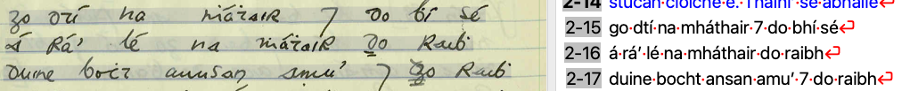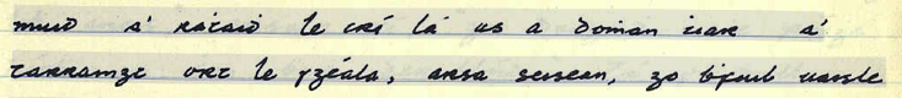Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
We’re thrilled to announce the launch ofHidden Heritages, a brand-new website for accessing Scottish and Irish traditional tales. This resource is the outcome of an international, multi-year collaboration between universities in the UK, Ireland and USA, generously supported by the Arts and Humanities Research Council (AHRC) and the Irish Research Council (IRC).
Between 2021 and 2024, our team digitised and recognised thousands of tales from the School of Scottish Studies Archives (SSSA) and the Irish National Folklore Collection (NFC). The result? An online repository featuring 5,515 folktales, with more than 3,400 tales from Scotland and over 2,000 from Ireland.
Search page for the Hidden Heritages website.
Behind the Scenes
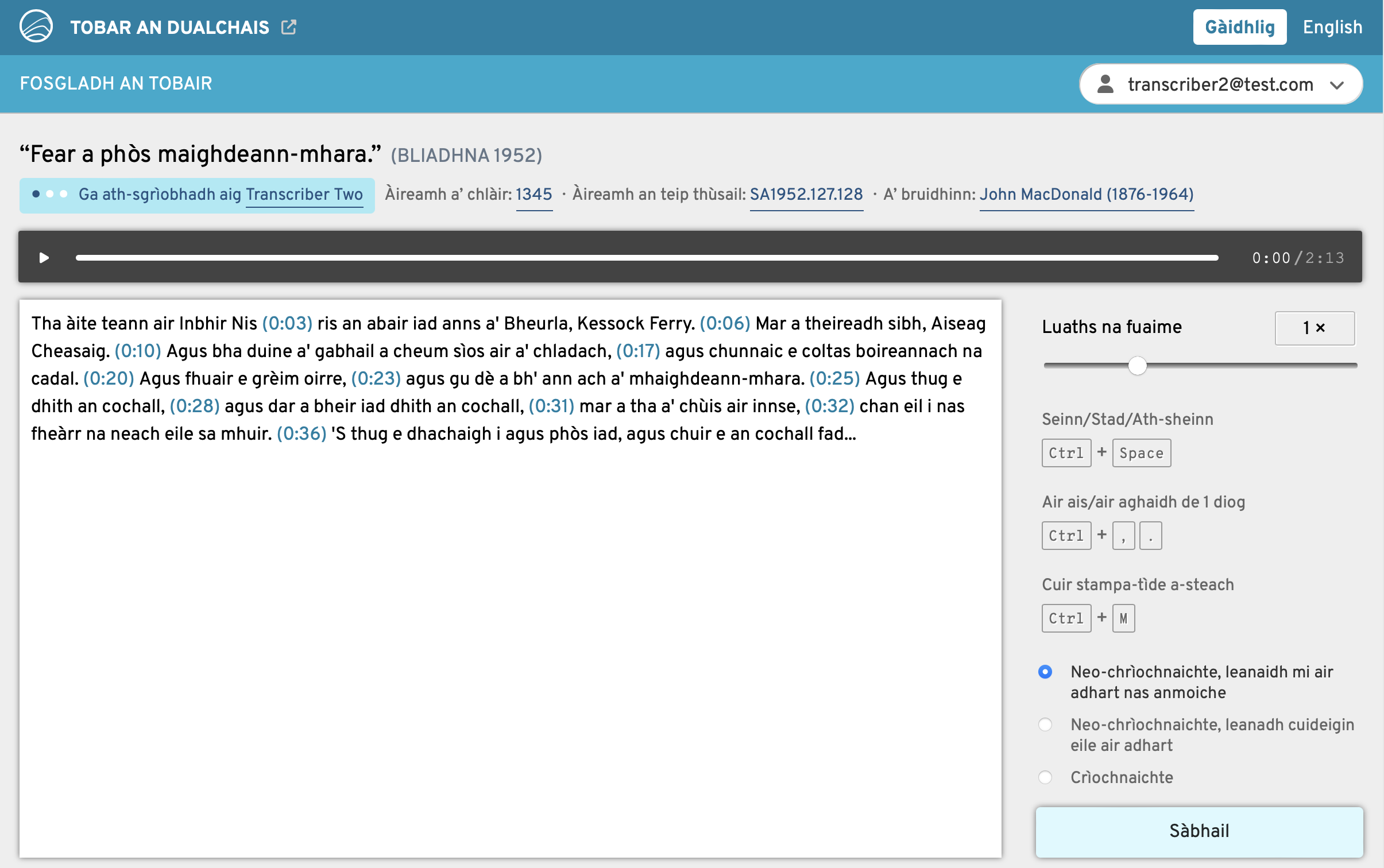
Many of these tales date back centuries and were collected orally from tradition bearers up to the end of the 20th century. Ethnologists at the SSSA and NFC transcribed thousands of them from fieldwork recordings as handwritten manuscripts. In other cases, the tales came from printed books and articles. Using AI-powered text recognition (OCR for printed material and HTR for handwriting), the research team converted these documents to digital text and have now made them publicly accessible online, often for the very first time. Transkribus, the handwriting recognition tool, was instrumental for this work.
While the automatic transcriptions aren’t flawless, the accuracy is impressive, with less than 5% error rates. And because the original transcriptions often captured rich dialectal forms of Irish and Scottish Gaelic, these texts are a goldmine for linguistic and cultural analysis.
Viewing the texts and metadata for the Gaelic tale ‘Biast na[n] Naoi Ceann’ (‘Beast of the Nine Heads’)
Dall ort! Jump Right In!
Using the website couldn’t be simpler. Explore by searching for your favourite folktale themes. Perhaps you’re interested in tales of witches (buidsichean), giants (fuamhairean) or fairies (Na Daoine Beaga‘The Wee Folk’). You can filter stories by date, tale-type, language, gender of collectors and narrators, and much more. Interactive visual maps will guide you straight to tales from particular places, letting you discover how stories travelled and evolved.
Users who don’t have Gaelic or Irish can copy and paste texts into Google Translate to get a rough English translation. For many of Scottish tales, we also include direct links to Tobar an Dualchais / Kist o Riches, where users can access the original fieldwork recordings from the School of Scottish Studies Archives. Irish readers can even help to improve some of the transcriptions, but following links to Meitheal Dúchas.
Whether you’re a researcher, folklore enthusiast or just curious about traditional tales, we invite you to explore, share and participate in this rich cultural legacy. Scottish material is provided for research purposes, and Irish stories are available under a Creative Commons licence, allowing non-commercial reuse — remember to attribute your sources carefully.
Visit www.hiddenheritages.ai and explore Gaelic storytelling now! And keep an eye out for our upcoming book, Decoding the Oral Traditions of Scotland and Ireland: From Manuscripts to Models, to be published by Edinburgh University Press in 2026.
