Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
We’re thrilled to announce the launch ofHidden Heritages, a brand-new website for accessing Scottish and Irish traditional tales. This resource is the outcome of an international, multi-year collaboration between universities in the UK, Ireland and USA, generously supported by the Arts and Humanities Research Council (AHRC) and the Irish Research Council (IRC).
Between 2021 and 2024, our team digitised and recognised thousands of tales from the School of Scottish Studies Archives (SSSA) and the Irish National Folklore Collection (NFC). The result? An online repository featuring 5,515 folktales, with more than 3,400 tales from Scotland and over 2,000 from Ireland.
Search page for the Hidden Heritages website.
Behind the Scenes
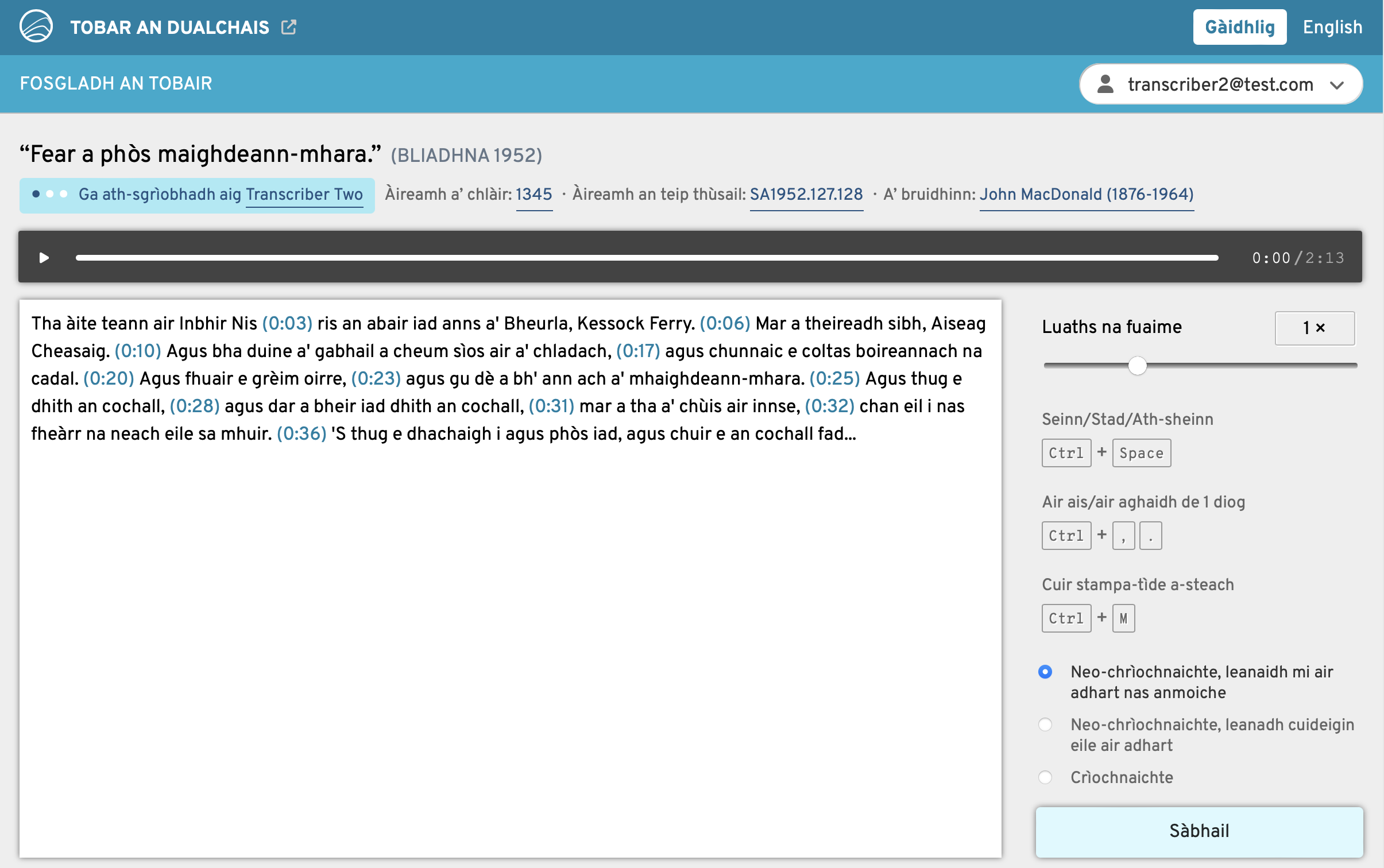
Many of these tales date back centuries and were collected orally from tradition bearers up to the end of the 20th century. Ethnologists at the SSSA and NFC transcribed thousands of them from fieldwork recordings as handwritten manuscripts. In other cases, the tales came from printed books and articles. Using AI-powered text recognition (OCR for printed material and HTR for handwriting), the research team converted these documents to digital text and have now made them publicly accessible online, often for the very first time. Transkribus, the handwriting recognition tool, was instrumental for this work.
