Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
In working on the project for the University of Edinburgh, our team from Code Your Future is thrilled to present our project, ‘Crowdsourcing User Judgements for Gaelic Normalisation’. Aimed at Gaelic speakers, this project will collect user inputs on passages of historical Gaelic writing that have been updated to modern orthography by an AI model developed by the University of Edinburgh. Through hard work, collaboration, innovation and problem-solving, we have hugely enhanced a previous research project, ‘An Gocairː An Automatic Gaelic Standardiser’ and not only met but exceeded our goals.
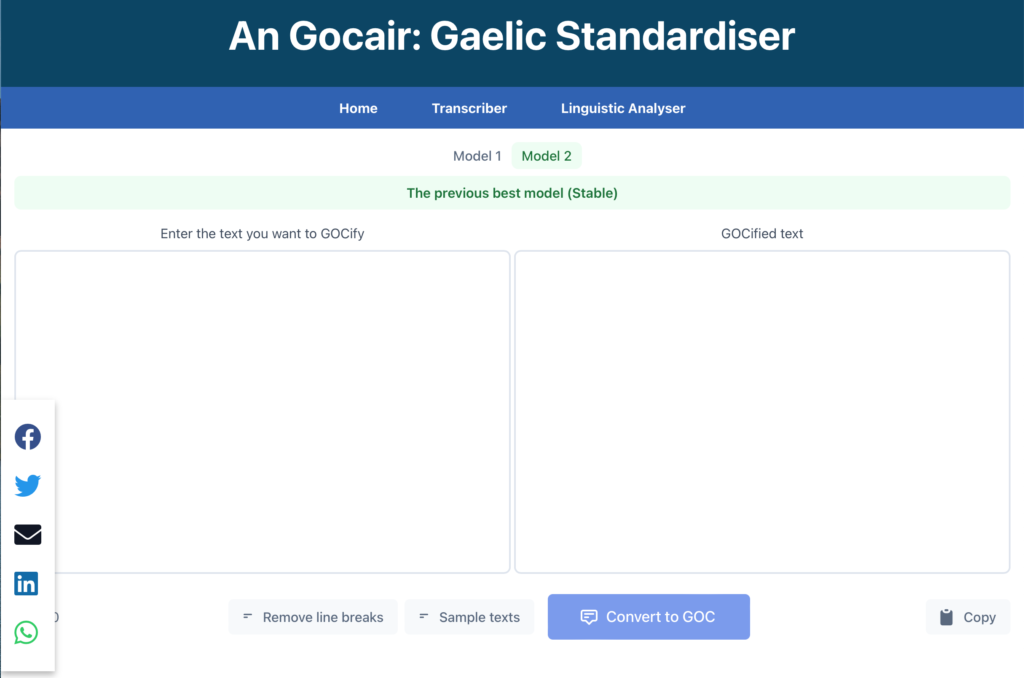
The ‘An Gocair’ Web App
Our team used the PERN stack as it uses a common framework and program language so it can be easily modified to enhance user experience and interactions in the future. In today’s globalised world, it is useful to be able to launch this application from any device and location. We have admin features in our application to give researchers more control over the data, and user sign-in features that allow users to sign in from social media accounts. Throughout the project, there were challenges in terms of adhering to project requirements. Those challenges were an opportunity for us to learn. So we valued our team members’ creativity, experimentation and unique skills to find solutions to the problems that aligned with our project objective.
