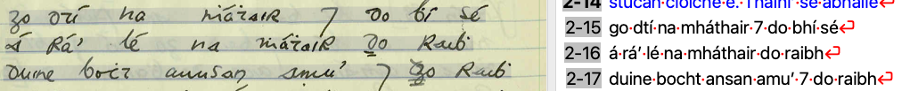Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
Illustration by John D. Batten in English Fairy Tales, London: David Nutt, 1890.
English Fairy Tales by Joseph Jacobs includes many tales that are familiar to most of us, and several that I have come across in my digitization work on the Tale Archive here at the School of Scottish Studies Archives. Some of these stories I remember coming across include Tom Thumb, The Red Etin, and Nix, Nought, Nothing which I mentioned in my last blog post about the Mi’kmaq Tale. One tale that I came across whilst working on the ATU 400 tales is ‘The Well of the World’s End’ on p. 215 of English Fairy Tales. The tale is an interesting combination of what most of us would know as Cinderella and The Princess and the Frog – although it’s not quite as child-friendly for our modern times, as the frog turns into a prince not with an innocent kiss, but with the chopping off of his head!
You may be wondering why I chose to discuss a tale from English Fairy Tales, as it doesn’t seem to be about what the Decoding Hidden Heritages Project is all about: Gaelic Narratives. However, Jacobs cites one of his sources for the tale of ‘The Well of the World’s End’ as: “[John] Leyden’s edition of the Complaynt of Scotland, p. 234…” (1801). He goes on further to mention ‘parallels’ of the tale:
In Scotland it is Chambers’s tale of The Paddo, p.87; Leyden supposes it is referred to in the Complaynt (c. 1548), as “The Wolf of the Worldis End.” The well of this name occurs also in the Scotch version of the “Three Heads of the Well”.
The Popular Rhymes of Scotland(1870), compiled by Robert Chambers, is a publication that comes up frequently in the Tale Archive here, and the Complaynt of Scotland is a book with a fascinating history that I highly recommend looking further in to if you haven’t come across it before.
I was initially drawn to the tale of ‘The Well of the World’s End’, and the entire publication, because of its wonderful illustrations, but the tale reveals a much more interesting story than what appears on the surface, and is worth a deeper dive (pun intended?) if you have the time. The links I’ve included in this post provide plenty of interesting reading material!
I’ve also included the front page from English Fairy Tales below, as it provides a snapshot of the wonders that can be found in its pages…
Sources
Leyden, John, James Inglis, David Lindsay, and Robert Wedderburn. The complaynt of Scotland: written in 1548. With a preliminary dissertation and glossary. Edinburgh: Printed for Archibald Constable. And sold by T. Cadell junior, and W. Davies, London, 1801.
Jacobs, Joseph, and Batten, John D. English Fairy Tales. London: David Nutt, 1890.
(English Synopsis: Mermaids and selkies are a recurring theme in Gaelic stories but especially in the age of #MeToo, many of these stories jar somewhat and are perhaps due for a critical re-evaluation. As a thought experiment, I decided to see what would happen if I re-told a selkie story and swapped the genders. As it turns out, it’s surprisingly difficult and leaves you with a story that makes you wonder about our perceived gender roles.
Bha ban-tuathanaich ann bho chionn fhada agus bha i a’ falbh air a’ chladach latha agus chunnaic i seachd ròin a’ tighinn gu cladach. Chaidh i am falach agus chunnaic i iad a’ tighinn gu tìr is a’ cur dhiubh nan cochall-èisg aca. Dè bh’ annta ach fir-mhara bhrèagha. Nuair a dh’fhalbh iad ’gan nighe fèin sa mhuir, chaidh i ann is ghoid i leatha an aon a bu mhotha dhe na cochaill is chuir i am falach e. Nuair a thàinig na fir-mhara air ais a dh’ionnsaigh nan cochall aca, fhuair gach aon dhiubh a chochall fhèin ach am fear a bu mhotha dhiubh. Lorg e a chochall fhèin gus an robh e sgìth. Dh’fhalbh càch a-mach air a’ chuan is dh’fhuirich esan leis fhèin ’s e a’ caoineadh ’s a’ caoidh, na shuidhe air aon dhe na clachan air a’ chladach ’s e rùisgte. Thàinig i far an robh e ’s chuir i cleòca mu thimcheall agus thug i leis dhachaigh e. Fhuair i aodach dha ’s dh’ionnsaich e obair a dhèanamh ’s bha e glè ghnìomhach. Phòs i e agus dh’fhàs i trom aige.
Thud, carson a phòsainn mèirleach mar thusa?
Fada na dhèidh sin, an àm an earraich, bha i a-muigh a’ treabhadh agus bha an duine aice a-muigh a’ coimhead mun cuair air gnothaichean agus nuair a thàinig e a-steach, thuirt e ri mhac, “Nach iongnadh leat nach eil do mhàthair a’ cur mu dhèidhinn a’ mhulain-arbhair sin a bhualadh is feum aice air sìol gu goirid?” Agus thuirt a mhac, “Tha rud bòidheach aig mo mhàthair ’ga glèidheadh sa mhulan sin is chan fhaca mi riamh rud cho bòidheach ris.” Agus dh’fhaighnich esan gu dè an cruth a bh’ air is dè an dath a bh’ air. Agus dh’innis am balach an cruth mar a b’ fheàrr a b’ urrainn dha is gun robh dath uaine air. Chaidh esan dhan ghàrradh far an robh am mulan agus sgap e e às a chèile. Ruith am balach is dh’innis e dha màthair mar a thachair is thàinig i gu luath a dh’fhaicinn an duine aice mu ’m fàgadh e i. Ach bha an cochall-èisg air mun dàinig i. Dh’iarr i air fuireach leatha ach chan fhuiricheadh.
