
English speakers never have to worry about grammatical gender – nouns are just nouns. When I began learning Gaelic in my early twenties, getting to grip with grammatical gender was a challenge. Until I learnt some of the patterns intuitively, I had to look up every new noun in the dictionary to determine its gender, and add this information to my stack of flash cards. As it happens, computers also struggle with identifying gender. When we built the first part-of-speech tagger for Gaelic a few years ago, gender was one of the things that our statistically-based model often got wrong.
Some grammars supply a list of suffixes that are typically feminine or masculine, and these can be helpful to new students of Gaelic. For instance, once you know that just about all nouns ending in -chd are feminine, you can take a new noun with that suffix and be relatively confident about how to use it. In the grammar at the end of my 2008 book, Scottish Gaelic Speech and Writing, I list (pp 206-207) the suffixes provided by Calder (1923: 76-77):
- Masc: -adh, -an/-ean, -as, -ach, -aiche, and -air.
- Fem: -ag, -achd/-eachd, -ad, /-ead, -e, and -ir (for polysyllables only)
But how reliable are these endings for predicting gender? And what proportion of nouns ending in a particular suffix takes the expected gender? Furthermore, are there any Gaelic suffixes that are useful for predicting gender that Gaelic grammarians haven’t noticed already?
Over the last few months, I’ve been assembling some code and resources that will allow me to do some new research on Gaelic grammar. Thanks to Michael Bauer of Am Faclair Beag, I have a large list of Gaelic words accompanied by useful lexicographical info. Last night, I wondered how well a machine learning algorithm could model the relationships between Gaelic orthography and gender.
I began by extracted all the nouns from the lexicon (17207 nouns total) along with their gender, and put them into a Python list of tuples, like this:
[('eigheantach', 'f'), ('dìobhairt', 'm'), ('faoinsgeulachd', 'f'), ('còmhnardachadh', 'm'), ('inneal-spreagaidh', 'm')...]
Then I randomised the noun list – which simply included the root form and its gender – and divided it into a training (90%) and and testing set (10%). I defined three features: 1) the last letter; 2) the last two letters and 3) the last three letters. I then built a model using a Naive Bayes Classifier from the Python package, NLTK.
When applied to the test set, the model was about 83% accurate. So, knowing the ending of Gaelic noun can definitely help if you are trying to determine its gender. Putting this in an POS tagging context, if your tagger can’t guess the gender of a word because it hasn’t seen the word before, you could use a model like this to hazard a guess and be accurate most of the time.
Calling up the most informative features from the model confirmed many expectations, but also some patterns that I didn’t expect. These are the 30 most informative features of the model – all with ratios of 10:1 or more (i.e. these endings are at least 10 times more likely to be one gender than the other):