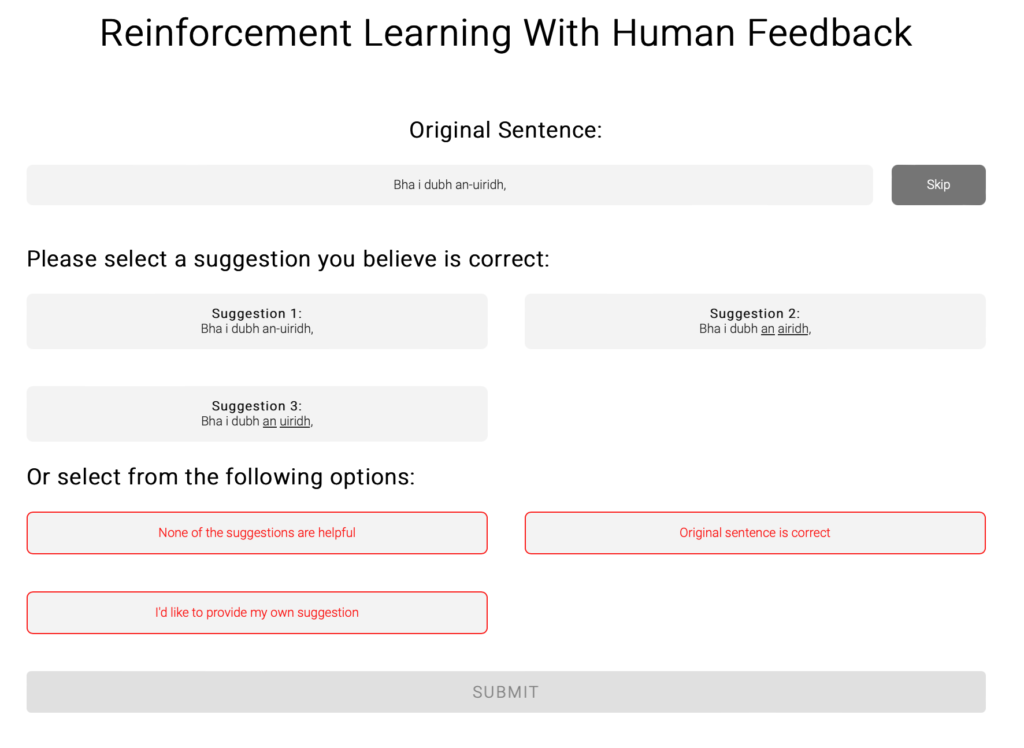
The Reinforcement Learning with Human Feedback App – for crowdsourcing Gaelic speaker judgements on AI-corrected texts
Our project followed an agile mindset that prioritises interactions, customer collaborations and responsiveness to change. As a result, we adapted agile values and principles focusing on short development cycles like creating simpler tasks, allocating them to the team members and receiving constant feedback from the team lead. Also, the agile approach helped us to manage time efficiently through sprint planning, daily standup meetings and optimising our time allocation and productivity.
By using React we have made every feature into a component so it can be easily modified in the future. By using the Passport module we have made the application more secure. Implementing it into the application was a challenge, however, and took a lot of the time. Before coming up with the passport, we tried a few different authentication tools but they did not give us the ability to be used as login with other social media accounts.
Our project relies on data and the Postgres database management system is useful for storing and managing our data efficiently. Our database Schema design considers scalability in mind to handle a growing dataset and increased user load. We also implemented proper encryption and access control, to protect users’ data and maintain user privacy through admin features.
While some of our research group has been busy creating the world’s first Scottish Gaelic Speech Recognition system, others been creating the world’s first Scottish Gaelic Text Normaliser. Although it might not turn the heads of AI enthusiasts and smart device lovers in the same way, the normaliser is an invaluable tool for unlocking historical Gaelic, enhancing its use for machine learning and giving people a way to correct Gaelic spelling with no hassle.
Rob Thomas
Why do we need a Gaelic text normaliser? Well, this program takes pre-standardised texts, which can vary in their orthography, and rewrites them in the modern Gaelic Orthographic Conventions (GOC). GOC is a document published by the SQA which details the modern standards for writing in Gaelic. Text normalisation is an important step in text pre-processing for machine learning applications. It’s also useful when reprinting older texts for modern readers, or if you just want to quickly spellcheck something in Gaelic.
I joined the project towards the end and have been fast at work trying to understand Gaelic orthography, how it has developed over the centuries, and what is possible in regards to automated normalisation. I have been working alongside Michael ‘Akerbeltz’ Bauer, a Gaelic linguist with extensive credentials. He has literally written the dictionary on Gaelic as well as a book on Gaelic phonology: it is safe to say I am in good hands. We have been working together to find a way of teaching a program exactly how to normalise Gaelic text. Whereas a human can explain why a word should be spelt a specific way, programming this takes quite a bit of figuring out.