Tha maighdeannan-mara a’ nochdadh gu math tric ann an sgeulachdan Gàidhlig, eadar maighdeannan-ròin is maighdeannan-mara agus tha iad cumanta cuideachd ann an dùthchannan eile eadar Inis Tìle ’s Lochlann. Ged nach robh maighdean-ròin sna sgeulachdan a bha romhan sa phròiseact seo, tha iomadh maighdean-mhara air nochdadh, can ann an Iain Mac an Iasgair.
Feumaidh mi aideachadh gu bheil mi car amharasach mu na sgeulachdan seo an-diugh, ged a bha mi gu math dèidheil orra nuair a bha mi òg. Gu sònraichte ann an linn na h-iomairt #MeToo, tha iad a’ fàgail blas car searbh ’nam bheul oir aig a’ cheann thall, chan eil annta ach sgeulachdan èigneachadh bhoireannach agus cha chreid mi gun innsinn iad dha mo chlann fhìn nam biodh clann agam. Chan ann san dreach tradaiseanta co-dhiù.
Cha robh a leithid ann nuair a leugh mo sheanmhair na sgeulachdan seo dhomh ach chuala mi gu bheil diofar dhaoine air na sgeulachdan tradaiseanta seo ath-innse air dòigh a tha nas cothromaiche, can na Gender-swapped Fairly Tales. Chan e eòlaiche sgeulachdan a th’ annam agus is mathaid gun deach seo a dheasbad am measg nan eòlaichean mu thràth ach bhuail e orm gum biodh e inntinneach an aon rud fheuchainn. Sgeulachd na maighdinn-mara, boireannach an àite an fhireannaich is a chaochladh, dìreach mar dheuchainn.
Tha an sgeulachd gu h-àrd ann am More West Highland Tales agus rinn mi dìreach sin. Agus abair iongnadh a bh’ orm nuair a mhothaich mi dè cho doirbh ’s a bha sin. Tha an toiseach ag obair ceart gu leòr ach tha rudan a’ fàs car neònach an uair sin. Gabhaidh a chreidsinn fhathast gun rachadh boireannach am falach is sia fireannaich a’ nochdadh air a’ chladach às a’ mhuir. Ach an uair sin a’ goid a’ chochaill is a’ sparradh air fireannach a pòsadh agus an uair sin clann a bhith aca? Tha e a’ fàgail na sgeulachd air fad car do-chreidsinneach ma chuireas sinn boireannach an àite fireannaich is a chaochladh agus tha sin sin, saoilidh mi, a’ togail ceistean mòra a thaobh cò a’ ghnè aig a tha làmh an uachdar ann an seann sgeulachdan agus am bu chòir dhuinn an innse do chlann an-diugh mar a bha iad o shean.
One of the best things about having worked in The School of Scottish Studies Archives & Library for the past five years is seeing how people are connected with the archive recordings here.
I don’t only mean seeing how our readers are affected by connecting their own research to the myriad depths and layers of oral record testimony – though that process is rather like watching someone discovering treasure every single time. Once the Decoding Hidden Heritages project reaches its culmination, the transcript material from the Tale Archive will be another important layer to these recordings, and available for all to discover.
I also refer to the connections than extend outside the archives.
Angus MacNeil of Smirasary, Glenuig, being interviewed by Calum Maclean (out of image) 1959 Image copyright: SSSA
Many of the people who were recorded in the first decades of the School of Scottish Studies are no longer alive, but their material lives on in those who have connections to the people, their native area, or work or traditions. For example. Shetland fiddle players come to the collections to learn the playing style of the isles; Gaelic singers have used the archive to learn a regional variation of a song for performance; local heritage groups using material recorded in their location for museum exhibitions; storytellers learning tales…and the Carrying Stream flows on.
For me, these connections are particularly palpable when tied to family and we have great links with relations of some of our contributors and fieldworkers. Some can fill in details for us, such as other family members who were recorded or give background information that adds more depth. Often they give permission for re-use of material, if the archive do not hold the rights. Sometimes people come to us looking for recordings their relatives made and at other times we are connected with people who did not know their relation was recorded at all. In all of these instances those connections between contributor, recording, family and us, as the archive, are further strengthened and emboldened.
For those who read my previous blog on seeking the unknown person in the collections – I have an update! A former colleague (connections, again!) sent the post on to her friend from Glenuig who may have known my two unknown women of Smirasary – “You never know, he might have an idea who they are?”
Within a few hours I had a response – not only did he know who they were, but one of the women was his grandmother. The woman that was down in our records as “Anon Woman B / Mrs MacDonald?” was indeed a Mrs MacDonald. She was Johanna MacDonald (1880-1973) and there is more material in the Archives attributed to her from other fieldwork trips to Smirasary in the mid-late 1950s. You can hear some of those other recordings on Tobar an Dualchais. Another fantastic set of connections and one which will hopefully lead to these transcriptions becoming more accessible.
I never fail to be surprised at the connections people have to The School of Scottish Studies Archives, or the weight and strength of those connections!
There are 28 versions of Aarne–Thompson–Uther (ATU) Index tale type 313 at the School of Scottish Studies Archives, but this particular one stands out. It is a tale told by Isabel Morris Googoo from the Mi’kmaq (or Micmac) tribe in Whycocomagh, Nova Scotia, to folklorist Elsie Clews Parsons in 1923. It was originally published in the Journal of American Folklore in 1925, but the copy we have on file is from a 1986 edition of the Cape Breton Magazine, with added illustrations of Mi’kmaq petroglyphs from a publication by the Nova Scotia Museum. The article notes that “it is an example of elements of European stories and religion that have been worked into Micmac tradition.” In this part of Canada, this European influence would have come more specifically from Scottish and French settlers, although this tale type has variations that can be found across the globe. It even has ties to Ancient Greek mythology. In Scots, it is best known as Nicht, Nought, Nothingcollected by Andrew Lang from “an aged old lady in Morayshire” (In Lang’s words). Unfortunately, the lady is not named as is too often the case with female narrators, and actually what makes the Mi’kmaq Magic Flight story so interesting is that it was told and collected by women, and they are specifically named. In the Journal of American Folklore article, we are even given the names of the source of the story: Googoo’s grandmother, Mary Doucet Newell. The collector, Elsie Clews Parsons, was one of the earliest figures for the feminist movement and was outspoken on the negative effects of gender role expectations, publishing works on the topic in the early 20th century.