Scottish Gaelic, spoken by roughly 60,000 people today, is poised for a technological transformation thanks to the ÈIST project, led by the University of Edinburgh. ÈIST [eːʃtʲ] (‘ayshch’) is short for Ecosystem for Interactive Speech Technologies, and means ‘listen’ in Gaelic. The project is funded by the Scottish Government and Bòrd na Gàidhlig, with key partners including the BBC ALBA, NVIDIA, the University of Glasgow and Tobar an Dualchais / Kist o Riches. It aims to support the revitalisation of the language through cutting-edge interactive technologies, including speech recognition.
Since launching in 2023, ÈIST has focussed on developing accurate speech-to-text for Gaelic, but also for English — to cope with code-switching. The initial aim was to produce a system that could generate Gaelic-medium subtitles for BBC ALBA and Radio nan Gàidheal. In a 2025 research paper, the team reports achieving nearly 90% accuracy for chat shows, news and current affairs programmes. Now the team is expanding the technology, making it suitable for more diverse contexts, ranging from Gaelic-speaking classrooms to old fieldwork recordings.
In Jan 2026, the team will provide a user interface and a robust API (Application Programming Interface) to democratise these tools further. For the first time, developers and researchers worldwide will gain access to Gaelic speech recognition, and will be able to embed the technology into applications ranging from educational software to digital assistants. Our first model release is based upon OpenAI’s open-weight Whisper model and is now available here.
Bridging Linguistic Gaps
Currently, Gaelic speech recognition systems struggle to transcribe younger speakers, whose speech patterns often differ from those of heritage speakers. ÈIST addresses this with a dedicated subproject, Recognising Children’s Speech, funded by Bòrd na Gàidhlig, which is gathering data from Gaelic Medium Education schools and units across Scotland. This new data will ensure that the speech of young learners is represented accurately.
The implications of this work are profound. Enhanced speech recognition can transform educational tools, such as TextHelp’s Read&Write, providing more effective support for literacy and learning among children. It can also improve accessibility for Gaelic speakers of all ages, especially those with literacy challenges or hearing impairment, providing critical tools for communication and inclusion.
A Community-Powered Initiative
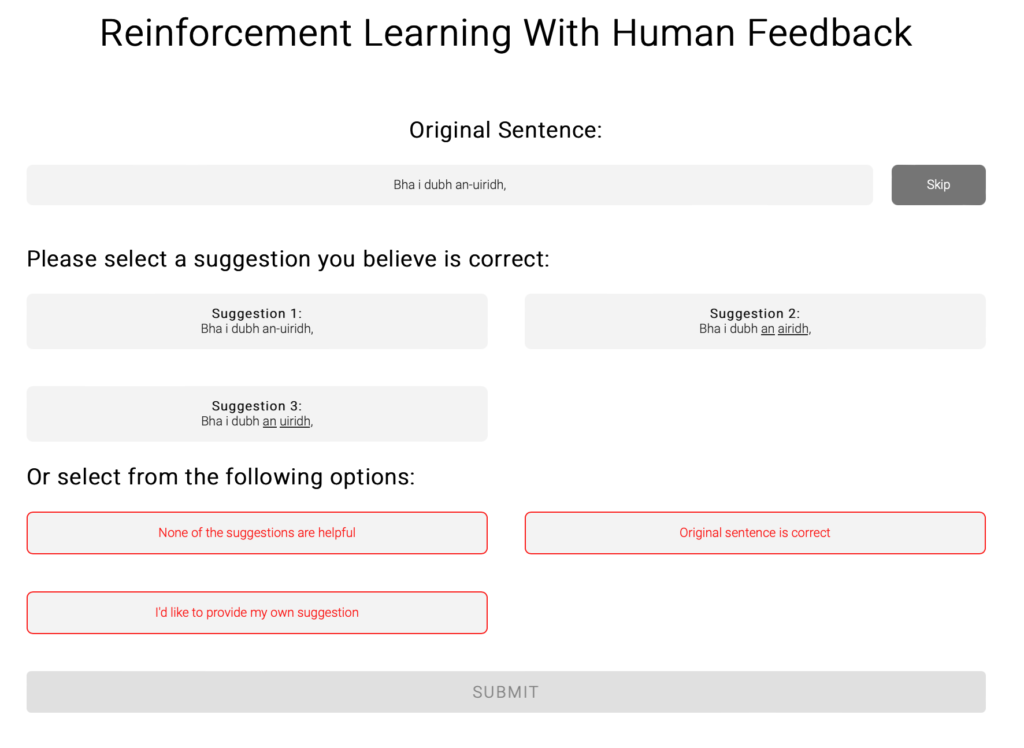
Central to ÈIST’s mission is Opening the Well, a pioneering crowdsourcing platform that launched at the University of Glasgow in December 2025. This initiative is mobilising the Gaelic-speaking community worldwide to transcribe audio recordings of traditional narratives and oral history held on the Tobar an Dualchais portal, such as those originally from the School of Scottish Studies Archives (University of Edinburgh) and the National Trust for Scotland’s Canna House Archive. It takes its cue from Ireland’s successful Meitheal Dúchas crowdsourcing project. These transcriptions won’t just make Scottish heritage more accessible — they will also provide vital training data to enhance the accuracy and versatility of future speech recognition models.
The editing screen in Opening the Well
Risks, Rewards and Responsibility
The team behind ÈIST is keenly aware that speech and language technologies are not neutral tools. Poorly trained models can misrepresent language, distort culture or reinforce social bias. That is why ÈIST places community involvement at the heart of its design process.
The researchers also promote best practices for ethical AI use in revitalisation: curate transparent training data, return outputs to the community (e.g., through DASG, the Digital Archive of Scottish Gaelic), and avoid relying on ‘big tech’ to solve our problems, albeit poorly. It is a values-led approach as much as a technical one.
The Future of Gaelic in the Digital Age
Finally, ÈIST is developing an interactive, text-based interviewer chatbot. This promises not only to engage speakers in naturalistic conversation but also to generate essential data for future applications. When combined with speech technology, such a chatbot could assist with language learning, offering conversational practice previously difficult to achieve outside of a native-speaking community. While this will never replace human teachers, it could be a very useful support to teaching and learning.
In a broader sense, ÈIST represents a powerful case study in how language technology can empower minority languages. The project’s blend of machine learning and cultural preservation illustrates how digital innovation can help to sustain diversity, rather than eroding it. For more information about ÈIST, contact w.lamb@ed.ac.uk.