An early ancestor to Scottish Gaelic (Archaic Irish) was written in Ogham, and interestingly enough was carved vertically into stone.
Luckily historical text normalisation is a well-trodden path, and there are plenty of papers and theses online to help. In her thesis, Eva Pettersson describes four main methods for normalising text and, inspired by these, we got started. The first method relies on possessing an extensive lexicon of the target language, which we so happen to have, thanks to Michael.
Lexicon Based Normalisation
This method relies upon having a large lexicon stored that can cover the majority of words in the target language. Using this, you can check to see if a word is spelt correctly, whether it is in a traditional spelling, or if the writer has made a mistake.
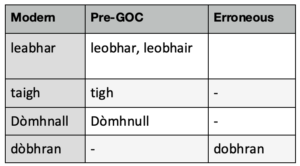
The advantage of this method is that you do not have to be an expert in the language yourself (lucky for me!). Our first step was finding a way to integrate the world’s most comprehensive digital Scottish Gaelic dictionary, Am Faclair Beag. The dictionary contains traditional and misspelt words mapped to their correct spellings. This meant that we can have the program go through a text and swap words if it identifies one that needs correcting.
The table above shows some modern words with pre-GOC variants or misspellings. Michael has been collecting Gaelic words and their spelling variants for decades. If our program finds a word that is ‘out of dictionary’, we pass it on to the next stage of normalisation, which involves the hand crafting of linguistic rules.
‘An Gocair’
Rule-based Text Normalisation
Once we have filtered out all of the words that can be handled by our lexicon alone, we try to make use of linguistic rules. It’s not always easy to program a rule so that a computer can understand it. For example, we all know the English rule ‘i before e except after c’ (which of course is an inconsistent rule in English). We can program this by getting the computer to catch all the i’s before e’s and make sure they don’t come after a c.
With guidance from Michael, we went about identifying rules in Gaelic that can be intuitively programmed. One common feature of traditional Gaelic is the replacement of vowels with apostrophes at the end of words if the following word begins with a vowel. This is called ellipsis and is due to the fact that, if one were to speak the phrase, one wouldn’t pronounce both vowels: the writer is simply writing how they would speak. For example, native Gaelic speakers wouldn’t say is e an cù a tha ann ‘it is the dog’: they would say ’s e ’n cù a th’ ann, dropping three vowels. But in writing, we want these vowels to appear – at least for most machine learning situations.
It is not always straightforward working out which vowel an apostrophe replaces, but we can use a rule to help us. Gaelic vowels come in two categories, broad (a, o, u) and slender (e, i). In writing, vowels conform to the ‘broad to broad and slender to slender rule’, so when reinstating a vowel at the end of a word we need to check the form of the first vowel to the left of our apostrophe and ensure that, if it is a broad vowel, we add in a matching vowel.
Pattern Matching with Regular Expression
For this method of normalisation we make use of regular expressions for catching common examples that require normalisation, but are not covered by the lexicon or our previous rules. For example, consider the following example, which is a case of hyper-phonetic spelling, when a person writes like they speak:
Tha sgian ann a sheo tha mis’ a’ toir dhu’-sa.
Here, the word mis’ is given an apostrophe as a final character, because the following word begins with a vowel. GOC suggests that we restore the final vowel. To restore this vowel, we’re helped by the regularity of the Gaelic orthography, a form of vowel harmony, whereby each consonant has to be surrounded either by slender letters (e, i) or broad letters (a, o, u). So in the example above we need to make sure the final vowel of mis’ is a slender vowel (mise), because the first vowel to the left is also slender. We have managed to program this and, using a nifty algorithm, we can then decipher what the correct word should be. When the word is resolved we check to see if the resolved form is in the lexicon and if it is, we save it and move on to the next word.
Evaluation
Now you might be wondering how I managed to learn Scottish Gaelic so comprehensively in five months that I was able to write a program that corrects spelling and also confirm that it is working properly. Well, I didn’t. From the start of the task, I knew there was no way I would be able to gain enough knowledge about the language that I could confidently assess how well the tool was performing. Luckily I did have a large amount of text that was corrected by hand, thanks to Michael’s hard work.