An Irish version of the Magic Flight tale, also collected by a woman, can be read on the Duchas website here.
The Mi’kmaq Magic Flight tale from the Cape Breton Magazine is attached here in its entirety. Note the adverts, providing a wonderful glimpse into the social history of 1980’s Nova Scotia!
Parsons, Elsie Clews. “Micmac Folklore.” The Journal of American Folklore 38, no. 147 (1925): 55–133. https://doi.org/10.2307/534961. *Warning: this article contains some offensive language*
Peverill, L.., Robertson, M.. Rock Drawings of the Micmac Indians. Petroglyphs. N.p.: n.p., 1973.
(English Synopsis: Musings about what the words fith fath fuathagaich /fi fa fuəgɪç/ which are spoken by giants in certain tales such as Gille an Fheadain Duibh ‘The Lad of the Black Whistle’ could mean and whether there might possible be a link to the fee-fi-fo-fum from Jack and the Beanstalk.)
Ann an seann-sgeulachdan, tachraidh e gu math tric gun nochd facal, abairt no gnàthas-cainnte annasach. Ach chan iongnadh mòr sin: b’ i a’ Ghàidhlig a’ chiad chànan aig an fheadhainn a dh’innis na sgeulaichean ud. Bhiodh iad a’ toirt dealbh air an t-saoghal ann an Gàidhlig sa chiad dol a-mach, agus bha Gàidhlig èasgaidh shùbailte shiùbhlach aca a tha a leithid mar rionnagan san oidhche fhrasaich an-diugh. Ach leis gun dàinig na sgeulachdan seo a-nuas thuca o ghinealach gu ginealach, uaireannan nochdaidh rud-eigin annta air a bheil coltas fìor-aosta agus nach eil furasta ri thuigsinn idir.
Tha sgeulachd ann a nochdas ann an diofar cruthan ach aig cridhe na sgeulachd tha balach òg a nì sabaid an aghaidh trì fuamhairean agus am màthair. Fhuair am balach obair buachailleachd aig cailleach ann am baile air chor-eigin agus bidh e a’ falbh le gobhair na caillich. Ged a thoirmisg a’ chailleach dha falbh rathad nam fuaimhairean, sin a nì e. Agus nuair a ruigeas e an gàrradh a tha mun cuairt air taigh a’ chiad fhuamhaire, cuiridh e toll ann agus leigidh am balach na gobhair a-steach. Bidh am balach crosta seo (an-dà, tha e dìreach air dochann a dhèanamh air gàrradh fuamhaire bochd agus na gobhair ag ithe a’ bharra aige a-nis!) an uair sin a’ sreap suas craobh agus a’ cluich fhìdeag ann. Thig an uairsin fuamhair ’s e airson facal modhail fhaighinn air mac an ànraidh seo shuas sa chraobh agus bidh rann àraidh aig an fhuamhair ’s e a’ tighinn:
Air fith fath fuathagaich¹ air barraibh an albhagaich,²
’S fhada bha mo chorp air feadh ga meirgeadh ’s tolladh
a’ feitheamh air greim dhe d’ fheòil is
balgam dhe d’ fhuil, a mhic an Albannaich.³
¹ no fuagaich/fuamhaich
² no almhagaich/all(a)mharaich agus fiù air baile nan Albannaich uaireannan
³ no rìgh
Nise, tha an dàrna, treas is ceathramh sreath furasta gu leòr ri thuigsinn, fuilteach ’s gu bheil iad. Ach bha a’ chiad sreath a-riamh a’ cur iongnadh orm. Dè th’ ann an albhaga(i)ch? Agus dè dìreach a tha air fith fath fuathagaich a’ ciallachadh? Feumaidh mi aideachadh nach eil fhios a’m, ged a tha nàdar de dh’amharas agam. (Ma tha sibh airson èisteachd ris, seo aon dhe na clàraidhean aig Sgoil Eòlais na h-Alba. Tha am fith fath fuathagaich a’ nochdadh san dàrna clàradh, ’s dòcha dà mhionaid an dèidh toiseach a’ chlàraidh.)
A’s a’ chiad dol a-mach, saoilidh mi gu bheil baile nan Albannaich dìreach na mhearachd is an sgeulaiche a’ dol car iomrall (no fiù an neach a rinn an tar-sgrìobhadh, chan eil na clàraidhean cho soilleir uaireannan). Ged nach eil mi cinnteach idir mun albhagaich, leis gu bheil gach tionndadh dhen sgeulachd ag innse gun do shreap e suas craobh, chanainn gu bheil air barraibh (< bàrr + -aibh) ag innse gu bheil e na shuidhe air rudeigin, ge be dè th’ ann an albhagaich. Tha albhagaich a’ toirt ailbh(eag) “creag” nam inntinn ach carson a bhiodh e air creag is e dìreach air craobh a shreap?
Ach co-dhiù, ’s e a’ chiad phàirt a tha a’ fàgail tachais nam inntinn bhochd. Dè th’ anns na faclan seo? An e faclan fuadain a th’ annta, vocables mar gum biodh? Cha phìobaire mi ach chan eil coltas canntaireachd air — chan ann air fuathagaich co-dhiù. Chan eil cus ciallach sna faclairean a bharrachd. Tha aon fhacal ann, fìth-fàth, sin cleòca a dh’fhàgas do-fhaicsinneach thu. ’S e facal gu math aosta a th’ ann; tha e a’ nochdadh san t-Seann-Ghaeilge mar fía fé (is cruthan eile). Ach cha chreid mi gur e cleòca mar a sin a th’ againn an-seo. Chan eil dad ann an gin dhe na sgeulachdan a tha a’ toirt iomradh air do-fhaicsinneachd.