ÈIST Investigator Team
Prof William Lamb (PI, University of Edinburgh)
Dr Bea Alex (Co-I, University of Edinburgh)
Prof Peter Bell (Co-I, University of Edinburgh)
Ms Rachel Hosker (Co-I, University of Edinburgh)
Prof Roibeard Ó Maolalaigh (Co-I, University of Glasgow)
ÈIST Implementation Team
Dr Alison Diack (Transcriber, DASG, University of Glasgow)
Mr Cailean Gordon (Lead transcriber, Tobar an Dualchais / Kist o Riches, University of the Highlands and Islands)
Dr Ondřej Klejch (Speech processing specialist, Informatics, University of Edinburgh)
Dr June Graham (Research Assistant in Gaelic Medium Education (GME) Speech Recognition, University of Edinburgh)
Dr Michal Měchura (Web designer and computational linguist, self-employed)
Ms Lilly Mellon (Copyright and Permissions Administrator, University of Edinburgh)
Partner Organisations
BBC ALBA
Digital Archive of Scottish Gaelic (University of Glasgow)
Faclair na Gàidhlig [Historical Dictionary of Gaelic]
MG ALBA
NVIDIA
National Trust for Scotland
School of Scottish Studies Archives, Heritage Collections
In working on the project for the University of Edinburgh, our team from Code Your Future is thrilled to present our project, ‘Crowdsourcing User Judgements for Gaelic Normalisation’. Aimed at Gaelic speakers, this project will collect user inputs on passages of historical Gaelic writing that have been updated to modern orthography by an AI model developed by the University of Edinburgh. Through hard work, collaboration, innovation and problem-solving, we have hugely enhanced a previous research project, ‘An Gocairː An Automatic Gaelic Standardiser’ and not only met but exceeded our goals.
The ‘An Gocair’ Web App
Our team used the PERN stack as it uses a common framework and program language so it can be easily modified to enhance user experience and interactions in the future. In today’s globalised world, it is useful to be able to launch this application from any device and location. We have admin features in our application to give researchers more control over the data, and user sign-in features that allow users to sign in from social media accounts. Throughout the project, there were challenges in terms of adhering to project requirements. Those challenges were an opportunity for us to learn. So we valued our team members’ creativity, experimentation and unique skills to find solutions to the problems that aligned with our project objective.
The Reinforcement Learning with Human Feedback App – for crowdsourcing Gaelic speaker judgements on AI-corrected texts
Our project followed an agile mindset that prioritises interactions, customer collaborations and responsiveness to change. As a result, we adapted agile values and principles focusing on short development cycles like creating simpler tasks, allocating them to the team members and receiving constant feedback from the team lead. Also, the agile approach helped us to manage time efficiently through sprint planning, daily standup meetings and optimising our time allocation and productivity.
By using React we have made every feature into a component so it can be easily modified in the future. By using the Passport module we have made the application more secure. Implementing it into the application was a challenge, however, and took a lot of the time. Before coming up with the passport, we tried a few different authentication tools but they did not give us the ability to be used as login with other social media accounts.
Our project relies on data and the Postgres database management system is useful for storing and managing our data efficiently. Our database Schema design considers scalability in mind to handle a growing dataset and increased user load. We also implemented proper encryption and access control, to protect users’ data and maintain user privacy through admin features.
As the Decoding Hidden Heritages project is nearing the end of its digitisation and metadata collection stage, this is a good opportunity to share some insights from the project on the importance of archival work for the representation of women’s heritage. While the project’s main focus is on the narrative traditions of Scotland and Ireland, valuable information has also been discovered that has wider cultural implications, such as the influence of gender on narrative traditions. These discoveries have been made possible by the digitisation process because it has allowed a re-examination and re-documentation of the archive’s collection. As part of this process at the School of Scottish Studies Archives, I have been able to employ what Prof Melissa Terras terms feminist digitisation practices, which ‘are both an attitude, and an application of technology in an efficient way’.[1] She described this practice as ‘an act of owning women’s history, using digital means, to collate information and histories that the mainstream – for whatever reason – has not tackled’.[2] For this project, that has involved ensuring that women’s material in the archive is accessible to and discoverable by the public through digitisation and accurate metadata collection.
While digitising the Tale Archive I discovered several unique factors that affected women’s presence, or rather their absence, in the archive. In particular, I noticed distinct documentation issues with the archive’s material relating to women. The most significant of these issues was the erasure of women’s names in archival documents and metadata.
There are four distinctive scenarios in which women’s names have been erased:
The documents lack women’s first names.
The most common erasure of women’s names in the archive is the use of only women’s surnames, particularly their married surnames, for example Mrs. Stewart. In SSSA_TA_WT042_001 the informant is only listed as Bean Sheumais (‘Wife of James’). This is most likely because that was how these women would have given their names to the collectors, as was the social practice at the time.
Their husband’s full name is used in lieu of women’s names.
The next most common form of women’s names is their husband’s full name used as their married name, for example Mrs. John MacDonald. In some cases, married women’s first names have been discovered and their full names are included in the metadata. For example, Mrs. Hugh Milne has been recorded as Bella Milne in the project database.
The influence of gender on the documentation of names in these records is made clear in SSSA_TA_GH013_001. The metadata for this transcription records the informant as ‘Andrew Stewart and family’ but the document itself listed it as Mrs. Andy Stewart. Despite the fact that this story is told by Mrs. Stewart about her own experience with a ghost, the metadata recorded her husband as the main informant, erasing Mrs. Stewarts’ ownership over her story. When her husband and son interject into her story, the transcript states ‘Carol Stewart, their son, takes over’ and ‘Andrew takes over’ but, rather than use her full name, it says that the ‘story returns home to Mrs. Stewart’. Each of the male members of the Stewart family have their full names recorded while Mrs. Stewart does not. As a result of re-examining this material, the metadata has been corrected and Mrs. Stewart’s story is now properly recognised in the archive.
The names are unrecorded.
In much of the material, women have shared their stories anonymously. This makes it impossible to document who they are. Women are often referred to as ‘girls’ such as ‘Barra Girl’ (SSSA_TA_GH002_002) or ‘a girl who was native of Glenurqhart’ (SSSA_TA_WT043_002) without their names recorded. Yet, even in these cases it is still important to document the informant’s gender in the metadata. For example, one informant was listed as a ‘Native of Lochcarron’ in SSSA_TA_WT037_015. However, by reading their story it can be ascertained this person was a woman, because she states, ‘when they sent me … I was a young girl at the time’. By documenting their gender in the metadata, at least we are able to accurately acknowledge these women’s presence in the archive.
They are not named in the archive’s metadata but are present in documents.
One of the most significant examples of a woman’s erasure from the archive is SSSA_TA_FL025. This document and its metadata records Walter Johnson as the informant of a transcription. However, the transcription is actually of Bella Higgins telling her personal experience of meeting a fairy [Ed. noted here using the dated and offensive term ‘golliwog’]. Even though it is only Bella speaking, her story had been attributed to Walter Johnson. As a consequence of this incorrect documentation, her voice had been hidden in the archive.
Similarly, in a series of transcriptions by John Stewart and his wife Maggie Stewart (SSSA_TA_GH001_022, 23, 25), John was recorded as the only informant. Even though Maggie was present in them as well, her contributions to their stories were unrecognised. As a result of the careful examination of these documents while they were digitised, these women’s contributions were uncovered and are now appropriately documented in the collection’s metadata.
While in some cases these documentation issues may seem small, they have significant consequences. Women’s names being unrecorded or partially recorded in the archives makes tracing women’s histories and family lineages extremely difficult and often impossible. For example, it is impossible to ascertain from the documentation whether a woman recorded as Mrs. MacDonald is the grandmother, mother, wife or sister-in-law to Mr. John Macdonald because all these women would have been referred to identically. Similarly, when women have no name recorded at all, their contributions to the archive are unidentifiable.