To be able to verify that the tool is working, I had to write some code that automatically compares the output of the tool to the gold standard that Michael created, and then provide me with useful metrics. Eva Peterssonn describes in her thesis on Historical Text Normalisation two such metrics: error reduction and accuracy. Error reduction provides you with the percentage of errors in a text that are successfully corrected using the following formula:
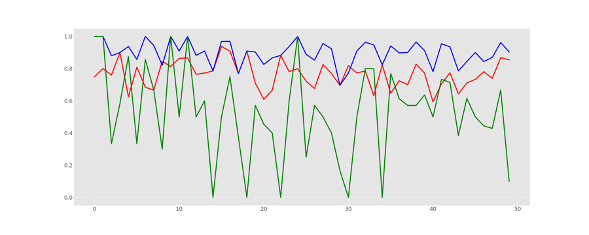
Accuracy simply evaluates the number of words in the gold standard text which has an identical spelling in the normalised version. Below you can see the results of normalisation on a test set of sentences. The green line shows the percentage or errors that are corrected whilst the red and blue line show the accuracy before and after normalisation, respectively. As you can see the normaliser manages to successfully improve the accuracy, sometimes even to 100%.
From GOC to ‘An Gocair’
With a play of words on GOC, we have named the program An Gocair ‘The Un-hooker’. We have tried to make it as easy as possible to update it with new rules. We hope to have the opportunity to create more rules in the future ourselves. The program will also improve with the next iteration of Michael’s fabulous dictionary. We hope to release the first version of An Gocair to the world by the end of October 2021. Keep posted!
Acknowledgement
This program was funded by the Data-Driven Innovation initiative (DDI), delivered by the University of Edinburgh and Heriot-Watt University for the Edinburgh and South East Scotland City Region Deal. DDI is an innovation network helping organisations tackle challenges for industry and society by doing data right to support Edinburgh in its ambition to become the data capital of Europe. The project was delivered by the Edinburgh Futures Institute (EFI), one of five DDI innovation hubs which collaborates with industry, government and communities to build a challenge-led and data-rich portfolio of activity that has an enduring impact.
Since September 2020, a collaborative team from the University of Edinburgh (UoE), the University of the Highlands and Islands (UHI), and Quorate Technology, has been working towards building an Automatic Speech Recognition (ASR) system for Scottish Gaelic. This is a system that is able to automatically transcribe Gaelic speech into writing.
The applications for a Gaelic ASR system are vast, as demonstrated by those already in use for other languages, such as English. Examples of applications include voice assistants (Alexa, Siri), video subtitling, automatic transcription, and so on. Our goal for this project is to build a full working system for Gaelic in order to facilitate these types of use-cases. In the long term, for example, we hope to enable the automatic generation of transcripts and/or subtitles for pre-existing Gaelic recordings and videos. This would add value to these resources by rendering them searchable by word or topic. In this blog post, we describe our progress so far.
