
By Lucy Evans
Since September 2020, a collaborative team from the University of Edinburgh (UoE), the University of the Highlands and Islands (UHI), and Quorate Technology, has been working towards building an Automatic Speech Recognition (ASR) system for Scottish Gaelic. This is a system that is able to automatically transcribe Gaelic speech into writing.
The applications for a Gaelic ASR system are vast, as demonstrated by those already in use for other languages, such as English. Examples of applications include voice assistants (Alexa, Siri), video subtitling, automatic transcription, and so on. Our goal for this project is to build a full working system for Gaelic in order to facilitate these types of use-cases. In the long term, for example, we hope to enable the automatic generation of transcripts and/or subtitles for pre-existing Gaelic recordings and videos. This would add value to these resources by rendering them searchable by word or topic. In this blog post, we describe our progress so far.
Data and Resources
There are 3 main components needed to construct a full ASR system. These comprise the lexicon, which maps words to their component phonemes (e.g. hello = hh ah l ow), the language model, which identifies likely sequences of words in the target language, and the acoustic model, which learns to recognise the component phonemes making up a segment of speech. The combination of these three components enables the ASR system to pick up on a sequence of phonemes in the input speech, map these phonemes to written words, and output a full predicted transcription of the recording.
| Input | Output Prediction | |
| Language Model | The United States of <?> | America |
| Acoustic Model | Audio (Speaker says “Good Morning”) | g uh d m ao r n ih ng |
Of course, building these components requires resources. In terms of the lexicon, we are fortunate enough to have this resource already available to us. Am Faclair Beag is a digital Gaelic dictionary, developed by Michael Bauer, which includes phonetic transcriptions for over 30,000 Gaelic words. We simply pulled each word and pronunciation from this dictionary and combined them into a list to serve as our initial lexicon.
For training our language model (LM), we required a large corpus of Gaelic text. A LM counts occurrences of every 4-word sequence present in this text corpus, so as to learn which phrases are common in Gaelic. The following resources were drawn upon to build this:
- The School of Scottish Studies Archives (UoE), which has provided hundreds of digitised manuscripts (via the earlier project, Building a Handwriting Recogniser for Scottish Gaelic)
- The gd Corpus, which is a web-scraped text corpus assembled as part of the An Crúbadán project. This project aims to build corpora and other language technology resources for minority languages
- Tobar an Dualchais/Kist o Riches, a collaborative project which aims to “preserve, digitise, catalogue and make available online several thousand hours of Gaelic and Scots recordings”. They supplied several hundred transcriptions of archive material from the School of Scottish Studies Archives
Finally, for training the acoustic model, we required a large number of speech recordings along with their corresponding transcriptions. This is so that the model can learn (with help from the lexicon) how the different speech sounds map to written words. We used recordings and transcriptions from the following sources to construct this dataset:
- The School of Scottish Studies Archives (UoE) – see above
- Clilstore, an educational website that provides Gaelic language videos at various different CEFR levels
A note on alignment
In order to train our ASR system to map speech sounds to written words, we must time-align each transcription to its corresponding recording. In other words, the transcriptions must be given time-stamps, specifying when each transcribed word occurs in the recording.
Time-aligning the transcriptions manually is lengthy and expensive, so we generally rely on automatic methods. In fact, we use a method very similar to speech recognition to generate these alignments. The issue here is that the automatic aligner also requires time-aligned speech data for training, which we don’t have for Gaelic.
We are fortunate in that we have been able to use a pre-built English speech aligner from Quorate Technology to carry out our Gaelic alignment task. As this was trained on English speech, it may be surprising that it is still effective for aligning our Gaelic data. However, despite noticeable high-level differences between the two languages (words, grammar etc.), the aligner is able to pick up on the lower-level features of speech (pitch, tone etc.), which are global across different languages. This means it can make a good guess at when specific words occur in each recording.