While the automatic transcriptions aren’t flawless, the accuracy is impressive, with less than 5% error rates. And because the original transcriptions often captured rich dialectal forms of Irish and Scottish Gaelic, these texts are a goldmine for linguistic and cultural analysis.
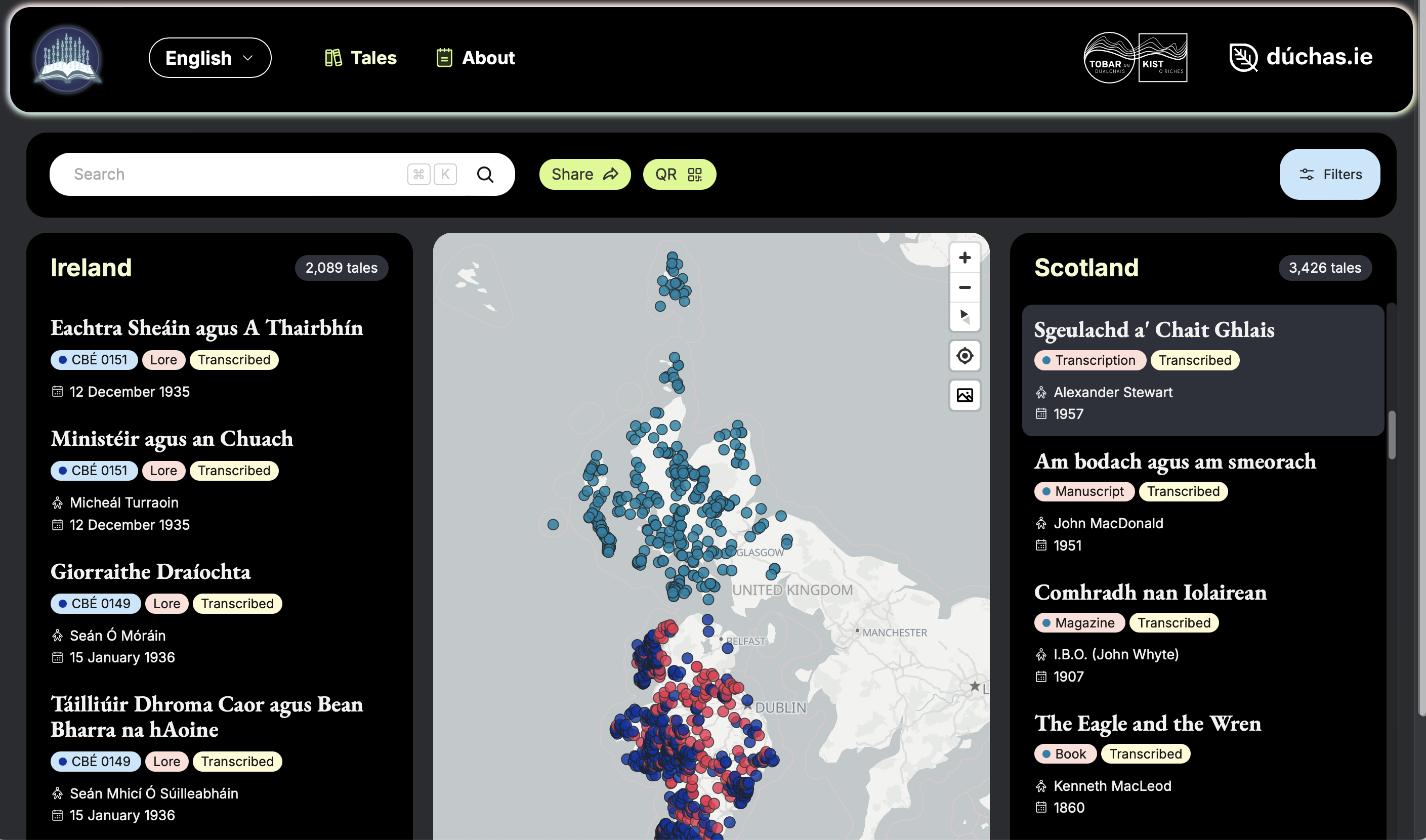
Viewing the texts and metadata for the Gaelic tale ‘Biast na[n] Naoi Ceann’ (‘Beast of the Nine Heads’)
Dall ort! Jump Right In!