The exclusion of these women misrepresents the material within our archives, presenting the collection as more male dominated than it is. Not only is their re-inclusion into the archive’s metadata important as an act of justice for these women, but it also enriches and expands the historical research and data that can be produced from the archive. As historians Andrew Flinn, Mary Stevens, and Elizabeth Shepherd have argued, ‘the archives that are “chosen” for survival, the terms in which they are described, and the processes by which these decisions are made, do ultimately impact on the collective memory and public histories that are produced from them’.[3]
This is particularly important in the context of the increasing trend in historical research, where historians seek to write women who have been hidden in accounts back into history. A recent example of this is a biography of George Orwell’s wife, ‘Wifedom: Mrs. Orwell’s Invisible Life’ by Anna Funder. She points out that in Orwell’s novel Homage to Catalonia, written while Orwell and his wife were in Spain, he ‘mentions “my wife” 37 times but never once names her. No character can come to life without a name’.[4] However, Funder was able to reconstruct the life of Eileen when she went ‘back to the biographers’ footnotes and sources and into the archives and found details that had been left out. Eileen began to come to life’.[5] Thus, there is immense value in archival sources which is still being discovered today and archivists play a vital role in ensuring that women’s history in these archives does not remain hidden. It is therefore important to seize the opportunity that digitisation projects such as this present to employ feminist digitisation practices on archival collections to uncover women’s hidden histories and ensure their posterity for the future.
The DHH team would like to thank Catherine for her important and timely blog and her excellent contributions to the project.
Bibliography
Flinn, Andrew, Mary Stevens, and Elizabeth Shepherd. “Whose Memories, Whose Archives? Independent Community Archives, Autonomy and the Mainstream”. Archival Science 9, no. 1-2 (2009)
Funder, Anna. “Looking for Eileen: how George Orwell wrote his wife out of his story”. The Guardian, 30 July 2023. Accessed 4 October 2023. https://www.theguardian.com/books/2023/jul/30/my-hunt-for-eileen-george-orwell-erased-wife-anna-funder.
Melissa Terras. “Interview With Professor Melissa Terras On Feminist Digitisation Practices And The Future Of Our Digital Cultural Heritage”. The University Of Edinburgh Futures Institute, 6 January 2023. Accessed 4 October 2023. https://efi.ed.ac.uk/interview-with-professor-melissa-terras-on-feminist-digitisation-practices-and-the-future-of-our-digital-cultural-heritage/.
[1] Melissa Terras, “Interview With Professor Melissa Terras On Feminist Digitisation Practices And The Future Of Our Digital Cultural Heritage”, The University Of Edinburgh Futures Institute, 6 January 2023, accessed 4 October 2023. https://efi.ed.ac.uk/interview-with-professor-melissa-terras-on-feminist-digitisation-practices-and-the-future-of-our-digital-cultural-heritage/.
[3] Andrew Flinn, Mary Stevens, and Elizabeth Shepherd, “Whose Memories, Whose Archives? Independent Community Archives, Autonomy and the Mainstream”, Archival Science 9, no. 1-2 (2009): 76.
[4] Anna Funder, “Looking for Eileen: how George Orwell wrote his wife out of his story”, TheGuardian, 30 July 2023, accessed 4 October 2023. https://www.theguardian.com/books/2023/jul/30/my-hunt-for-eileen-george-orwell-erased-wife-anna-funder.
Our own Prof Will Lamb is working with Dr David Howcroft (lead investigator) and Dr Dimitra Gkatzia from Edinburgh Napier university to build the first tools for Gàidhlig chatbots. This is starting with the creation of a new dataset to train AI models.
Our current experiments (which you can participate in if you speak Gàidhlig!) are focused on building our dataset: we need examples of humans asking and answering questions about museum exhibits in a chat conversation. Participants are paired up and given a set of exhibits from the National Museum of Scotland to discuss, briefly summarising their discussions as well.
The next step? Well, after a bit of data cleanup and anonymisation, it’s time to see how well neural network models for natural language generation work for this amount of data. One of the interesting challenges for this project is trying to see how far you can get in building a chatbot with as little data as possible. The lessons we learn in this work will inform future work, not just in Scottish Gaelic, but in Natural Language Generation more generally!
Why build chatbots for Scottish Gaelic?
We believe the world is a better place when everyone can learn in their preferred language. Scottish Gaelic has fewer language technologies available than languages like English or Mandarin, and we’d like for our research in natural language generation to help in some small way to address this gap.
Why focus on ‘Exhibits’?
Museums are a primary tool for learning outside of schools, libraries, and documentaries, and are increasingly leveraging mobile applications and chatbots to enhance visitor experiences. However, these chatbots are generally available for only a few languages, due to a lack of linguistic and technical resources for minority languages like Scottish Gaelic.
How can I contribute?
If you speak Scottish Gaelic and live in Scotland, you can take our short comprehension quiz (5-10 minutes) and sign up to participate in the study! The full study (after the quiz) takes up to two hours to complete, and participants will receive up to £30 in compensation for their contribution. Additionally, you’ll have the opportunity to be named as contributing to this important Gaelic resource if you so desire! More details here: https://nlg.napier.ac.uk
If you don’t speak Scottish Gaelic or live outside of Scotland, you can share this blogpost with all the Gaelic speakers you know! Encourage them to participate or to spread the word to their friends. All in all, we hope to recruit about 100 people to participate in our study, and we have a ways to go before we reach this goal. If you don’t know what to say to your contacts, how about:
Researchers in Edinburgh are trying to build the first chatbots for Scottish Gaelic and they’re recruiting participants for an experiment paying up to £30! Find out more at: https://blogs.ed.ac.uk/garg/2022/08/23/scottish-gaelic-chatbots-for-museum-exhibits/ or sign up at https://nlg.napier.ac.uk
For an automatic translation into English, click here. For a version in Irish, click here.
15 Am Faoilleach 2022
Ùghdar: Dr Andrea Palandri, Rannsaiche Iar-Dhotaireil
Andrea Palandri
As t-samhradh 2021, fhuair Gaois maoineachadh fo sgeama AHRC-IRC gus pròiseact a thòiseachadh air a’ Phrìomh Chruinneachadh Làmh-sgrìobhainnean bho thasg-lann Coimisean Beul-aithris na h-Èireann (Cumann Béaloideasa Éireann, University College Dublin). Canar Decoding Hidden Heritages ris a’ phròiseact seo. Is e cuspair a’ bhlog seo an obair dhigiteachaidh a tha a’ dol air adhart mar phàirt den phròiseact air làmh-sgrìobhainnean a’ Phrìomh Chruinneachaidh.
Thathas a’ meas gu bheil timcheall air 700,000 duilleag làmh-sgrìobhainn anns a’ Phrìomh Chruinneachadh Làmh-sgrìobhainnean, ga fhàgail mar aon de na cruinneachaidhean as motha de stuth beul-aithris air taobh an iar na Roinn Eòrpa. Bhiodh seo air a bhith na dhùbhlan mòr airson digiteachadh mura biodh Transkribus air teicneòlas AI airson aithne làmh-sgrìobhaidh a leasachadh thar nam beagan bhliadhnaichean a dh’fhalbh. Tha Decoding Hidden Heritages gu mòr an urra air an teicneòlas seo agus leigidh e leis a’ phròiseact a innealan-aithne làmh-sgrìobhaidh fhèin a dhèanamh stèidhichte air sgrìobhadairean sònraichte sa chruinneachadh.
