2PA guidance, this design was classed as level 2 C2PA disclosure when the expandable sections were closed, and level 3 C2PA disclosure when they were expanded to reveal the full extent of the provenance data.
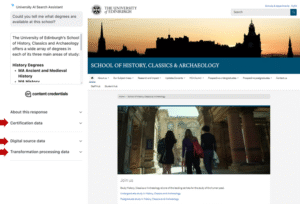
Screenshot to show the interface of the AI searchbot with the different categories of provenance data available
Screenshot showing the AI searchbot interface showing all the provenance data available (with the categories expanded)
I reflected on the process of designing transparency into AI features
Taking part in the study was insightful from various perspectives. I found it useful to refer to what I learned from earlier research to put myself in the position of someone interacting with the AI searchbot and to consider how they would decide whether to trust the content in its responses. Added to this, the design challenge and thinking about how the the provenance data could be consumed along with the content itself prompted me to think about a future of designing machine-readable content.
I found it useful to unpick how the AI response was formed to affirm its provenance
Before I could design how to display the provenance data for the AI-generated response, I needed to work out the steps in the synthesis process. Having been involved in the development of the AI searchbot, I had an understanding of the various parts, but before feeling confident to describe this in terms to match the C2PA requirements I reconnected with the Drupal AI experts who constructed it, to check I had things correct. This was a useful exercise as it prompted me to think about which signs would indicate that parts of the process had occurred successfully, and similarly which indicators would flag if parts of the process had failed, and how the provenance data would change as a result.
It was difficult to know which provenance data to display – how much was too much?
With the process clear in my own head, I found it a challenge to know where to start with describing it in a way that could be meaningful to anyone who used the AI searchbot. On one hand I wanted to make the information as easy to understand as possible, but on the other I wanted to be completely transparent about the process as the C2PA specification required. I was conscious that every piece of provenance information I included gave the user more to read and parse, and that there was a balance to strike to avoid overwhelm. Thinking about the data in different categories (certification data, source data, processing/transformation data) helped me work out what to include and how to present it.
In the Digital source data I opted for an overarching sentence to explain where the response came from, which read: ‘AI generated textual answer from content indexed from hca.ed.ac.uk website in response to typed user query’. Thinking about what the users sought in the response I included the links to the source pages. I felt it was relevant to include the model that generated the response as this could be meaningful to users familiar with competencies and reviews of different AI models.
In the Transformation processing data I opted not to go into great detail about the specific steps involved to create the response. Instead, I chose to include an overview of the AI-powered search, which read: ‘Website content indexed by Drupal Search Module for keyword matching. Embeddings created from web content with Milvus vector database for semantic matching’. I was conscious that the style of the response depended on the back-end prompt of the AI searchbot, so I also included the prompt within the processing data (which read: ‘You are a chatbot that can answer questions about the University of Edinburgh History Classics and Archaeology School. Only ever answer questions with content from this website. DO NOT have opinions about things that the user asks for. DO NOT use your own knowledge to provide information, just the context you are given, If the context that you are given does not answer the user, just answer with ‘I am sorry, I do not know that, would you like to ask something else?’.)
I would like to test my designs and experiment with different user interface patterns to display the data
User testing would be a sure-fire way to establish whether my designs made sense to people using the AI searchbot. Assumptions to focus on in a round of testing would include:
- if they cared about seeing provenance data about the AI response
- if they grasped the concept of provenance data
- if people understood what the C2PA Content Credentials icon signified
- if the names for the different categories of data made sense to them
Testing would also establish if the user interface pattern I had chosen resulted in overwhelm. I wanted the provenance data to be positioned in proximity to the AI response, but given the narrow window of the searchbot, it was a lot of textual data (especially at the C2PA disclosure level 3) to cram into a small space which felt like it would overwhelm the user. To counter this, I would like to explore other patterns to use to display textual data that might be easier for users to cope with.
I was aware that the provenance data may not be read by humans, instead parsed by machines
Thinking about the way people increasingly consume content, I reflected that my goal to display the data in a user-centred interface could be misguided. There could be a scenario where a person typed a query into the AI searchbot and then made sense of the response through automated means (for example an AI summary or an agent) without even looking at the original source of the content. In this case they might get the points of the AI summary combined with the provenance data in a separate piece of AI-generated content. Would that need provenance data as well? I considered a provocation from the book ‘Machine customers: The evolution has begun. How AI that buys is changing everything’:
We need to be designing for how the technology wants to work, rather than forcing it into patterns built for fingers and eyeballs – Katya Forbes
This kind of thinking seemed too meta for the design task in the study, but perhaps something that would become a reality in the not-too-distant future.