Using the website couldn’t be simpler. Explore by searching for your favourite folktale themes. Perhaps you’re interested in tales of witches (buidsichean), giants (fuamhairean) or fairies (Na Daoine Beaga‘The Wee Folk’). You can filter stories by date, tale-type, language, gender of collectors and narrators, and much more. Interactive visual maps will guide you straight to tales from particular places, letting you discover how stories travelled and evolved.
Users who don’t have Gaelic or Irish can copy and paste texts into Google Translate to get a rough English translation. For many of Scottish tales, we also include direct links to Tobar an Dualchais / Kist o Riches, where users can access the original fieldwork recordings from the School of Scottish Studies Archives. Irish readers can even help to improve some of the transcriptions, but following links to Meitheal Dúchas.
Whether you’re a researcher, folklore enthusiast or just curious about traditional tales, we invite you to explore, share and participate in this rich cultural legacy. Scottish material is provided for research purposes, and Irish stories are available under a Creative Commons licence, allowing non-commercial reuse — remember to attribute your sources carefully.
Visit www.hiddenheritages.ai and explore Gaelic storytelling now! And keep an eye out for our upcoming book, Decoding the Oral Traditions of Scotland and Ireland: From Manuscripts to Models, to be published by Edinburgh University Press in 2026.
Scottish Gaelic, spoken by roughly 60,000 people today, is poised for a technological transformation thanks to the ÈIST project, led by the University of Edinburgh. ÈIST [eːʃtʲ] (‘ayshch’) is short for Ecosystem for Interactive Speech Technologies, and means ‘listen’ in Gaelic. The project is funded by the Scottish Government and Bòrd na Gàidhlig, with key partners including the BBC ALBA, NVIDIA, the University of Glasgow and Tobar an Dualchais / Kist o Riches. It aims to support the revitalisation of the language through cutting-edge interactive technologies, including speech recognition.
Since launching in 2023, ÈIST has focussed on developing accurate speech-to-text for Gaelic, but also for English — to cope with code-switching. The initial aim was to produce a system that could generate Gaelic-medium subtitles for BBC ALBA and Radio nan Gàidheal. In a forthcoming paper, the team reports achieving nearly 90% accuracy for chat shows, news and current affairs programmes. Now the team is expanding the technology, making it suitable for more diverse contexts, ranging from Gaelic-speaking classrooms to old fieldwork recordings.
In the autumn of 2025, the creation of an accessible, robust API (Application Programming Interface) will democratise these tools further. Developers and researchers worldwide will gain access to Gaelic speech recognition, embedding the technology into applications ranging from educational software to digital assistants.
Bridging Linguistic Gaps
Currently, Gaelic speech recognition systems struggle to transcribe younger speakers, whose speech patterns often differ from those of heritage speakers. ÈIST addresses this with its dedicated subproject, Recognising Children’s Speech, which will soon gather data from Gaelic Medium Education schools and units across Scotland. This new data will ensure that the speech of young learners is represented accurately.
The implications of this work are profound. Enhanced speech recognition can transform educational tools, such as TextHelp’s Read&Write, providing more effective support for literacy and learning among children. It can also improve accessibility for Gaelic speakers of all ages, especially those with literacy challenges or hearing impairment, providing critical tools for communication and inclusion.
A Community-Powered Initiative
Central to ÈIST’s mission is Opening the Well, a pioneering crowdsourcing platform currently in development and due to launch in the last quarter of 2025. This initiative will mobilise the Gaelic-speaking community worldwide to transcribe audio recordings of traditional narratives and oral history held on the Tobar an Dualchais portal, such as those originally from the School of Scottish Studies Archives (University of Edinburgh). It takes its cue from Ireland’s successful Meitheal Dúchas crowdsourcing project. These transcriptions won’t just make Scottish heritage more accessible — they will also provide vital training data to enhance the accuracy and versatility of future speech recognition models.
The editing screen in Opening the Well
Risks, Rewards and Responsibility
The team behind ÈIST is keenly aware that speech and language technologies are not neutral tools. Poorly trained models can misrepresent language, distort culture or reinforce social bias. That is why ÈIST places community involvement at the heart of its design process.
The researchers also promote best practices for ethical AI use in revitalisation: curate transparent training data, return outputs to the community (e.g., through DASG, the Digital Archive of Scottish Gaelic), and avoid relying on ‘big tech’ to solve our problems, albeit poorly. It is a values-led approach as much as a technical one.