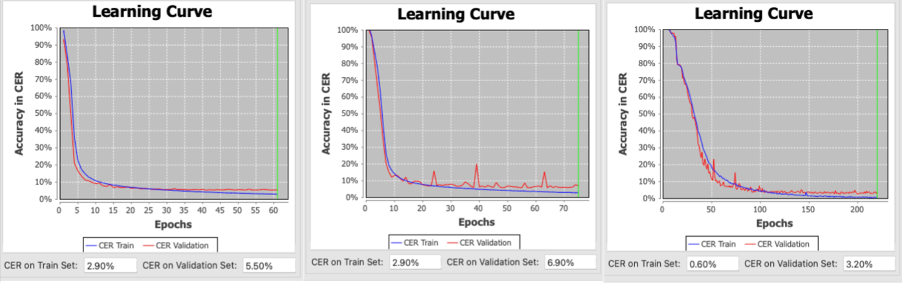
On a thòisich ar luchd-rannsachaidh a bhith ag obair leis a’ bhathar-bog Transkribus tràth san Dàmhair, tha sinn air trì innealan làmh-sgrìobhaidh aithnichte a dhèanamh a tha ag obair aig ìre mionaideachd nas àirde na 95%: aon airson Seosamh Ó Dálaigh, aon airson Seán Ó hEochaidh agus aon airson Liam Mac Coisdealbha, trì de an luchd-cruinneachaidh as dealasaiche a bha ag obair don Choimisean.
Figear 1 (Clí) Seosamh Ó Dálaigh a’ cruinneachadh beul-aithris bho Tomás Mac Gearailt (Paraiste Márthain, Corca Dhuibhne) agus (deas) làmh-sgrìobhainn a sgrìobh e bho chlàradh a rinn e de Tadhg Ó Guithín (Baile na hAbha, Dún Chaoin, Corca Dhuibhne) ga ath-sgrìobh ann an Transkribus.
Tha Transkribus feumail air tar-sgrìobhadh ceart a rèir duilleag na làmh-sgrìobhainne – a rèir làmh-sgrìobhadh agus dual-chainnt an neach-cruinneachaidh – gus an einnsean a thrèanadh. An dèidh a bhith ag aithneachadh timcheall air leth-cheud duilleag san dòigh seo, thrèan sinn modal làmh-sgrìobhaidh aig ìre gu math èifeachdach (90% +). Is e dòigh-obrach a’ phròiseict na dhèidh seo ath-sgrìobhadh a dhèanamh air àireamh mhòr de dhuilleagan gu fèin-ghluasadach agus luchd-taic rannsachaidh (Emma McGee, Kate Ní Ghallchóir agus Róisín Byrne) a chur gan ceartachadh mean air mhean. Na dhèidh sin, faodaidh sinn na modailean a dh’ath-thrèanadh air stòr-dàta nas fharsainge gus modalan cànain nas fheàrr (~ 95%) a fhaighinn. Tha toraidhean eadar-amail na h-obrach seo a’ toirt dòchas dhuinn gum bi e comasach don phròiseact ìre mionaideachd nas àirde a choileanadh anns na mìosan a tha romhainn, a leigeas leinn a bhith ag ath-sgrìobhadh gu fèin-ghluasadach mòran den Phrìomh Chruinneachadh Làmh-sgrìobhainnean cha mhòr thar oidhche.
Figear 2 An lúb ionnsachaidh de mhodalan cànain a chaidh a dhèanamh le Transkirbus gu ruige seo: Seán Ó Dálaigh (clí), Seán Ó hEochaidh (meadhan) agus Liam Mac Coisdealbha (deas).
Tha làmh-sgrìobhainnean a’ Phrìomh Chruinneachaidh am measg nan teacsaichean as motha anns a bheil lorg nan dual-chainntean ann an corpas litreachas Gaeilge an latha an-diugh. Is e dòigh-obrach agus dòighean deasachaidh Shéamuis Ó Duilearga fhèin a tha a’ nochdadh ann an Leabhar Sheáin Í Chonaill. Bhrosnaich agus stèidhidh e Comann Beul-aithris na hÈireann ann an 1927 agus chan eil mìneachadh nas fheàrr air an dòigh-obrach seo na na faclan a sgrìobh Séamus Ó Duilearga fhèin ann an ro-ràdh an leabhair:
Ní raibh ionnam ach úirlis sgríte don tseanachaí: níor atharuíos siolla dá nduairt sé, ach gach aon ní a sgrí chô maith agus d’fhéadfainn é.
Cha robh annam ach inneal sgrìobhaidh dhan t-seanchaidh: cha do dh’atharraich mi lide dhe na thuirt e, ach sgrìobh e a h-uile rud cho math ’s a b’ urrainn dhomh.
(S. Ó Duilearga, Leabhar Sheáin Í Chonaill, xxiv)
Cha deach mòran leabhraichean fhoillseachadh ann an litreachas na Gaeilge bhon uairsin a dh’fhuirich cho dìleas ri dual-chainnt an neach-labhairt ’s a rinn Leabhar Sheáin Í Chonaill: tha cruthan dualchainnteach mar bheadh saé an àite bheadh sé (bhiodh e), no buaileav an àite buaileadh (chaidh a bhualadh) no fáilthiú an àite fáiltiú (fàilteachadh). Mar sin, tha cànan nan làmh-sgrìobhainnean anns a’ Phrìomh Chruinneachadh a’ taisbeanadh dual-chainnt, no eadhon ideo-chainnt, an luchd-fiosrachaidh gu làidir. Mar eisimpleir, bidh claonadh dual-chainnte, do raibh an àite go raibh (gun robh) ga ràdh; bha sin aig cuid de dhaoine à Corca Dhuibhne ann an Chonntaidh Chiarraí, m.e. anns na sgeulachdan a sgrìobh Seosamh Ó Dálaigh bho Thadhg Ó Guithín (Baile na hAbha, Dún Chaoin).
Figear 3 Thug Diarmuid Ó Sé iomradh air an iongantas dualchaint seo ann an Gaeilge Chorca Dhuibhne (§619)
Tha làmh-sgrìobhainnean a’ chruinneachaidh seo car neònach air sàillibh nan cruthan beaga dual-chainnteach a chlàraich an luchd-cruinneachaidh fhad ’s a bha iad gan ath-sgrìobhadh. Is ann air sgàth an iomadachd cànain seo anns a’ chorpas nach eil am pròiseact ag amas air aon mhodail mòr a chruthachadh gus an Cruinneachaidh ath-sgrìobhadh air fad. A bharrachd air sin, chan e a-mhàin gu bheil sinn a’ dèiligeadh ri diofar dhual-chainntean ach tha sinn cuideachd a’ dèiligeadh ri diofar luchd-cruinneachaidh aig nach robh làmh-sgrìobhadh is litreachadh dhual-chainntean co-ionnan. Tha na duilgheadasan seo a’ fàgail gu bheil an corpas Gaeilge seo gu math measgaichte. Feumar dèiligeadh ris le cùram agus le taic bho leabhraichean dhual-chànanachais a bhios a’ toirt cunntas air na puingean beaga cànain a gheibhear ann.
