
By Rob Thomas
While some of our research group has been busy creating the world’s first Scottish Gaelic Speech Recognition system, others been creating the world’s first Scottish Gaelic Text Normaliser. Although it might not turn the heads of AI enthusiasts and smart device lovers in the same way, the normaliser is an invaluable tool for unlocking historical Gaelic, enhancing its use for machine learning and giving people a way to correct Gaelic spelling with no hassle.

Rob Thomas
Why do we need a Gaelic text normaliser? Well, this program takes pre-standardised texts, which can vary in their orthography, and rewrites them in the modern Gaelic Orthographic Conventions (GOC). GOC is a document published by the SQA which details the modern standards for writing in Gaelic. Text normalisation is an important step in text pre-processing for machine learning applications. It’s also useful when reprinting older texts for modern readers, or if you just want to quickly spellcheck something in Gaelic.
I joined the project towards the end and have been fast at work trying to understand Gaelic orthography, how it has developed over the centuries, and what is possible in regards to automated normalisation. I have been working alongside Michael ‘Akerbeltz’ Bauer, a Gaelic linguist with extensive credentials. He has literally written the dictionary on Gaelic as well as a book on Gaelic phonology: it is safe to say I am in good hands. We have been working together to find a way of teaching a program exactly how to normalise Gaelic text. Whereas a human can explain why a word should be spelt a specific way, programming this takes quite a bit of figuring out.
An early ancestor to Scottish Gaelic (Archaic Irish) was written in Ogham, and interestingly enough was carved vertically into stone.
Luckily historical text normalisation is a well-trodden path, and there are plenty of papers and theses online to help. In her thesis, Eva Pettersson describes four main methods for normalising text and, inspired by these, we got started. The first method relies on possessing an extensive lexicon of the target language, which we so happen to have, thanks to Michael.
Lexicon Based Normalisation
This method relies upon having a large lexicon stored that can cover the majority of words in the target language. Using this, you can check to see if a word is spelt correctly, whether it is in a traditional spelling, or if the writer has made a mistake.
The advantage of this method is that you do not have to be an expert in the language yourself (lucky for me!). Our first step was finding a way to integrate the world’s most comprehensive digital Scottish Gaelic dictionary, Am Faclair Beag. The dictionary contains traditional and misspelt words mapped to their correct spellings. This meant that we can have the program go through a text and swap words if it identifies one that needs correcting.
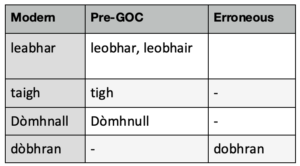
The table above shows some modern words with pre-GOC variants or misspellings. Michael has been collecting Gaelic words and their spelling variants for decades. If our program finds a word that is ‘out of dictionary’, we pass it on to the next stage of normalisation, which involves the hand crafting of linguistic rules.