An aon rud – agus sin an leth-amharas air an dug mi iomradh roimhe – a bhuail orm, sin an rann ud a tha a’ nochdadh ann an ‘Jack and the Beanstalk’:
Fee-fi-fo-fum,
I smell the blood of an Englishman,
Be he alive, or be he dead
I’ll grind his bones to make my bread
Chan e dìreach gu bheil fee-fi-fo-fum car coltach ri fith fath fuathagaich ach tha an rann air fad gu math coltach na nàdar ris an rann Ghàidhlig, nach eil?
A-rèir coltais, ’s ann aig Shakespeare a tha seo a’ nochdadh ann an sgrìobhadh a’ chiad turas (mar fie, foh, and fum). Tha an Oxford English Dictionary (aig a bheil e mar fee-faw-fum) ag innse dhuinn gur e doggerel a th’ ann ach cha do lorg mi cus a mhìnicheas air na tha fee-fi-fo-fum a’ ciallachadh ann, no cò às a thàinig e. ’S e sin, an e faclan fuadain Beurla a th’ annta no saoil an do ghoid a’ Bheurla seo air cànan eile? Ged a tha eòlaichean sgeulachdan ag innse dhuinn gu bheil ‘Jack and the Beanstalk’ a’ buntainn ri roinn sgeulachdan ris an canar “neach a’ marbhadh dràgan”, chan fhaighear a’ phònair draoidheachd ud ach ann am Breatainn. Cha chuireadh e iongnadh orm nam biodh freumh no freumhag Cheilteach aig Jack, car mar a dh’fhàg àireamhan nam Breatannach lorg san yan tan tethera.
Ach ged a tha pailteas iongnaidh orm, chan eil dad a dh’fhios. Saoil a bheil sgeulachd mar seo aig na Cuimrich? No a bheil mi fada ceàrr ’s mìneachadh gu tur eadar-dhealaichte air? Dè ur beachd-ne?
As Copyright Administrator for the Decoding Hidden Heritages project, it’s my role to investigate the copyright status of the sound material and transcriptions in the Tale Archive.
Everyone involved with a sound recording has copyright to their material. As a result, it can be a lengthy process when checking which individuals are involved with a recording, and if The School of Scottish Studies Archives (SSSA) hold records of copyright assignation. Typically, the search must go outwith SSSA and that’s when I feel like donning my deerstalker! Today I will highlight some of that process.
We come across a number of contributors who are down as Unknown or Anonymous in our collections. There can be a few different reasons why this happened; not everyone’s names were captured by the fieldworker, or it was a cataloguing error. Sometimes people just wished to remain anonymous – either they were too shy to go on record, or the material may have been deemed too sensitive. These days, we have distinct copyright and Data Protection rules to safeguard sensitive material. We also have methods to close or mute someone’s material for a set period of time rather than anonymising completely or forever. So there is some flexibility in the approaches that we can take.
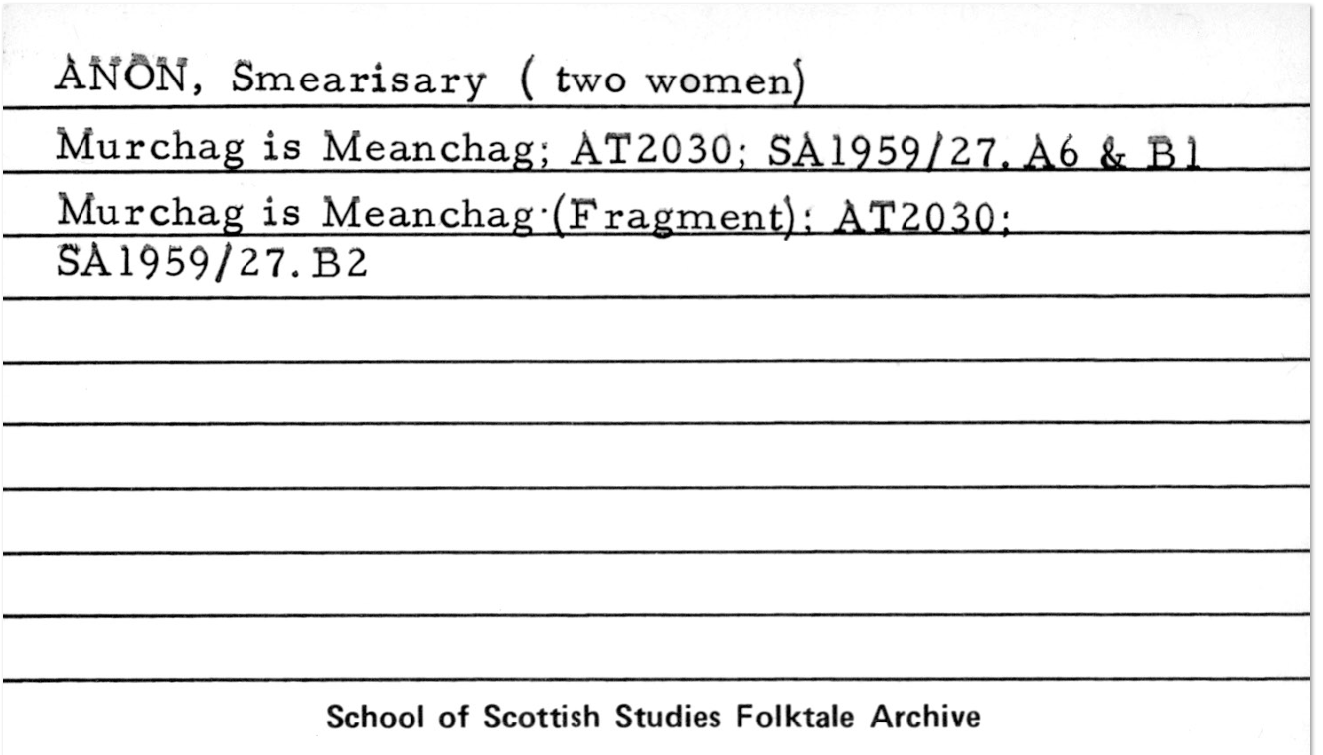
If persons are not explicitly named for a recording, it doesn’t mean we can assume that copyright can be cleared on that basis alone – we still have to do our due diligence. Given that this week marks International Woman’s Day 2022 (March 8) – let’s look at an example of two anonymous women in the Tale Archive. This card refers to part of the recording SA1959.027 – but it doesn’t give us much information, other than it was recorded in Smearisary, Glenuig and the story is of Murchag is Meanchag/Murchag A’s Mionachag.