Anns an t-sreath seo, tha sinn a’ toirt sùil air laoich a rinn adhartas cudromach ann an teicneolas nan cànanan Gàidhealach. Airson a’ cheathramh agallaimh, cluinnidh sinn bho Roibeart MacThòmais. Coltach ri Lucy Evans, the Rob air ùr thighinn gu saoghal na Gàidhlig. Chaidh fhastadh airson còig mìosan ann an 2021 mar phàirt de phròiseact a mhaoinich Data-Driven Innovations (DDI), far a robh an sgioba a’ cruthachadh teicneolas aithneachadh labhairt airson na Gàidhlig. Dh’obraich Rob air inneal coimpiutaireachd ùr-nòsach eile, An Gocair.
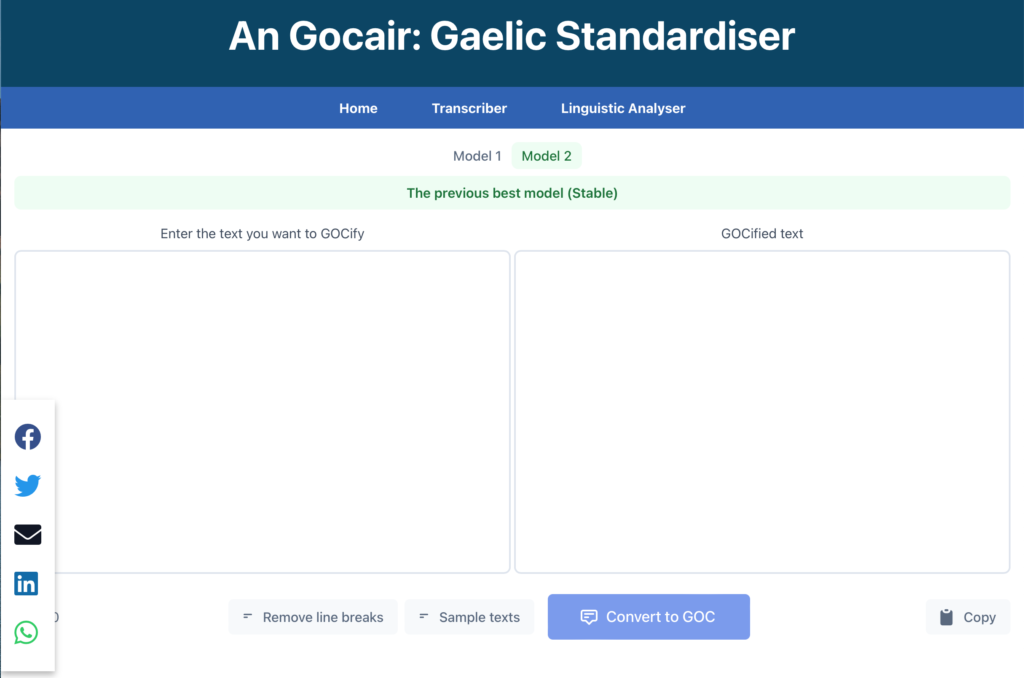
Nuair a bhios tu a’ feuchainn ri teicneòlas cànain a chruthachadh airson mhion-chànain, ’s e an trioblaid as bunasaiche ach dìth dàta. Chan eil an suidheachadh a thaobh na Gàidhlig buileach cho truagh ri cuid a mhion-chànanan eile, ach tha deagh chuid dhen dàta seann-fhasanta a thaobh dhòighean-sgrìobhaidh. Tha sin a’ fàgail nach gabh e cleachdadh gus modailean Artificial Intelligence a thrèanadh gun a bhith a’ cosg airgead mòr air ath-litreachadh.
Bidh An Gocair ag ath-litreachadh theacsaichean gu fèin-obrachail – tha e glè choltach ri dearbhadair-litrichidh. Chan eil ann ach ro-shamhla (prototype) an-dràsta agus tha sinn a’ sireadh taic a bharrachd airson a leasachadh. Aon uair ‘s gum bi e deiseil, b’ urrainnear a chur gu feum ann an iomadach suidheachadh, leithid foillseachadh, foghlam aig gach ìre, prògraman coimpiutaireachd eile agus rannsachadh sgoileireil. Cuiridh e gu mòr cuideachd ri pròiseact rannsachaidh ùr a tha a’ tòiseachadh an dràsta eadar còig oilthighean ann am Breatainn, Ameireaga agus Èirinn: ‘Decoding Hidden Heritages in Gaelic Traditional Narrative with Text-mining and Phylogenetics’.
In this interview series, we are looking at individuals who have significantly advanced the field of Gaelic, Irish and Manx language technology. For the fourth interview, we hear from Mr Rob Thomas. Like Lucy Evans, whom we interviewed a few months ago, Rob has come to the world of Gaelic language technology only recently. He was chosen from a strong field to work with us on project funded by Data-Driven Innovations (DDI), in which we were developing the world’s first automatic speech recogniser for Scottish Gaelic. Rob worked on an important strand of this project – developing a brand-new piece of software called An Gocair.
When trying to develop language technology for minority languages, the most fundamental problem is data sparsity. The situation for Gaelic is not as dire as for some other minority languages, but much of the textual data available is outdated in terms of orthography. That makes it impossible to train machine learning models – at least without spending a lot of money on editing spelling.
An Gocair re-spells texts automatically – it’s basically an unsupervised spell-checker with some extra bells and whistles. It is currently only a prototype, however, and we are seeking additional support for its development. Once completed, it will be able to be used in a wide range of contexts, including publishing, education at all levels, as part of other computer programs and within academic research. It will also make a significant contribution to a new research project currently underway between five universities in Britain, America and Ireland: ‘Decoding Hidden Heritages in Gaelic Traditional Narrative with Text-mining and Phylogenetics’.
Interview with Rob Thomas
Agallamh le Roibeart MacThòmais
Tell us a little bit about your background. For instance, where are you from, and what got you into language technology work?
Hello! I’m from a small town in South Wales called Monmouth. I grew up mostly in the countryside, quite far from civilisation. My interest in linguistics probably stems from having a fantastic English teacher in my high school. (Shout out to Mr Jones.) I don’t know if it was the content or how he taught it, but I remember at the time really enjoying the subject and his lessons.
Rob Thomas
I went on to study English Language and Linguistics at the University of Portsmouth. After graduating, I worked for a while at Marks and Spencer as I was not yet sure what kind of career I was looking for. Still kind of directionless, I spent a year and a bit traveling and on return began working in tech support. I managed to find a course in Language Technology at the University of Gothenburg, I had recently found a new interest in programming and this was a great way to merge my new interest and my academic foundation. After a few years living, studying and working in Sweden, I returned to the UK and began the job hunt and was lucky to find the position at the University of Edinburgh.
You mention studying language technology at the University of Gothenburg. What did you find most interesting about the course? Do you have any advice for someone who is thinking about studying language technology?
