
Integrating ELM with EdWeb – Building an AI tool for publishers

Throughout my internship, I’ve had the chance to meet many different publishers from across the University and through all kinds of interactions – whether in user interviews, unconferences, user testing, or just in daily life. It’s been incredibly insightful for me to learn how publishers work, the processes they follow, and the pain points they encounter in their work. In fact, I’ve drawn directly on these insights to redesign both the user interface and functionality of the style guide checker I developed in EdWeb, making it more user-centered and focused on common style mistakes. However, publishers are now facing another growing challenge: how to effectively use AI.
AI can help publishers with content editing but they face issues with it
There are a growing number of AI-powered tools to help with writing for the web and content authoring. Many publishers have tried using AI tools to help with brainstorming ideas or improving their writing, but they often keep running into a few persistent issues:
- AI tools hallucinate
- They change the writer’s style
- They often give only surface-level feedback unless the prompt is very carefully thought out
These problems cause publishers to lose trust in the tool, which usually means they don’t prompt it further. Still, some publishers have managed to get more value out of AI by really nailing down the best prompts for some use cases (like checking against the style guide). There’s even an AI Adoption Hub where publishers share good prompts they’ve found helpful.
But, rather than forcing a general language model to handle specialised tasks, why not design an LLM made for publishers?
These types of problems really excite me! Because there is no one answer, you get to explore, research, design, prototype and test ideas for how to best solve the user problem!
Before I started anything, I really wanted to understand what a good AI tool for publishers would need to have (at least my hypothesis about this). I made a small list of key attributes:
- A simple, non-intrusive user interface
- The ability to understand web content from different perspectives (e.g., style, design, audience)
- Meaningful suggestions rather than surface-level feedback
- Trustworthiness
Building the first prototype
Almost all publishers use EdWeb (the university’s content management system) to publish content to the public. So why not build the AI tool right where publishers already do their publishing?
Many AI tools use a sticky button that opens a chat bar, like this:
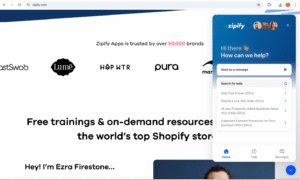
Screenshot of the Zipify website showing the chat interface
But this design isn’t ideal, especially for publishers, as it can feel “intrusive” and doesn’t sit well with the Drupal Gin theme used in EdWeb. So I started experimenting with other approaches. The Gin theme already has a button that opens a revision details sidebar. Why not place a chat button right next to it? That way publishers could easily switch between the two sidebars.
For the MVP, I focused on the most essential components of the chat interface:
- Text area
- Send message
- Box where messages appear
- New chat
- Close
I made sure the sidebar chat followed EdWeb’s existing design patterns so it blended in seamlessly.
Building the backend functionality
With a working prototype of the interface in place, I began building the functionality that powers the chat. The University has its own collection of LLMs (ELM) so it made sense to implement my design ideas using this.
Details about ELM, the University’s LLLM
I made sure to use an ELM API key to ensure that I accessed the LLM models securely.
For my first prototype, the backend looked something like this.

As you can see, it’s very simple. I pass the user’s page content to the LLM, along with a custom system prompt I designed specifically for publishers (more about this later).
Getting the page content
Initially, I had a very roundabout way of getting the page content. It looked like this:

Using an LLM to get the content only really makes sense if you don’t know the structure of the page. But in EdWeb, the structure of an edit content page rarely changes, which makes the LLM approach overkill.
So, I made a faster and more reliable function which recursively extracted the page content and relevant fields.
A “publisher-centred” system prompt?
I wanted the system prompt to focus on a few important things (each of which are hypotheses about how the LLM should output).
- Things it should NOT do:
- Change the writer’s style/tone
- Things it should do
- understand the audience of the content, their top tasks to ensure suggestions are meaningful and not surface-level
- quote specific sections of text when giving suggestions and give a rationale
- Best practices for:
- writing content
- structuring content (using EdWeb components)
- Check against common style guide mistakes (e.g., inline links, headings format)
I used my interactions with publishers throughout my internship to inform the design of the system prompt. I made sure to include both what they want to see the LLM output and what they need to see (content design advice, style checks).
However, as I refined the system prompt to include more specifics, I realised a huge problem with this approach.