Data and Resources
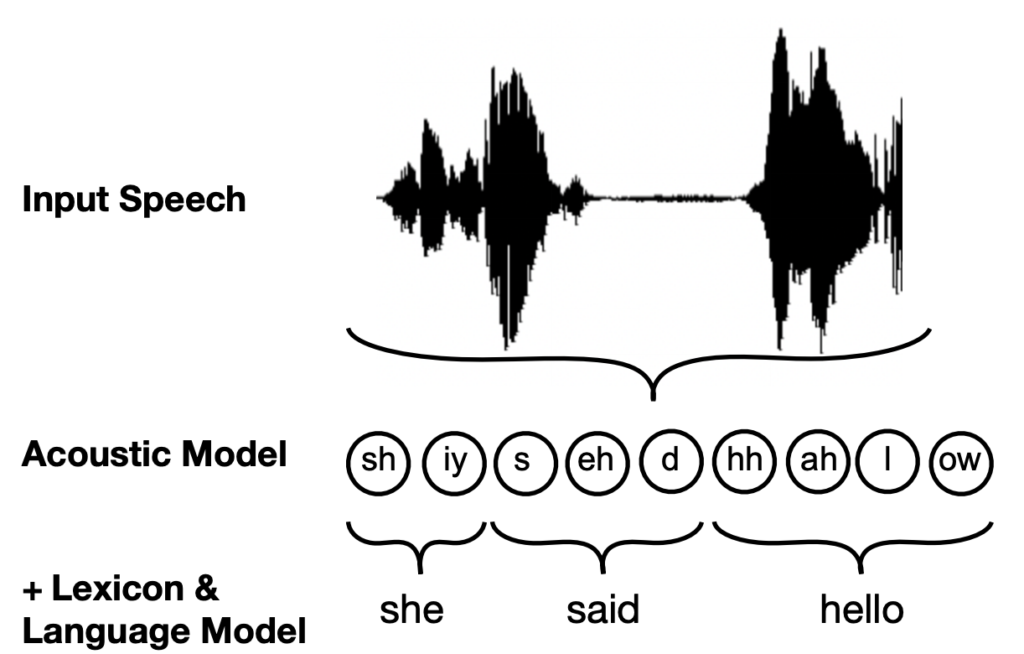
There are 3 main components needed to construct a full ASR system. These comprise the lexicon, which maps words to their component phonemes (e.g. hello = hh ah l ow), the language model, which identifies likely sequences of words in the target language, and the acoustic model, which learns to recognise the component phonemes making up a segment of speech. The combination of these three components enables the ASR system to pick up on a sequence of phonemes in the input speech, map these phonemes to written words, and output a full predicted transcription of the recording.
Input
Output Prediction
Language Model
The United States of <?>
America
Acoustic Model
Audio (Speaker says “Good Morning”)
g uh d m ao r n ih ng
Of course, building these components requires resources. In terms of the lexicon, we are fortunate enough to have this resource already available to us. Am Faclair Beag is a digital Gaelic dictionary, developed by Michael Bauer, which includes phonetic transcriptions for over 30,000 Gaelic words. We simply pulled each word and pronunciation from this dictionary and combined them into a list to serve as our initial lexicon.
For training our language model (LM), we required a large corpus of Gaelic text. A LM counts occurrences of every 4-word sequence present in this text corpus, so as to learn which phrases are common in Gaelic. The following resources were drawn upon to build this:
The gd Corpus, which is a web-scraped text corpus assembled as part of the An Crúbadán project. This project aims to build corpora and other language technology resources for minority languages
Tobar an Dualchais/Kist o Riches, a collaborative project which aims to “preserve, digitise, catalogue and make available online several thousand hours of Gaelic and Scots recordings”. They supplied several hundred transcriptions of archive material from the School of Scottish Studies Archives
Finally, for training the acoustic model, we required a large number of speech recordings along with their corresponding transcriptions. This is so that the model can learn (with help from the lexicon) how the different speech sounds map to written words. We used recordings and transcriptions from the following sources to construct this dataset:
The School of Scottish Studies Archives (UoE) – see above
Clilstore, an educational website that provides Gaelic language videos at various different CEFR levels
A note on alignment
In order to train our ASR system to map speech sounds to written words, we must time-align each transcription to its corresponding recording. In other words, the transcriptions must be given time-stamps, specifying when each transcribed word occurs in the recording.