The course was fascinating and it attracted students from quite a broad background. The first meeting was like The Time Machine by H.G Wells: we were all introduced as the linguist or the mathematician, cognitive scientist, computer scientist, philosopher etc. I think what stood out is that language technology, as a field, relies on input and experience from a multitude of academical backgrounds. This is due to the complex nature of language. I think I would advise anyone who is not from a technical or STEM background to think about how important your knowledge and perspective is for the future of language-based AIs, systems and services. But if, like me, you do come from a humanities background be prepared to dive straight back in to the maths that you thought you managed to escape after you completed your GCSEs.
You are developing a tool for Scottish Gaelic that automatically corrects misspelled words and makes text conform to a Gaelic orthographical standard. That’s impressive for someone with Gaelic, and even more so for someone who doesn’t speak it. How did you manage to do this?
I am quite lucky to be supported by Gaelic linguists and other programmers. I found a way to integrate Am Faclair Beag, an online Gaelic dictionary developed by our resident Gaelic domain expert, Michael Bauer. Alongside the dictionary we translated complicated linguistic rules into something a computer could understand. We have managed to develop a program that takes a text and, line by line, attempts to identify spelling that don’t belong to the modern orthography and searches for the right word from our dictionary. If it has no luck, it then attempts to resolve the issue algorithmically. From the start I knew it was important that I was able to compare the program’s output to work done by Gaelic experts so that I could see whether I was improving the tool or just breaking it.
An Gocair
Since you’ve been born, you’ve seen language technology change and permeate how we work and live. What’s been your own experience of the changes that it has brought?
It has been very interesting witnessing the exponential growth of language technology in the mainstream. It wasn’t until I studied it that I realised how much it was already embedded in websites and services that I’ve been using for years. The more visible applications such as smart assistants are becoming much more normalised in our society. Even my grandma uses her smart assistant to turn on classic FM and put on timers which I think is really cool. My grandma is pretty tech savvy to be fair!
With the dominance of world languages in mass media and on the internet, some would say that technology is an existential threat to minority languages like Gaelic and Welsh. What do you think about this? Are there ways for minority languages to survive or even thrive today?
I think one of the issues in language technology is that most of the work is dedicated to languages that already have huge amounts of resources, for example English. Most of the breakthroughs are being made by large companies that ultimately aim to increase the value of their services. There are a lot of companies that sell language technology as a service (e.g. machine translation) rather than serving communities per se. The latter may not have direct monetary value, but it’s essential to keep that focus in order to allow minority languages to gain access to state-of-the-art technology.
What are your predications for language technology in the year 2050? If you had your own way, what would you like to see by that time?
I imagine smart assistants will be present in more spaces in society, perhaps even in a more official capacity. The county council in Monmouthshire already use a smart chatbot for questions about what days your bins are being collected. Imagine if they were given greater powers such as being able to make important decisions (scary thought). The more time goes on, the more I think we are going to end up with malevolent AIs like HAL from 2001, Space Odyssey, rather than ones like C3PO from Star Wars.
I’m not sure what I would like to see. It would be nice if there was more community-developed and open-source alternatives to what the main large tech companies provide, so a consumer would be able to be sure their data was being used in a safe and respectable way.
Decoding Hidden Heritages in Gaelic Traditional Narrative with Text-Mining and Phylogenetics
This exciting new three-year study is funded by the AHRC and IRC jointly under the UK–Ireland collaboration in digital humanities programme. It brings together five international universities, two folklore archives and two online folklore portals.
October 2021–Sept 2024
‘Morraha’ by John Batten. From Celtic Fairy Tales (Jacobs 1895)
Summary
This project will fuse deep, qualitative analysis with cutting-edge computational methodologies to decode, interpret and curate the hidden heritages of Gaelic traditional narrative. In doing so, it will provide the most detailed account to date of convergence and divergence in the narrative traditions of Scotland and Ireland and, by extension, a novel understanding of their joint cultural history. Leveraging recent advances in Natural Language Processing, the consortium will digitise, convert and help to disseminate a vast corpus of folklore manuscripts in Irish and Scottish Gaelic.
The project team will create, analyse and disseminate a large text corpus of folktales from the Tale Archive of the School of Scottish Studies Archives and from the Main Manuscript Collection of the Irish National Folklore Collection. The creation of this corpus will involve the scanning of c.80k manuscript pages (and will also include pages scanned by the Dúchas digitisation project), the recognition of handwritten text on these pages (as well as some audio material in Scotland), the normalisation of non-standard text, and the machine translation of Scottish Gaelic into Irish. The corpus will then be annotated with document-level and motif-level metadata.
Analysis of the corpus will be carried out using data mining and phylogenetic techniques. Both the data mining and phylogenetic workstreams will encompass the entire corpus, however, the phylogenetic workstream will also focus on three folktale types as case studies, namely Aarne–Thompson–Uther (ATU) 400 ‘The Search for the Lost Wife’, ATU 425 ‘The Search for the Lost Husband’, and ATU 503 ‘The Gifts of the Little People’. The results of these analyses will be published in a series of articles and in a book entitled Digital Folkloristics. The corpus will be disseminated via Dúchas and Tobar an Dualchais, and via a new aggregator website (under construction) that will include map and graph visualisations of corpus data and of the results of our analysis.
Project team
UK
Principal Investigator Dr William Lamb, The University of Edinburgh (School of Literatures, Languages and Cultures)
Co-Investigator Prof. Jamshid Tehrani, Durham University (Department of Anthropology)
Co-Investigator Dr Beatrice Alex, The University of Edinburgh (School of Literatures, Languages and Cultures)
University of Edinburgh
Language Technician, Michael Bauer
Louise Scollay, Copyright Administrator
Ireland
Co-Principal Investigator Dr Brian Ó Raghallaigh, Dublin City University (Fiontar & Scoil na Gaeilge)
Co-Investigator Dr Críostóir Mac Cárthaigh, University College Dublin (National Folklore Collection)
Co-Investigator Dr Barbara Hillers, Indiana University (Folklore and Ethnomusicology)
While some of our research group has been busy creating the world’s first Scottish Gaelic Speech Recognition system, others been creating the world’s first Scottish Gaelic Text Normaliser. Although it might not turn the heads of AI enthusiasts and smart device lovers in the same way, the normaliser is an invaluable tool for unlocking historical Gaelic, enhancing its use for machine learning and giving people a way to correct Gaelic spelling with no hassle.
Rob Thomas
Why do we need a Gaelic text normaliser? Well, this program takes pre-standardised texts, which can vary in their orthography, and rewrites them in the modern Gaelic Orthographic Conventions (GOC). GOC is a document published by the SQA which details the modern standards for writing in Gaelic. Text normalisation is an important step in text pre-processing for machine learning applications. It’s also useful when reprinting older texts for modern readers, or if you just want to quickly spellcheck something in Gaelic.
I joined the project towards the end and have been fast at work trying to understand Gaelic orthography, how it has developed over the centuries, and what is possible in regards to automated normalisation. I have been working alongside Michael ‘Akerbeltz’ Bauer, a Gaelic linguist with extensive credentials. He has literally written the dictionary on Gaelic as well as a book on Gaelic phonology: it is safe to say I am in good hands. We have been working together to find a way of teaching a program exactly how to normalise Gaelic text. Whereas a human can explain why a word should be spelt a specific way, programming this takes quite a bit of figuring out.