LLMs can only handle so much information
Like us, LLMs have “memory” – referred to as a context window. If you fill the system prompt with too many instructions, context, guidance, the LLM will ‘forget’ important pieces of information and, as a result, produce a disjointed response. So, using one LLM can only allow for so much functionality.
This made me think:
What if I had more LLMs?
After doing research, I learnt that there is an entire field about this called Agentic AI.
What is an AI agent?
An agent is an LLM with access to tools. It uses its tools based on feedback from its environment. Agents do this in an iterative process, usually with a stopping condition that stops the loop.
It is important to distinguish between Agents and LLM workflows.
An LLM workflow is a predefined code path for LLMs and tools to follow. This contrasts with the Agent’s ability to direct the use of its tools.
Exploring research in Agentic AI
I began to explore this field which seemed fascinating to me. I did a lot of research, and read a widely referenced article by Anthropic called Building effective agents. It was so interesting to learn about the different design patterns, their benefits, limitations and best use-cases.
I also read some research about techniques to improve the responses of LLMs. I learnt about a Prompting Technique called ReAct which can generate both reasoning and action-based tasks.
- One key benefit of ReAct is reducing hallucination – a crucial objective for my AI tool.
- Using ReAct can also help increase publishers’ trust in the tool as it can allow them to see what the LLM is ‘thinking’ and where it is getting its resources.
I also learnt about a relatively simple technique to improve an LLM’s response called Self-Refine. Essentially, an LLM generates an output, provides feedback for the output, and uses this to refine itself – in an iterative process (until a stopping condition is met).
I wanted to learn as much as I could before starting to think about how I might design an Agentic AI system for a publishing assistant. One crucial thing for me was to ensure my system consisted of “simple, composable patterns” instead of a “complex framework” (as Anthropic recommends).
How do I implement AI agents in EdWeb?
There is a module called AI Agents in Drupal (the framework that powers EdWeb) which I can use to build AI agents and integrate with the Drupal AI module.
I spent some time reading through the documentation for AI agents. I learnt about different multi-agent orchestrations patterns such as Project Managers and Hand Offs. It was fascinating to me the different designs that I could have for the system.
Refining my hypotheses about how publishers could use the tool
Now that I had a better sense of AI Agents and the functionality I wanted to develop, I decided to refine my hypotheses. I planned to test these assumptions through user testing once I’ve developed a prototype.
My hypotheses:
- Publishers would want to use LLMs for:
-
- Improving content writing
- Improving page layout/structure
- Checking content against the University style guide
- Helping ensure content meets audience needs and top tasks
- Helping maintain their web estate
- Publishers would prefer using an AI tool in EdWeb rather than in another website
- Publishers would trust the AI more as it exclusively uses resources from the University to generate its responses
Designing an AI Agent system
I decided to experiment with a project manager orchestration. My idea for the flow of the system was something like this.
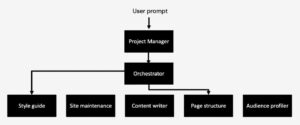
The prompt goes to the project manager which produces a detailed plan and sends it to the orchestrator. The orchestrator delegates different tasks to several specialised agents and collates the response which the project manager evaluates against its criteria before responding to the user.
After doing some testing, I noticed an issue with this design: overplanning.
- A lot of simple tasks such as “check this page against the style guide” where only one agent would be needed, turned into a multi-agent task. Although this can be useful; it resulted in a response that didn’t answer the user’s original query, instead providing a lot of suggestions across each agent’s area of expertise.
Although there are other possible reasons for this issue (such as imprecise system prompting), I decided to reduce the level of complexity and create a base design which can be expanded as the prototype becomes functional. Therefore, I iterated for a simpler design.
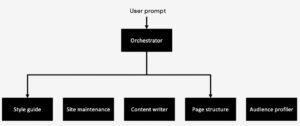 Now that I had a base design for the agent orchestration, I started thinking about the different tools that each agent would need to have.
Now that I had a base design for the agent orchestration, I started thinking about the different tools that each agent would need to have.
Developing powerful tools for AI agents
Tools are what agents use to get information – this is where I can ensure their responses come from reliable university sources.
Each specialised agent has a unique goal. As a result, they each need a unique toolset.
It’s important to really think about the design of the tool:
- tool input format
- how should the agent use the tool? when? – how can I achieve this in the system prompts?
- are there any edge cases? how should the agent behave then?
Thinking about these kinds of questions is crucial to create effective interactions between agents and their computer resources (also referred to as the agent-computer interface).