My next step was to look at what is included on the whole recording. On checking the Summary book for 1959, it shows that this was a recording made by Calum Maclean, Basil Megaw and Ian Whittaker. The other contributors on the tape were Angus MacNeill, Sandy Gillies and “Anon Woman A”, “Anon Woman B / Mrs MacDonald (?)” and “Anon Woman C”. Not terribly enlightening, in the grand scheme of things! Even if Anon Woman B might be a Mrs MacDonald, it doesn’t give us anything to go on. From here I went down to the archive store room to look at the original tape box – sometimes there was a listing completed at the time of recording and included in the box.
A beautiful listing both outside and inside the box, but – as an archive colleague from the past has noted, in pencil – “Who are the informants?”
Listening to the recording itself can be helpful in some cases, because often the name is given at some point – but my Gaelic is not yet good enough for this tape.
So, what now? I will contact our colleagues at Tobar an Dualchais because parts of this tape are available to listen to online; these recordings are by the named contributors. It is possible when their researchers were seeking copyright that they were able to find out who these anonymous female storytellers were. I will keep you updated.
It’s really important to find out who unknown people in our collections are and, if possible, put a name to the voice and acknowledge their important contribution in the archives. I include a very short extract of Anon Woman A and Anon Woman B / Mrs Macdonald (?), of Smearisary and thank them for making my job so interesting!
This clip is placed here on a risk-balanced approach and that is another part of the process for another blog post!
Extract from SA1959.027 from collection of School of Scottish Studies Archives.
A Faroese stamp featuring the legend of Kópakonan (the Seal Woman).
Whilst working on data capture for the Decoding Hidden Heritages Project, I came across this tale of a seal-woman, or selkie (ScG: ròn ‘seal’), that struck a chord with me. Stanley Robertson from Aberdeen tells of the story he heard from his father, ‘The Selkie o the River Dee’, which Stanley was told was a true story and referred to an ancestor of his.
A man spies a seal-woman coming out of the River Dee and shedding her skin on the shore. The man takes the skin and hides it from her to force the woman to go home with him and be his wife. They have several children together and one day the children find the seal skin the man had hidden. The woman takes the skin and disappears back into the River Dee, never to return, with the man arriving just in time to see her go.
Upon reading the story, it immediately occurred to me that this seems to have been a tragic incident that was ‘spun’ into a whimsical tale, likely for the benefit of the children involved. Surely enough, Stanley goes on to say that he thinks the woman might have actually committed suicide, as the story referred to ”real” people. I think this story is fascinating because it has the ability to truly resonate with the listener or reader on a very emotional level. You don’t need to be an expert on folktales to understand why or how it came to be. Similar seal-woman (or mermaid) stories are found across the North Atlantic, for example in Irish, Icelandic and Faroese folklore.
A much more cheerful selkie reference in popular culture can be seen in the beautifully-illustrated Irish feature film: Song of the Sea.
For an automatic translation into English, click here. For a version in Irish, click here.
15 Am Faoilleach 2022
Ùghdar: Dr Andrea Palandri, Rannsaiche Iar-Dhotaireil
Andrea Palandri
As t-samhradh 2021, fhuair Gaois maoineachadh fo sgeama AHRC-IRC gus pròiseact a thòiseachadh air a’ Phrìomh Chruinneachadh Làmh-sgrìobhainnean bho thasg-lann Coimisean Beul-aithris na h-Èireann (Cumann Béaloideasa Éireann, University College Dublin). Canar Decoding Hidden Heritages ris a’ phròiseact seo. Is e cuspair a’ bhlog seo an obair dhigiteachaidh a tha a’ dol air adhart mar phàirt den phròiseact air làmh-sgrìobhainnean a’ Phrìomh Chruinneachaidh.
Thathas a’ meas gu bheil timcheall air 700,000 duilleag làmh-sgrìobhainn anns a’ Phrìomh Chruinneachadh Làmh-sgrìobhainnean, ga fhàgail mar aon de na cruinneachaidhean as motha de stuth beul-aithris air taobh an iar na Roinn Eòrpa. Bhiodh seo air a bhith na dhùbhlan mòr airson digiteachadh mura biodh Transkribus air teicneòlas AI airson aithne làmh-sgrìobhaidh a leasachadh thar nam beagan bhliadhnaichean a dh’fhalbh. Tha Decoding Hidden Heritages gu mòr an urra air an teicneòlas seo agus leigidh e leis a’ phròiseact a innealan-aithne làmh-sgrìobhaidh fhèin a dhèanamh stèidhichte air sgrìobhadairean sònraichte sa chruinneachadh.