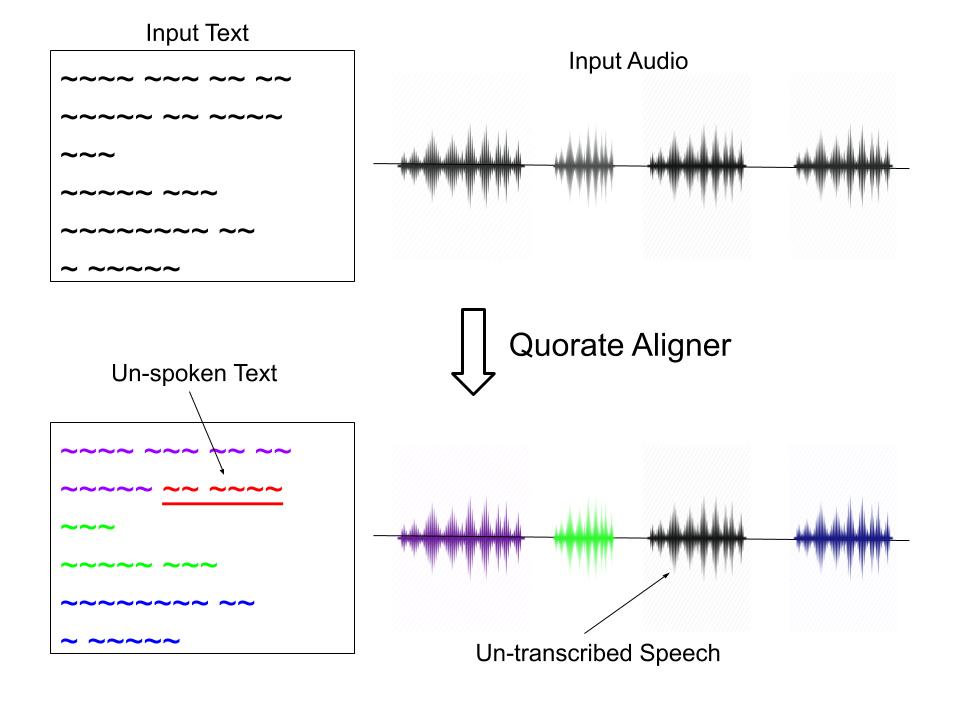
Time-aligning the transcriptions manually is lengthy and expensive, so we generally rely on automatic methods. In fact, we use a method very similar to speech recognition to generate these alignments. The issue here is that the automatic aligner also requires time-aligned speech data for training, which we don’t have for Gaelic.
We are fortunate in that we have been able to use a pre-built English speech aligner from Quorate Technology to carry out our Gaelic alignment task. As this was trained on English speech, it may be surprising that it is still effective for aligning our Gaelic data. However, despite noticeable high-level differences between the two languages (words, grammar etc.), the aligner is able to pick up on the lower-level features of speech (pitch, tone etc.), which are global across different languages. This means it can make a good guess at when specific words occur in each recording.
The alignment process – mapping text to audio.
Adapting the Lexicon
1. Mapping from IPA to the Aligner Phoneset
Because we are using a pre-built aligner on our speech data, we must ensure that the set of phones used to phonetically transcribe the words in our lexicon is the same as the set of phones recognised by the aligner’s acoustic model. Our lexicon, from Am Faclair Beag, uses a form of Gaelic-adapted IPA, whereas the Quorate aligner recognises a special, computer-readable set of English phones. For this reason, our first task was to map each phone in the lexicon’s phoneset to its equivalent (or closest) phone used in the aligner’s phoneset.
We first standardised the lexicon phoneset, mapping each specialised Gaelic IPA phone back to its standard IPA equivalent. We next mapped this standard IPA phoneset to ARPABET, an American-English phoneset that is widely used in language technology. This is the foundation of the aligner’s phoneset. We had to draw on our phonetic knowledge of Gaelic to create the mapping from IPA to ARPABET, because the set of phones used in English speech differs to that used in Gaelic: some Gaelic phones do not exist in English. For each additional Gaelic phone, we therefore selected the ARPABET phone that was deemed its ‘closest match’. Take the following Gaelic distinction between a non-aspirated, palatalised ( kʲ ) and non-aspirated non-palatalised ( k ) stop consonant, for example:
Gaelic IPA
(Gaelic phoneset)
Standard IPA
(global phoneset)
ARPABET
(English phoneset)
g
k
K
gʲ
kʲ
K
Our final mapping was from ARPABET to the aligner’s phoneset. Considering both of these phonesets are based on English, this was a fairly easy process; each ARPABET phone had an exact equivalent in the aligner phoneset. Once we had our final phoneset mapping, we converted all the phonetic transcriptions in the lexicon to their equivalent in the aligner’s phoneset, for example:
Word
Original
(Gaelic IPA)
Standard IPA
ARPABET
Aligner
uisge
ɯ ʃ gʲ ə
ɯ ʃ kʲ ə
UX SH K AX
uh sh k ax
gorm
g ɔ r ɔ m
k ɔ ɾ ɔ m
K AO DX AO M
k ao r ao m
2. Adding new pronunciations
For our ASR system to learn to recognise the component phones of spoken words, we need to ensure that every word that appears in our training corpus is included in the lexicon.