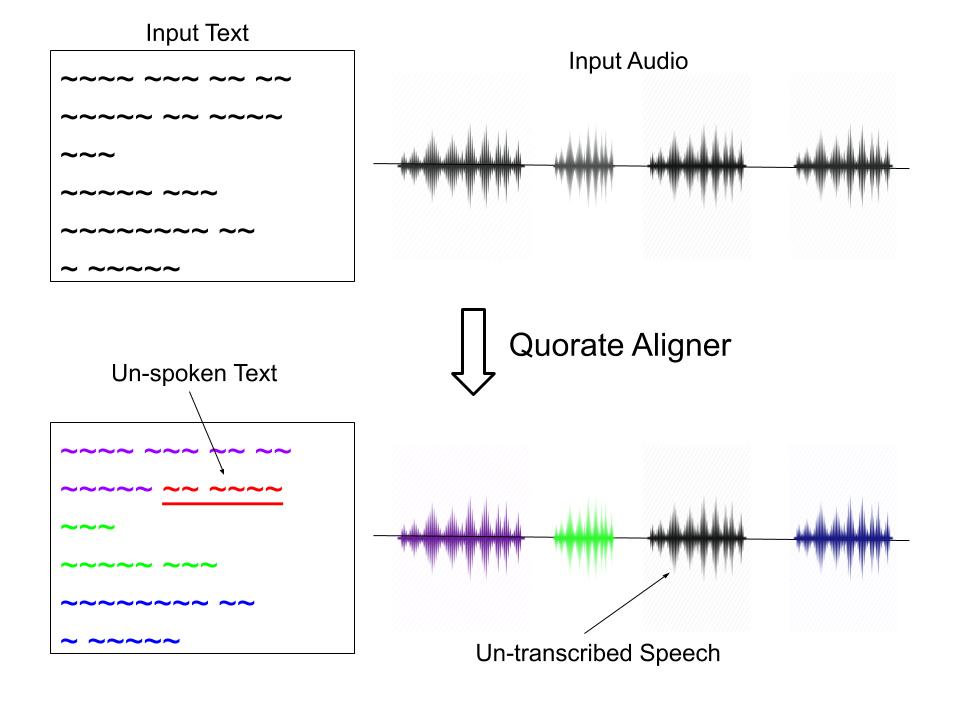
The alignment process – mapping text to audio.
Adapting the Lexicon
1. Mapping from IPA to the Aligner Phoneset
Because we are using a pre-built aligner on our speech data, we must ensure that the set of phones used to phonetically transcribe the words in our lexicon is the same as the set of phones recognised by the aligner’s acoustic model. Our lexicon, from Am Faclair Beag, uses a form of Gaelic-adapted IPA, whereas the Quorate aligner recognises a special, computer-readable set of English phones. For this reason, our first task was to map each phone in the lexicon’s phoneset to its equivalent (or closest) phone used in the aligner’s phoneset.
We first standardised the lexicon phoneset, mapping each specialised Gaelic IPA phone back to its standard IPA equivalent. We next mapped this standard IPA phoneset to ARPABET, an American-English phoneset that is widely used in language technology. This is the foundation of the aligner’s phoneset. We had to draw on our phonetic knowledge of Gaelic to create the mapping from IPA to ARPABET, because the set of phones used in English speech differs to that used in Gaelic: some Gaelic phones do not exist in English. For each additional Gaelic phone, we therefore selected the ARPABET phone that was deemed its ‘closest match’. Take the following Gaelic distinction between a non-aspirated, palatalised ( kʲ ) and non-aspirated non-palatalised ( k ) stop consonant, for example:
| Gaelic IPA
(Gaelic phoneset) |
Standard IPA
(global phoneset) |
ARPABET
(English phoneset) |
| g | k | K |
| gʲ | kʲ | K |
Our final mapping was from ARPABET to the aligner’s phoneset. Considering both of these phonesets are based on English, this was a fairly easy process; each ARPABET phone had an exact equivalent in the aligner phoneset. Once we had our final phoneset mapping, we converted all the phonetic transcriptions in the lexicon to their equivalent in the aligner’s phoneset, for example:
| Word | Original
(Gaelic IPA) |
Standard IPA | ARPABET | Aligner |
| uisge | ɯ ʃ gʲ ə | ɯ ʃ kʲ ə | UX SH K AX | uh sh k ax |
| gorm | g ɔ r ɔ m | k ɔ ɾ ɔ m | K AO DX AO M | k ao r ao m |
2. Adding new pronunciations
For our ASR system to learn to recognise the component phones of spoken words, we need to ensure that every word that appears in our training corpus is included in the lexicon.
Our initial phoneticised lexicon stood at an impressive 30,000 Gaelic words, however, the number of words in our training corpus exceeds 150,000. This leaves 120,000 missing pronunciations, many of which will simply be morphological variations on the dictionary entries. If our model were to come across any of these words in training, it would be unable to map the acoustics of that word to its component phoneme labels.
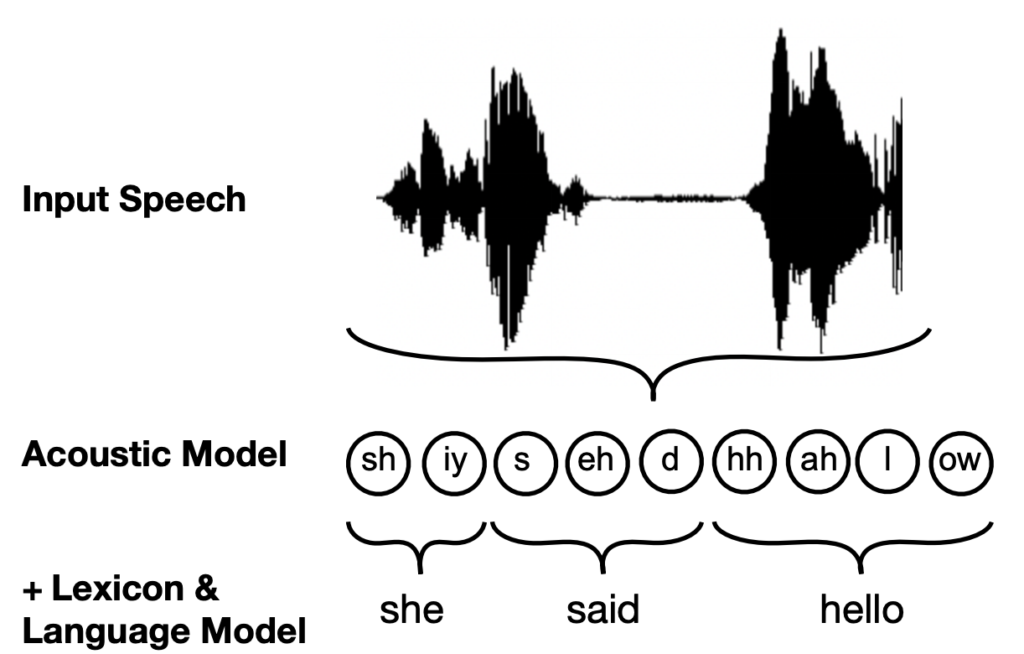
The ASR system maps the phones recognised by the acoustic model to words, using the pronunciations in the lexicon.