>>> classifier.show_most_informative_features(30) suffix2 = 'ag' f : m = 84.9 : 1.0 suffix3 = 'eag' f : m = 72.9 : 1.0 suffix3 = 'adh' m : f = 72.6 : 1.0 suffix3 = 'has' m : f = 70.6 : 1.0 suffix3 = 'nag' f : m = 54.2 : 1.0 suffix3 = 'tag' f : m = 40.2 : 1.0 suffix3 = 'rag' f : m = 37.1 : 1.0 suffix3 = 'eid' f : m = 36.3 : 1.0 suffix3 = 'gan' m : f = 34.3 : 1.0 suffix2 = 'an' m : f = 24.7 : 1.0 suffix3 = 'ear' m : f = 24.7 : 1.0 suffix3 = 'lag' f : m = 21.9 : 1.0 suffix3 = 'chd' f : m = 21.6 : 1.0 suffix2 = 'hd' f : m = 21.0 : 1.0 suffix2 = 'on' m : f = 20.3 : 1.0 suffix3 = 'ilt' f : m = 19.9 : 1.0 suffix2 = 'ar' m : f = 17.6 : 1.0 suffix3 = 'ing' f : m = 16.1 : 1.0 suffix3 = 'tan' m : f = 15.2 : 1.0 suffix3 = 'ait' f : m = 14.7 : 1.0 suffix3 = 'ean' m : f = 14.3 : 1.0 suffix2 = 'as' m : f = 14.2 : 1.0 suffix3 = 'oil' f : m = 14.2 : 1.0 suffix3 = 'lan' m : f = 13.7 : 1.0 suffix3 = 'ith' f : m = 12.7 : 1.0 suffix2 = 'am' m : f = 12.2 : 1.0 suffix3 = 'tar' m : f = 11.3 : 1.0 suffix3 = 'ram' m : f = 11.0 : 1.0 suffix2 = 'al' m : f = 10.9 : 1.0 suffix3 = 'oin' f : m = 10.8 : 1.0
It is easier to view these in bar plots. Here are 14 most typically feminine suffixes (the y axis shows the ratio ‘x:1’):
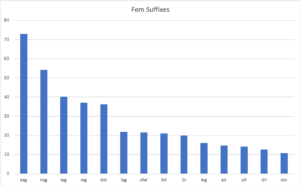
And here are the 15 most typically masculine ones:
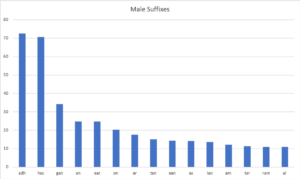
There is some crossover here clearly (e.g. –eag, -nag, -tag, -rag and -lag are all forms of the diminutive female suffix –ag), so the model could be better specified. But these tell us that gender in Gaelic is well encoded in the suffix. For example, if you see a noun that ends with -adh, it is 76 times more likely to be masculine than feminine. Indeed, there are very few feminine nouns in the lexicon that end with -adh:
>>> [noun for (noun,gender) in nounslow if noun.endswith('adh') and gender == 'f']
['cneadh', 'dearg-chriadh', 'leasradh', 'stuadh', 'speireag-ruadh', 'muirgheadh', 'buadh', 'riadh', 'criadh', 'ealadh', 'pìob-chriadh', 'ceòlradh', 'roinn-phàigheadh']
These results can be generalised as:
- Masc nouns tend to end in: -adh, -as, -an, -ar, -am, -al and broad consonant or clusters (e.g. -al), except for a vowel + –g
- Fem nouns tend to end in: –ag, -chd and slender consonants or clusters (e.g. –ilt, ing, -in, -il)
As any intermediate Gaelic learner knows, a good rule to follow is that masc nouns end broad and feminine nouns end slender. But are there any exceptions? Well, we already saw that nouns ending in -ag, -achd are largely feminine. Are there any others? Digging a little deeper into the model, we find the following (ratios rounded to whole numbers):
- Fem: –ìob (7:1), -ng (7:1), –lb (6:1)
- Masc: –che (6:1)
Calder had the last one already (e.g. fulangaiche), but he didn’t notice that combinations of a sonorant (l, n, r) and the non-aspirated stops (b and g) tend to be feminine – words like fang and sgealb.
With the model, we can check to see what it would make of a made-up word — how it might classify a nonce word or unusual dialectal form, for instance — if we used it as part of a part-of-speech tagger:
>>> classifier.classify(gender_features('brùthang'))
'f'
All in all, this is useful and — if you are a language geek — pretty interesting stuff. What is exciting about doing NLP with Gaelic is that, while this type of work is old hat for many languages now, it is brand new for Scottish Gaelic.
So, by generating this model and testing it upon a hold-out of 10% of the nouns in the lexicon, we have shown that it confirms certain expectations, discovers some unexpected patterns in the language, allows us to quantify relationships and provides a pragmatic solution to the quandary of how to guess the gender of unknown words as part of an NLP pipeline.
Code
(NB: nounslow is the list of nouns in lowercase)
def gender_features(word):
... return{'suffix1': word[-1:],
... 'suffix2': word[-2:],
... 'suffix3': word[-3:]}
...
>>> featuresets = [(gender_features(n.lower()), gender) for (n, gender) in nounslow]
>>> train_set, test_set = featuresets[:size], featuresets[size:]
>>> classifier = nltk.NaiveBayesClassifier.train(train_set)
>>> print(nltk.classify.accuracy(classifier, test_set))
0.8256827425915165