So far, I have already made one tool – that gets the content of user’s page.
What tools could help specialised agents provide meaningful responses?
I laid out some ideas of useful tools for each agent:
- style guide agent
- search editorial style guide
- get university acronyms
- site maintenance agent
- search the content of the entire site using RAG
- find outdated content
- understand the site structure
- content writer agent
- access to content writing best practice
- page structure agent
- access to best practice for using different CMS components
- audience profiler agent
- getting url path to the page
Some tools were easier to develop than others. For instance, to “understand the site structure”, I developed a “get site map” tool which allows the agent to retrieve the site map of the user’s site, choose maximum depth and whether to include details such as taxonomy and menus.
I’ll briefly explain some of the more complicated tools that I developed.
A tool that accesses the University’s Editorial Style Guide
There are two versions of the University style guide (as of now): a web and pdf version. Each version has some overlapping rules, but also some unique rules. My aim was to make a tool that can access and search all the guidelines and rules.
University of Edinburgh Editorial Style Guide
More specifically, I wanted to develop a JSON file of all the rules – with each rule having the following key attributes:
- title
- section (e.g. formatting)
- summary
- dos
- don’ts
- examples
- good
- bad
AI is very good at doing repetitive tasks – so, I prepared a detailed prompt with all the rules attached in documents. By repetitively going through each rule, and parsing it to the format I specified, it was able to create a very detailed JSON file of all the style guide rules. I used this to create the “search style guide” tool.
I also wanted to design the input mechanism for the tool. A simple way of doing this is having different operations for the agent to choose from:
- search (keyword search for rules)
- section (get rules by section)
- list sections (get all sections)
- search by rule id
The agent can select the most suitable operation based on the user’s prompt. It can then generate a search query to find relevant guidelines from the style guide.
A tool that searches the user’s site using RAG
RAG stands for Retrieval Augmented Generation. Essentially, instead of keyword search, using RAG allows you to search based on semantic meaning. So, for example, if I search “application advice” in a RAG tool with access to the Careers site, it will return relevant advice for different stages in a job application, like “Writing your CV” and “Interview tips”.
The following diagram shows the stages in a RAG pipeline (from this medium article).

To implement RAG in Drupal, I used the AI search module along with the Search API module. I set up a Milvus database server locally to store the vector database and connected it by doing some configuration for the Search API. I used cosine similarity to compare the vectors in the database – this helps compare content across semantic meaning rather than literal vocab – although there are other metrics to possibly experiment with.
I was able to get the tool running locally and use it to search for content across a demo site!
However, to get the tool functional on my Pantheon sandbox site (which I used for user testing), I used Pantheon Search which uses Solr. Solr doesn’t have semantic search capabilities, but it was the fastest way to get the tool up and running for user testing. One immediate next step is to use the Solr Dense Vector Field module to integrate semantic search and vector similarity capabilities with Solr.
Tools for acronyms and content best practice
I followed similar steps to implement the “get content best practice” and “get university acronyms” tools as I did for the “search style guide” tool.
I used the Elements Guidance document – which has detailed advice for each CMS component in EdWeb (along some content writing best practice) – to develop the content best practice tool. Similarly, I used a very long University acronyms Excel sheet to develop a detailed JSON file of all university acronyms that the “get university acronyms tool” can use. This ensures that the agents use reliable university resources when they give advice to publishers – helping to increase their trust.
University of Edinburgh acronym spreadsheet
Second prototype for AI agent system design
The following diagram illustrates the agent design for my second prototype.
 As you can see, there are many improvements that can still be made to the design.
As you can see, there are many improvements that can still be made to the design.
For instance, each agent has a “get page content” tool – this is redundant and causes slow performances, as each agents needs to get the user’s page content. A better way to do it may be to run the get page content once and pass the content to each agent that’s called; however, if the content is a very large number of tokens, the page content could stretch the context window of the LLM and lead to poor responses. Ultimately, I would need to do more research and finding of better methods and optimisation strategies to improve my initial design.
To ensure you understand the system, here is an example of a chat-response flow.
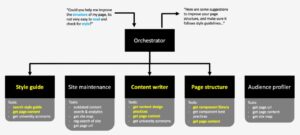
Here is another example. The images are taken using AI agent explorer feature. Notice how you can see the orchestrator prompting the site maintenance agent and how that agent uses their unique tools to generate a response.