A solution to this is to train a Grapheme-to-Phoneme (G2P) model, which, given a written word as input, can predict a phonetic transcription for that word, based solely on the letters (graphemes) it contains. For example:
| Input | Output Prediction |
| h-uisgeanan | hh uh sh k ih n aa n |
| galachan | k aa el ax k aa n |
| fuaimeannan | f uw ax iy m aa en aa n |
We trained a G2P model using all the words and pronunciations already in our lexicon. The model learns typical patterns of Gaelic grapheme to phoneme mappings using these as examples. Our model achieved a symbol error rate of 3.82%, which equates to an impressive 96.18% accuracy. We subsequently used this model to predict the pronunciation for the 120,000 missing words, and added them to our lexicon.
Text Normalisation
1. Punctuation, Capitalisation, and other Junk
Our next tasks focused on normalising our text corpus. We want to ensure that any text we input to our language model is free from punctuation and capitalisation, so that the model does not distinguish between, for example, a capitalised and lowercase word (e.g. ‘Hello’ vs. ‘hello’), where the meaning of these tokens is actually the same. A simple Python programme was written for this purpose which, along with punctuation and capitalisation, also stripped out any junk, such as turn-taking indicators. Here is an example of the programme at work:
| Input | Output |
| A’ cur uèirichean ri pluga. | a cur uèirichean ri pluga |
| An ann ro theth a bha e? | an ann ro theth a bha e |
| EC―00:05: Dè bha ceàrr air, air obair a’ bhanca? | dè bha ceàrr air air obair a bhanca |
2. Digit Verbalisation
Another useful type of text normalisation is the verbalisation of digits. Put simply, this involves converting any digits in our corpus into words, for example, ‘42’ -> ‘forty-two’. An easy way of doing this is by using a Python tool called num2words. The tool is functional for verbalising digits into numerous languages, but unfortunately did not support Gaelic. For this reason, we coded our own Gaelic digit verbaliser, in order to verbalise the digits present in our text corpus. As the num2words projects welcomes contributions, we also hope to be able to contribute our code, so as to make the tool accessible to others.
Our digit verbaliser is currently functional for the numbers 0-100, and for the years 1100-2099. Also, as Gaelic uses both the decimal (10s) and vigesimal (20s) numbering systems, we ensured that our tool is able to verbalise each digit using either system, as specified by the user. We hope to eventually extend this to a wider range of numbers. The following examples show our digit verbaliser at work:
a) Numbers
| Original | Uill, tha, tha messages na seachdaine a chaidh agam ri phàigheadh agus bidh e timcheall air mu 80 pounds. |
| Vigesimal | Uill, tha, tha messages na seachdaine a chaidh agam ri phàigheadh agus bidh e timcheall air mu ceithir fichead pounds. |
| Decimal | Uill, tha, tha messages na seachdaine a chaidh agam ri phàigheadh agus bidh e timcheall air mu ochdad pounds. |
b) Years
| Original | Bha, bha e ann am Poll a’ Charra ann an 1860. |
| Vigesimal | Bha, bha e ann am Poll a’ Charra ann an ochd ceud deug, trì fichead. |
| Decimal | Bha, bha e ann am Poll a’ Charra ann an ochd ceud deug ‘s a seasgad. |
Current Work and Next Steps
After carrying out all the data and lexicon preparation, we were able to align our Gaelic speech data using Quorate’s English aligner. We have started using this to train our first acoustic models, and will soon be able to build our first full speech recognition system – keep an eye out for our next update!

Automatically subtitled video (using provided script)
However, aside from creating acoustic model training data, alignment can actually be useful for other purposes: it enables us to create video subtitles, for example. This kind of use case actually enables us to present our first observable results, which have been extremely encouraging. The videos in the link below exhibit our time-aligned subtitles, originally a simple transcription, separated from the video: click here to see examples of our work so far!