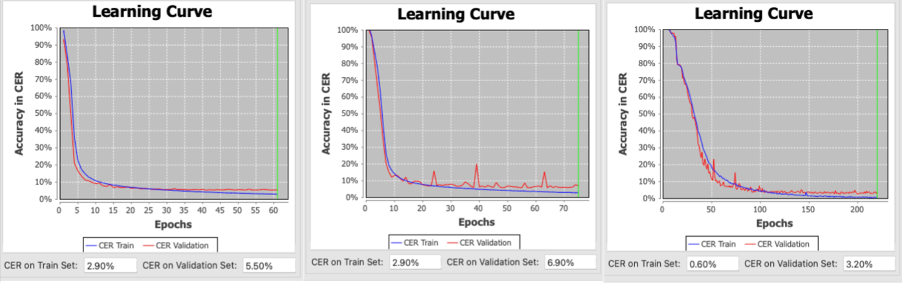
On a thòisich ar luchd-rannsachaidh a bhith ag obair leis a’ bhathar-bog Transkribus tràth san Dàmhair, tha sinn air trì innealan làmh-sgrìobhaidh aithnichte a dhèanamh a tha ag obair aig ìre mionaideachd nas àirde na 95%: aon airson Seosamh Ó Dálaigh, aon airson Seán Ó hEochaidh agus aon airson Liam Mac Coisdealbha, trì de an luchd-cruinneachaidh as dealasaiche a bha ag obair don Choimisean.
Figear 1 (Clí) Seosamh Ó Dálaigh a’ cruinneachadh beul-aithris bho Tomás Mac Gearailt (Paraiste Márthain, Corca Dhuibhne) agus (deas) làmh-sgrìobhainn a sgrìobh e bho chlàradh a rinn e de Tadhg Ó Guithín (Baile na hAbha, Dún Chaoin, Corca Dhuibhne) ga ath-sgrìobh ann an Transkribus.
Tha Transkribus feumail air tar-sgrìobhadh ceart a rèir duilleag na làmh-sgrìobhainne – a rèir làmh-sgrìobhadh agus dual-chainnt an neach-cruinneachaidh – gus an einnsean a thrèanadh. An dèidh a bhith ag aithneachadh timcheall air leth-cheud duilleag san dòigh seo, thrèan sinn modal làmh-sgrìobhaidh aig ìre gu math èifeachdach (90% +). Is e dòigh-obrach a’ phròiseict na dhèidh seo ath-sgrìobhadh a dhèanamh air àireamh mhòr de dhuilleagan gu fèin-ghluasadach agus luchd-taic rannsachaidh (Emma McGee, Kate Ní Ghallchóir agus Róisín Byrne) a chur gan ceartachadh mean air mhean. Na dhèidh sin, faodaidh sinn na modailean a dh’ath-thrèanadh air stòr-dàta nas fharsainge gus modalan cànain nas fheàrr (~ 95%) a fhaighinn. Tha toraidhean eadar-amail na h-obrach seo a’ toirt dòchas dhuinn gum bi e comasach don phròiseact ìre mionaideachd nas àirde a choileanadh anns na mìosan a tha romhainn, a leigeas leinn a bhith ag ath-sgrìobhadh gu fèin-ghluasadach mòran den Phrìomh Chruinneachadh Làmh-sgrìobhainnean cha mhòr thar oidhche.
Figear 2 An lúb ionnsachaidh de mhodalan cànain a chaidh a dhèanamh le Transkirbus gu ruige seo: Seán Ó Dálaigh (clí), Seán Ó hEochaidh (meadhan) agus Liam Mac Coisdealbha (deas).
Tha làmh-sgrìobhainnean a’ Phrìomh Chruinneachaidh am measg nan teacsaichean as motha anns a bheil lorg nan dual-chainntean ann an corpas litreachas Gaeilge an latha an-diugh. Is e dòigh-obrach agus dòighean deasachaidh Shéamuis Ó Duilearga fhèin a tha a’ nochdadh ann an Leabhar Sheáin Í Chonaill. Bhrosnaich agus stèidhidh e Comann Beul-aithris na hÈireann ann an 1927 agus chan eil mìneachadh nas fheàrr air an dòigh-obrach seo na na faclan a sgrìobh Séamus Ó Duilearga fhèin ann an ro-ràdh an leabhair:
Ní raibh ionnam ach úirlis sgríte don tseanachaí: níor atharuíos siolla dá nduairt sé, ach gach aon ní a sgrí chô maith agus d’fhéadfainn é.
Cha robh annam ach inneal sgrìobhaidh dhan t-seanchaidh: cha do dh’atharraich mi lide dhe na thuirt e, ach sgrìobh e a h-uile rud cho math ’s a b’ urrainn dhomh.
(S. Ó Duilearga, Leabhar Sheáin Í Chonaill, xxiv)
Cha deach mòran leabhraichean fhoillseachadh ann an litreachas na Gaeilge bhon uairsin a dh’fhuirich cho dìleas ri dual-chainnt an neach-labhairt ’s a rinn Leabhar Sheáin Í Chonaill: tha cruthan dualchainnteach mar bheadh saé an àite bheadh sé (bhiodh e), no buaileav an àite buaileadh (chaidh a bhualadh) no fáilthiú an àite fáiltiú (fàilteachadh). Mar sin, tha cànan nan làmh-sgrìobhainnean anns a’ Phrìomh Chruinneachadh a’ taisbeanadh dual-chainnt, no eadhon ideo-chainnt, an luchd-fiosrachaidh gu làidir. Mar eisimpleir, bidh claonadh dual-chainnte, do raibh an àite go raibh (gun robh) ga ràdh; bha sin aig cuid de dhaoine à Corca Dhuibhne ann an Chonntaidh Chiarraí, m.e. anns na sgeulachdan a sgrìobh Seosamh Ó Dálaigh bho Thadhg Ó Guithín (Baile na hAbha, Dún Chaoin).