‘An Gocair’
Rule-based Text Normalisation
Once we have filtered out all of the words that can be handled by our lexicon alone, we try to make use of linguistic rules. It’s not always easy to program a rule so that a computer can understand it. For example, we all know the English rule ‘i before e except after c’ (which of course is an inconsistent rule in English). We can program this by getting the computer to catch all the i’s before e’s and make sure they don’t come after a c.
With guidance from Michael, we went about identifying rules in Gaelic that can be intuitively programmed. One common feature of traditional Gaelic is the replacement of vowels with apostrophes at the end of words if the following word begins with a vowel. This is called ellipsis and is due to the fact that, if one were to speak the phrase, one wouldn’t pronounce both vowels: the writer is simply writing how they would speak. For example, native Gaelic speakers wouldn’t say is e an cù a tha ann ‘it is the dog’: they would say ’s e ’n cù a th’ ann, dropping three vowels. But in writing, we want these vowels to appear – at least for most machine learning situations.
It is not always straightforward working out which vowel an apostrophe replaces, but we can use a rule to help us. Gaelic vowels come in two categories, broad (a, o, u) and slender (e, i). In writing, vowels conform to the ‘broad to broad and slender to slender rule’, so when reinstating a vowel at the end of a word we need to check the form of the first vowel to the left of our apostrophe and ensure that, if it is a broad vowel, we add in a matching vowel.
Pattern Matching with Regular Expression
For this method of normalisation we make use of regular expressions for catching common examples that require normalisation, but are not covered by the lexicon or our previous rules. For example, consider the following example, which is a case of hyper-phonetic spelling, when a person writes like they speak:
Tha sgian ann a sheo tha mis’ a’ toir dhu’-sa.
Here, the word mis’ is given an apostrophe as a final character, because the following word begins with a vowel. GOC suggests that we restore the final vowel. To restore this vowel, we’re helped by the regularity of the Gaelic orthography, a form of vowel harmony, whereby each consonant has to be surrounded either by slender letters (e, i) or broad letters (a, o, u). So in the example above we need to make sure the final vowel of mis’ is a slender vowel (mise), because the first vowel to the left is also slender. We have managed to program this and, using a nifty algorithm, we can then decipher what the correct word should be. When the word is resolved we check to see if the resolved form is in the lexicon and if it is, we save it and move on to the next word.
Evaluation
Now you might be wondering how I managed to learn Scottish Gaelic so comprehensively in five months that I was able to write a program that corrects spelling and also confirm that it is working properly. Well, I didn’t. From the start of the task, I knew there was no way I would be able to gain enough knowledge about the language that I could confidently assess how well the tool was performing. Luckily I did have a large amount of text that was corrected by hand, thanks to Michael’s hard work.
To be able to verify that the tool is working, I had to write some code that automatically compares the output of the tool to the gold standard that Michael created, and then provide me with useful metrics. Eva Peterssonn describes in her thesis on Historical Text Normalisation two such metrics: error reduction and accuracy. Error reduction provides you with the percentage of errors in a text that are successfully corrected using the following formula:

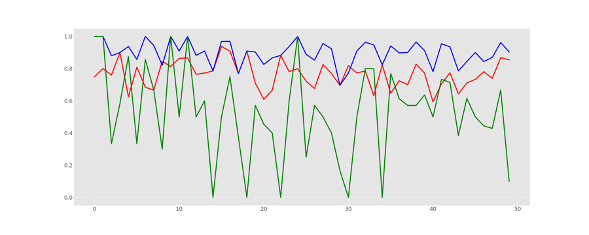
Accuracy simply evaluates the number of words in the gold standard text which has an identical spelling in the normalised version. Below you can see the results of normalisation on a test set of sentences. The green line shows the percentage or errors that are corrected whilst the red and blue line show the accuracy before and after normalisation, respectively. As you can see the normaliser manages to successfully improve the accuracy, sometimes even to 100%.
From GOC to ‘An Gocair’
With a play of words on GOC, we have named the program An Gocair ‘The Un-hooker’. We have tried to make it as easy as possible to update it with new rules. We hope to have the opportunity to create more rules in the future ourselves. The program will also improve with the next iteration of Michael’s fabulous dictionary. We hope to release the first version of An Gocair to the world by the end of October 2021. Keep posted!
Acknowledgement
This program was funded by the Data-Driven Innovation initiative (DDI), delivered by the University of Edinburgh and Heriot-Watt University for the Edinburgh and South East Scotland City Region Deal. DDI is an innovation network helping organisations tackle challenges for industry and society by doing data right to support Edinburgh in its ambition to become the data capital of Europe. The project was delivered by the Edinburgh Futures Institute (EFI), one of five DDI innovation hubs which collaborates with industry, government and communities to build a challenge-led and data-rich portfolio of activity that has an enduring impact.
References
Pettersson, E. (2016). Spelling Normalisation and Linguistic Analysis of Historical Text for Information Extraction, University of Uppsala.


Leave a Reply