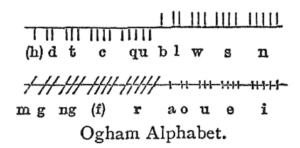
An early ancestor to Scottish Gaelic (Archaic Irish) was written in Ogham, and interestingly enough was carved vertically into stone.
Luckily historical text normalisation is a well-trodden path, and there are plenty of papers and theses online to help. In her thesis, Eva Pettersson describes four main methods for normalising text and, inspired by these, we got started. The first method relies on possessing an extensive lexicon of the target language, which we so happen to have, thanks to Michael.
Lexicon Based Normalisation
This method relies upon having a large lexicon stored that can cover the majority of words in the target language. Using this, you can check to see if a word is spelt correctly, whether it is in a traditional spelling, or if the writer has made a mistake.
The advantage of this method is that you do not have to be an expert in the language yourself (lucky for me!). Our first step was finding a way to integrate the world’s most comprehensive digital Scottish Gaelic dictionary, Am Faclair Beag. The dictionary contains traditional and misspelt words mapped to their correct spellings. This meant that we can have the program go through a text and swap words if it identifies one that needs correcting.
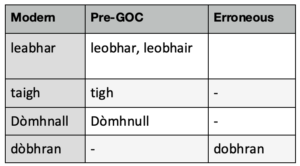
The table above shows some modern words with pre-GOC variants or misspellings. Michael has been collecting Gaelic words and their spelling variants for decades. If our program finds a word that is ‘out of dictionary’, we pass it on to the next stage of normalisation, which involves the hand crafting of linguistic rules.
‘An Gocair’
Rule-based Text Normalisation
Once we have filtered out all of the words that can be handled by our lexicon alone, we try to make use of linguistic rules. It’s not always easy to program a rule so that a computer can understand it. For example, we all know the English rule ‘i before e except after c’ (which of course is an inconsistent rule in English). We can program this by getting the computer to catch all the i’s before e’s and make sure they don’t come after a c.
With guidance from Michael, we went about identifying rules in Gaelic that can be intuitively programmed. One common feature of traditional Gaelic is the replacement of vowels with apostrophes at the end of words if the following word begins with a vowel. This is called ellipsis and is due to the fact that, if one were to speak the phrase, one wouldn’t pronounce both vowels: the writer is simply writing how they would speak. For example, native Gaelic speakers wouldn’t say is e an cù a tha ann ‘it is the dog’: they would say ’s e ’n cù a th’ ann, dropping three vowels. But in writing, we want these vowels to appear – at least for most machine learning situations.
It is not always straightforward working out which vowel an apostrophe replaces, but we can use a rule to help us. Gaelic vowels come in two categories, broad (a, o, u) and slender (e, i). In writing, vowels conform to the ‘broad to broad and slender to slender rule’, so when reinstating a vowel at the end of a word we need to check the form of the first vowel to the left of our apostrophe and ensure that, if it is a broad vowel, we add in a matching vowel.
Pattern Matching with Regular Expression
For this method of normalisation we make use of regular expressions for catching common examples that require normalisation, but are not covered by the lexicon or our previous rules. For example, consider the following example, which is a case of hyper-phonetic spelling, when a person writes like they speak:
Tha sgian ann a sheo tha mis’ a’ toir dhu’-sa.
Here, the word mis’ is given an apostrophe as a final character, because the following word begins with a vowel. GOC suggests that we restore the final vowel. To restore this vowel, we’re helped by the regularity of the Gaelic orthography, a form of vowel harmony, whereby each consonant has to be surrounded either by slender letters (e, i) or broad letters (a, o, u). So in the example above we need to make sure the final vowel of mis’ is a slender vowel (mise), because the first vowel to the left is also slender. We have managed to program this and, using a nifty algorithm, we can then decipher what the correct word should be. When the word is resolved we check to see if the resolved form is in the lexicon and if it is, we save it and move on to the next word.
Evaluation
Now you might be wondering how I managed to learn Scottish Gaelic so comprehensively in five months that I was able to write a program that corrects spelling and also confirm that it is working properly. Well, I didn’t. From the start of the task, I knew there was no way I would be able to gain enough knowledge about the language that I could confidently assess how well the tool was performing. Luckily I did have a large amount of text that was corrected by hand, thanks to Michael’s hard work.
To be able to verify that the tool is working, I had to write some code that automatically compares the output of the tool to the gold standard that Michael created, and then provide me with useful metrics. Eva Peterssonn describes in her thesis on Historical Text Normalisation two such metrics: error reduction and accuracy. Error reduction provides you with the percentage of errors in a text that are successfully corrected using the following formula:
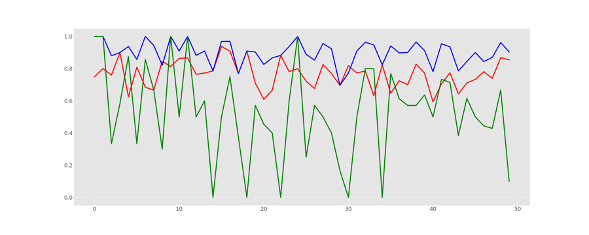
Accuracy simply evaluates the number of words in the gold standard text which has an identical spelling in the normalised version. Below you can see the results of normalisation on a test set of sentences. The green line shows the percentage or errors that are corrected whilst the red and blue line show the accuracy before and after normalisation, respectively. As you can see the normaliser manages to successfully improve the accuracy, sometimes even to 100%.
From GOC to ‘An Gocair’
With a play of words on GOC, we have named the program An Gocair ‘The Un-hooker’. We have tried to make it as easy as possible to update it with new rules. We hope to have the opportunity to create more rules in the future ourselves. The program will also improve with the next iteration of Michael’s fabulous dictionary. We hope to release the first version of An Gocair to the world by the end of October 2021. Keep posted!
Acknowledgement
This program was funded by the Data-Driven Innovation initiative (DDI), delivered by the University of Edinburgh and Heriot-Watt University for the Edinburgh and South East Scotland City Region Deal. DDI is an innovation network helping organisations tackle challenges for industry and society by doing data right to support Edinburgh in its ambition to become the data capital of Europe. The project was delivered by the Edinburgh Futures Institute (EFI), one of five DDI innovation hubs which collaborates with industry, government and communities to build a challenge-led and data-rich portfolio of activity that has an enduring impact.
The Celtic Linguistics Group at the University of Arizona invited Dr Will Lamb to speak to them about ‘Emerging NLP for Scottish Gaelic’ on 26 March 2021. This was as part of their Formal Approaches to Celtic Linguistics lecture series. The talk went out on Zoom and was recorded and uploaded on YouTube (provided below). About 43 min into the video, there is a short demonstration of the prototype ASR system, as it stood at the time. Since then, we have improved the system further, incorporating enhanced acoustic and language models, and a post-processing stage that re-inserts much punctuation back into the output.

![Image shows metadata, a PDF and AI-recognised text for the Scottish Gaelic tale 'Biast na[n] Naoi Ceann' ['Beast of the Nine Heads']](https://blogs.ed.ac.uk/garg/wp-content/uploads/sites/1179/2025/06/Screenshot-2025-06-05-at-11.14.05.png)