Our initial phoneticised lexicon stood at an impressive 30,000 Gaelic words, however, the number of words in our training corpus exceeds 150,000. This leaves 120,000 missing pronunciations, many of which will simply be morphological variations on the dictionary entries. If our model were to come across any of these words in training, it would be unable to map the acoustics of that word to its component phoneme labels.
The ASR system maps the phones recognised by the acoustic model to words, using the pronunciations in the lexicon.
A solution to this is to train a Grapheme-to-Phoneme (G2P) model, which, given a written word as input, can predict a phonetic transcription for that word, based solely on the letters (graphemes) it contains. For example:
Input
Output Prediction
h-uisgeanan
hh uh sh k ih n aa n
galachan
k aa el ax k aa n
fuaimeannan
f uw ax iy m aa en aa n
We trained a G2P model using all the words and pronunciations already in our lexicon. The model learns typical patterns of Gaelic grapheme to phoneme mappings using these as examples. Our model achieved a symbol error rate of 3.82%, which equates to an impressive 96.18% accuracy. We subsequently used this model to predict the pronunciation for the 120,000 missing words, and added them to our lexicon.
Text Normalisation
1. Punctuation, Capitalisation, and other Junk
Our next tasks focused on normalising our text corpus. We want to ensure that any text we input to our language model is free from punctuation and capitalisation, so that the model does not distinguish between, for example, a capitalised and lowercase word (e.g. ‘Hello’ vs. ‘hello’), where the meaning of these tokens is actually the same. A simple Python programme was written for this purpose which, along with punctuation and capitalisation, also stripped out any junk, such as turn-taking indicators. Here is an example of the programme at work:
Input
Output
A’ cur uèirichean ri pluga.
a cur uèirichean ri pluga
An ann ro theth a bha e?
an ann ro theth a bha e
EC―00:05: Dè bha ceàrr air, air obair a’ bhanca?
dè bha ceàrr air air obair a bhanca
2. Digit Verbalisation
Another useful type of text normalisation is the verbalisation of digits. Put simply, this involves converting any digits in our corpus into words, for example, ‘42’ -> ‘forty-two’. An easy way of doing this is by using a Python tool called num2words. The tool is functional for verbalising digits into numerous languages, but unfortunately did not support Gaelic. For this reason, we coded our own Gaelic digit verbaliser, in order to verbalise the digits present in our text corpus. As the num2words projects welcomes contributions, we also hope to be able to contribute our code, so as to make the tool accessible to others.
Our digit verbaliser is currently functional for the numbers 0-100, and for the years 1100-2099. Also, as Gaelic uses both the decimal (10s) and vigesimal (20s) numbering systems, we ensured that our tool is able to verbalise each digit using either system, as specified by the user. We hope to eventually extend this to a wider range of numbers. The following examples show our digit verbaliser at work:
a) Numbers
Original
Uill, tha, tha messages na seachdaine a chaidh agam ri phàigheadh agus bidh e timcheall air mu 80 pounds.
Vigesimal
Uill, tha, tha messages na seachdaine a chaidh agam ri phàigheadh agus bidh e timcheall air mu ceithir fichead pounds.
Decimal
Uill, tha, tha messages na seachdaine a chaidh agam ri phàigheadh agus bidh e timcheall air mu ochdad pounds.
b) Years
Original
Bha, bha e ann am Poll a’ Charra ann an 1860.
Vigesimal
Bha, bha e ann am Poll a’ Charra ann an ochd ceud deug, trì fichead.
Decimal
Bha, bha e ann am Poll a’ Charra ann an ochd ceud deug ‘s a seasgad.
Current Work and Next Steps
After carrying out all the data and lexicon preparation, we were able to align our Gaelic speech data using Quorate’s English aligner. We have started using this to train our first acoustic models, and will soon be able to build our first full speech recognition system – keep an eye out for our next update!
Automatically subtitled video (using provided script)
However, aside from creating acoustic model training data, alignment can actually be useful for other purposes: it enables us to create video subtitles, for example. This kind of use case actually enables us to present our first observable results, which have been extremely encouraging. The videos in the link below exhibit our time-aligned subtitles, originally a simple transcription, separated from the video: click here to see examples of our work so far!