Figear 3 Thug Diarmuid Ó Sé iomradh air an iongantas dualchaint seo ann an Gaeilge Chorca Dhuibhne (§619)
Tha làmh-sgrìobhainnean a’ chruinneachaidh seo car neònach air sàillibh nan cruthan beaga dual-chainnteach a chlàraich an luchd-cruinneachaidh fhad ’s a bha iad gan ath-sgrìobhadh. Is ann air sgàth an iomadachd cànain seo anns a’ chorpas nach eil am pròiseact ag amas air aon mhodail mòr a chruthachadh gus an Cruinneachaidh ath-sgrìobhadh air fad. A bharrachd air sin, chan e a-mhàin gu bheil sinn a’ dèiligeadh ri diofar dhual-chainntean ach tha sinn cuideachd a’ dèiligeadh ri diofar luchd-cruinneachaidh aig nach robh làmh-sgrìobhadh is litreachadh dhual-chainntean co-ionnan. Tha na duilgheadasan seo a’ fàgail gu bheil an corpas Gaeilge seo gu math measgaichte. Feumar dèiligeadh ris le cùram agus le taic bho leabhraichean dhual-chànanachais a bhios a’ toirt cunntas air na puingean beaga cànain a gheibhear ann.
Anns an t-sreath seo, tha sinn a’ toirt sùil air laoich a rinn adhartas cudromach ann an teicneolas nan cànanan Gàidhealach. Airson a’ cheathramh agallaimh, cluinnidh sinn bho Roibeart MacThòmais. Coltach ri Lucy Evans, the Rob air ùr thighinn gu saoghal na Gàidhlig. Chaidh fhastadh airson còig mìosan ann an 2021 mar phàirt de phròiseact a mhaoinich Data-Driven Innovations (DDI), far a robh an sgioba a’ cruthachadh teicneolas aithneachadh labhairt airson na Gàidhlig. Dh’obraich Rob air inneal coimpiutaireachd ùr-nòsach eile, An Gocair.
Nuair a bhios tu a’ feuchainn ri teicneòlas cànain a chruthachadh airson mhion-chànain, ’s e an trioblaid as bunasaiche ach dìth dàta. Chan eil an suidheachadh a thaobh na Gàidhlig buileach cho truagh ri cuid a mhion-chànanan eile, ach tha deagh chuid dhen dàta seann-fhasanta a thaobh dhòighean-sgrìobhaidh. Tha sin a’ fàgail nach gabh e cleachdadh gus modailean Artificial Intelligence a thrèanadh gun a bhith a’ cosg airgead mòr air ath-litreachadh.
Bidh An Gocair ag ath-litreachadh theacsaichean gu fèin-obrachail – tha e glè choltach ri dearbhadair-litrichidh. Chan eil ann ach ro-shamhla (prototype) an-dràsta agus tha sinn a’ sireadh taic a bharrachd airson a leasachadh. Aon uair ‘s gum bi e deiseil, b’ urrainnear a chur gu feum ann an iomadach suidheachadh, leithid foillseachadh, foghlam aig gach ìre, prògraman coimpiutaireachd eile agus rannsachadh sgoileireil. Cuiridh e gu mòr cuideachd ri pròiseact rannsachaidh ùr a tha a’ tòiseachadh an dràsta eadar còig oilthighean ann am Breatainn, Ameireaga agus Èirinn: ‘Decoding Hidden Heritages in Gaelic Traditional Narrative with Text-mining and Phylogenetics’.
In this interview series, we are looking at individuals who have significantly advanced the field of Gaelic, Irish and Manx language technology. For the fourth interview, we hear from Mr Rob Thomas. Like Lucy Evans, whom we interviewed a few months ago, Rob has come to the world of Gaelic language technology only recently. He was chosen from a strong field to work with us on project funded by Data-Driven Innovations (DDI), in which we were developing the world’s first automatic speech recogniser for Scottish Gaelic. Rob worked on an important strand of this project – developing a brand-new piece of software called An Gocair.
When trying to develop language technology for minority languages, the most fundamental problem is data sparsity. The situation for Gaelic is not as dire as for some other minority languages, but much of the textual data available is outdated in terms of orthography. That makes it impossible to train machine learning models – at least without spending a lot of money on editing spelling.
An Gocair re-spells texts automatically – it’s basically an unsupervised spell-checker with some extra bells and whistles. It is currently only a prototype, however, and we are seeking additional support for its development. Once completed, it will be able to be used in a wide range of contexts, including publishing, education at all levels, as part of other computer programs and within academic research. It will also make a significant contribution to a new research project currently underway between five universities in Britain, America and Ireland: ‘Decoding Hidden Heritages in Gaelic Traditional Narrative with Text-mining and Phylogenetics’.
Interview with Rob Thomas
Agallamh le Roibeart MacThòmais
Tell us a little bit about your background. For instance, where are you from, and what got you into language technology work?
Hello! I’m from a small town in South Wales called Monmouth. I grew up mostly in the countryside, quite far from civilisation. My interest in linguistics probably stems from having a fantastic English teacher in my high school. (Shout out to Mr Jones.) I don’t know if it was the content or how he taught it, but I remember at the time really enjoying the subject and his lessons.
Rob Thomas
I went on to study English Language and Linguistics at the University of Portsmouth. After graduating, I worked for a while at Marks and Spencer as I was not yet sure what kind of career I was looking for. Still kind of directionless, I spent a year and a bit traveling and on return began working in tech support. I managed to find a course in Language Technology at the University of Gothenburg, I had recently found a new interest in programming and this was a great way to merge my new interest and my academic foundation. After a few years living, studying and working in Sweden, I returned to the UK and began the job hunt and was lucky to find the position at the University of Edinburgh.
You mention studying language technology at the University of Gothenburg. What did you find most interesting about the course? Do you have any advice for someone who is thinking about studying language technology?