However, you can also see some issues. For instance, searching the vector database with the query “duplicated content” is not useful – as that would only allow the agent to find pages that talk about duplicated content, not actually duplicated pages. A better design would have a more accurate tool that searches across the vector database for pages with very similar cosine similarity scores – this would indicate that they likely talk about similar content – and therefore, more likely to be duplicated pages.
Regardless of this issue, the site maintenance agent based its response on information gathered from the “get site map” tool rather than the rag search tool. This allows it to provide a more accurate response as the URL paths of pages in a site are a good indicator of possibly duplicated content – as you can see in its response (shown in the following image).

Insights from user testing with publishers
As I mentioned earlier, I developed the prototype based on several hypotheses. So, I wanted to test these by doing user tests! The tasks in the test focused mainly on the functional aspects of the hypothesis and how participants found the AI tool’s responses.
Reviewing my hypotheses
I hypothesised that publishers would want to use the tool to help them improve the structural layout of their content and check against style guide. So far, participants found the tool helpful in providing ideas about better structural arrangements for their content – especially with regards to improving headings, breaking chunks of text to bullet points, and suggesting good link text. Participants also found it helpful for ideating different structural arrangements for different content audiences, but the tool needs refinement in this area to make sure it understands the user’s goal exactly as otherwise it can give vague responses. This could be achieved by allowing the LLM to ask further questions to the user when it’s uncertain about the content’s audience. This would help ensure its output is more meaningful for publishers.
Importantly, participants said they wouldn’t use the output directly but adapt it and improve it with their own edits. This appropriately meets my hypothesis – I designed the tool to be a well-informed assistant – not an editor.
I also wanted to share some other insights I learned from user testing.
Publishers prompt the AI tool in different ways
It was very insightful to learn about different ways people prompt the LLM and how this impacts its response. For instance, some users prompted the tool using keywords – like when you use Google search. Others gave the LLM a chunk of text from the page along with a task – not recognising that the toggle button that enables and disables reading of page content.
This prompts the large question of designing the input mechanism for the AI tool. Would a pre-prompting approach (like the Ask EdHelp chatbot) help? Or perhaps, a few tweaks with the user interface to highlight what the AI tool’s features?
Publishers didn’t know where the AI is getting its resources
I designed agents with tools that use several reliable university resources; however, that wasn’t clear to the user. The only possible indicator for the sources was the “Reading (page-title)” text in the loading animation. This prompted me to ask, what changes I could make to show users the resources that the AI tool is using?
One simple change which could work effectively is just adding the line “include what percentage of your answer comes from the RAG/tools and from your knowledge” to the system prompt of the agent. This was used in this demo (on Brainsum) to output “Source: (number)% from RAG” at the end of the AI’s response.
However, a better and more accurate approach may be to add references after paragraphs in the AI’s response – like how web search works in ChatGPT and Perplexity AI.
This is just version 2
There are so many ways that the current prototype can be improved, as I’ve been discussing in previous sections. One crucial area for improvement is the system prompt (agent instructions):
We need to decide and design how the AI should talk with users
This is what system prompts are for. If the AI is behaving in a way you don’t want, change the system prompt. Prompt engineering is an entire field, so it’s important to craft the system prompts for the agents as they impact several aspects of the response, like:
- the output format
- which tools the agents use and when
- what they do and mustn’t do
One prompting technique that’s worth exploring is ReAct as it can help inform publishers about the AI’s sources while also reducing hallucination. This is a great next step to improve several areas of feedback which came out from user testing.
More areas of improvement
Currently, I developed a simple modular design which can be expanded; however, there are many other orchestration designs which I haven’t explored such as Hand Offs and Nested Calls orchestration – so it is worth trying out better designs while keeping in mind best practices when designing Agentic AI systems.
You could also improve and refine the tools I developed – I’ve discussed some problems with tools like the rag search tool for duplicated content. Trying to implement and test new solutions is a useful next step! Or even make new tools if a different type of information is needed for the agents to respond more accurately and meaningfully.
The future for ELM in EdWeb
Helping publishers write content that better meets their audience needs is so important – especially for those with publishing access, but limited content editing experience! This is what motivated me to research, experiment and try new ways of tackling the issues publishers currently face with AI. I’m really excited for more improvements, refinements and user testing to ensure we create a tool that helps publishers in their daily lives.
This is a great article, very impressive what you were able to build with open source tools.