The course was fascinating and it attracted students from quite a broad background. The first meeting was like The Time Machine by H.G Wells: we were all introduced as the linguist or the mathematician, cognitive scientist, computer scientist, philosopher etc. I think what stood out is that language technology, as a field, relies on input and experience from a multitude of academical backgrounds. This is due to the complex nature of language. I think I would advise anyone who is not from a technical or STEM background to think about how important your knowledge and perspective is for the future of language-based AIs, systems and services. But if, like me, you do come from a humanities background be prepared to dive straight back in to the maths that you thought you managed to escape after you completed your GCSEs.
You are developing a tool for Scottish Gaelic that automatically corrects misspelled words and makes text conform to a Gaelic orthographical standard. That’s impressive for someone with Gaelic, and even more so for someone who doesn’t speak it. How did you manage to do this?
I am quite lucky to be supported by Gaelic linguists and other programmers. I found a way to integrate Am Faclair Beag, an online Gaelic dictionary developed by our resident Gaelic domain expert, Michael Bauer. Alongside the dictionary we translated complicated linguistic rules into something a computer could understand. We have managed to develop a program that takes a text and, line by line, attempts to identify spelling that don’t belong to the modern orthography and searches for the right word from our dictionary. If it has no luck, it then attempts to resolve the issue algorithmically. From the start I knew it was important that I was able to compare the program’s output to work done by Gaelic experts so that I could see whether I was improving the tool or just breaking it.
An Gocair
Since you’ve been born, you’ve seen language technology change and permeate how we work and live. What’s been your own experience of the changes that it has brought?
It has been very interesting witnessing the exponential growth of language technology in the mainstream. It wasn’t until I studied it that I realised how much it was already embedded in websites and services that I’ve been using for years. The more visible applications such as smart assistants are becoming much more normalised in our society. Even my grandma uses her smart assistant to turn on classic FM and put on timers which I think is really cool. My grandma is pretty tech savvy to be fair!
With the dominance of world languages in mass media and on the internet, some would say that technology is an existential threat to minority languages like Gaelic and Welsh. What do you think about this? Are there ways for minority languages to survive or even thrive today?
I think one of the issues in language technology is that most of the work is dedicated to languages that already have huge amounts of resources, for example English. Most of the breakthroughs are being made by large companies that ultimately aim to increase the value of their services. There are a lot of companies that sell language technology as a service (e.g. machine translation) rather than serving communities per se. The latter may not have direct monetary value, but it’s essential to keep that focus in order to allow minority languages to gain access to state-of-the-art technology.
What are your predications for language technology in the year 2050? If you had your own way, what would you like to see by that time?
I imagine smart assistants will be present in more spaces in society, perhaps even in a more official capacity. The county council in Monmouthshire already use a smart chatbot for questions about what days your bins are being collected. Imagine if they were given greater powers such as being able to make important decisions (scary thought). The more time goes on, the more I think we are going to end up with malevolent AIs like HAL from 2001, Space Odyssey, rather than ones like C3PO from Star Wars.
I’m not sure what I would like to see. It would be nice if there was more community-developed and open-source alternatives to what the main large tech companies provide, so a consumer would be able to be sure their data was being used in a safe and respectable way.
Decoding Hidden Heritages in Gaelic Traditional Narrative with Text-Mining and Phylogenetics
This exciting new three-year study is funded by the AHRC and IRC jointly under the UK–Ireland collaboration in digital humanities programme. It brings together five international universities, two folklore archives and two online folklore portals.
October 2021–Sept 2024
‘Morraha’ by John Batten. From Celtic Fairy Tales (Jacobs 1895)
Summary
This project will fuse deep, qualitative analysis with cutting-edge computational methodologies to decode, interpret and curate the hidden heritages of Gaelic traditional narrative. In doing so, it will provide the most detailed account to date of convergence and divergence in the narrative traditions of Scotland and Ireland and, by extension, a novel understanding of their joint cultural history. Leveraging recent advances in Natural Language Processing, the consortium will digitise, convert and help to disseminate a vast corpus of folklore manuscripts in Irish and Scottish Gaelic.
The project team will create, analyse and disseminate a large text corpus of folktales from the Tale Archive of the School of Scottish Studies Archives and from the Main Manuscript Collection of the Irish National Folklore Collection. The creation of this corpus will involve the scanning of c.80k manuscript pages (and will also include pages scanned by the Dúchas digitisation project), the recognition of handwritten text on these pages (as well as some audio material in Scotland), the normalisation of non-standard text, and the machine translation of Scottish Gaelic into Irish. The corpus will then be annotated with document-level and motif-level metadata.
Analysis of the corpus will be carried out using data mining and phylogenetic techniques. Both the data mining and phylogenetic workstreams will encompass the entire corpus, however, the phylogenetic workstream will also focus on three folktale types as case studies, namely Aarne–Thompson–Uther (ATU) 400 ‘The Search for the Lost Wife’, ATU 425 ‘The Search for the Lost Husband’, and ATU 503 ‘The Gifts of the Little People’. The results of these analyses will be published in a series of articles and in a book entitled Digital Folkloristics. The corpus will be disseminated via Dúchas and Tobar an Dualchais, and via a new aggregator website (under construction) that will include map and graph visualisations of corpus data and of the results of our analysis.
Project team
UK
Principal Investigator Dr William Lamb, The University of Edinburgh (School of Literatures, Languages and Cultures)
Co-Investigator Prof. Jamshid Tehrani, Durham University (Department of Anthropology)
Co-Investigator Dr Beatrice Alex, The University of Edinburgh (School of Literatures, Languages and Cultures)
University of Edinburgh
Language Technician, Michael Bauer
Louise Scollay, Copyright Administrator
Ireland
Co-Principal Investigator Dr Brian Ó Raghallaigh, Dublin City University (Fiontar & Scoil na Gaeilge)
Co-Investigator Dr Críostóir Mac Cárthaigh, University College Dublin (National Folklore Collection)
Co-Investigator Dr Barbara Hillers, Indiana University (Folklore and Ethnomusicology)