The Future of Gaelic in the Digital Age
Finally, ÈIST is developing an interactive, text-based interviewer chatbot. This promises not only to engage speakers in naturalistic conversation but also to generate essential data for future applications. When combined with speech technology, such a chatbot could assist with language learning, offering conversational practice previously difficult to achieve outside of a native-speaking community. While this will never replace human teachers, it could be a very useful adjunct to teaching and learning.
In a broader sense, ÈIST represents a powerful case study in how language technology can empower minority languages. The project’s blend of machine learning and cultural preservation illustrates how digital innovation can help to sustain diversity, rather than eroding it. For more information about ÈIST, contact w.lamb@ed.ac.uk
ÈIST Research Team
Prof William Lamb (PI, University of Edinburgh)
Dr Bea Alex (Co-I, University of Edinburgh)
Prof Peter Bell (Co-I, University of Edinburgh)
Ms Rachel Hosker (Co-I, University of Edinburgh)
Prof Roibeard Ó Maolalaigh (Co-I, University of Glasgow)
Dr Alison Diack (Transcriber, DASG, University of Glasgow):
Mr Cailean Gordon (Lead transcriber, Tobar an Dualchais / Kist o Riches):
Dr Ondřej Klejch (Speech processing specialist, Informatics, University of Edinburgh)
Dr Michal Měchura (Web designer and computational linguist)
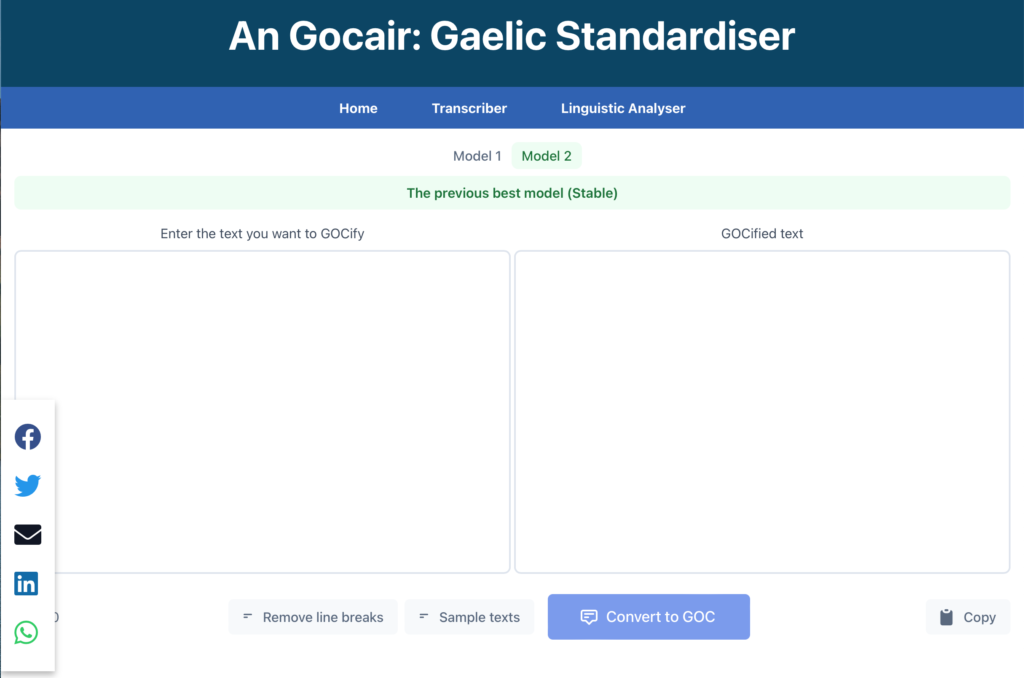
In working on the project for the University of Edinburgh, our team from Code Your Future is thrilled to present our project, ‘Crowdsourcing User Judgements for Gaelic Normalisation’. Aimed at Gaelic speakers, this project will collect user inputs on passages of historical Gaelic writing that have been updated to modern orthography by an AI model developed by the University of Edinburgh. Through hard work, collaboration, innovation and problem-solving, we have hugely enhanced a previous research project, ‘An Gocairː An Automatic Gaelic Standardiser’ and not only met but exceeded our goals.
The ‘An Gocair’ Web App
Our team used the PERN stack as it uses a common framework and program language so it can be easily modified to enhance user experience and interactions in the future. In today’s globalised world, it is useful to be able to launch this application from any device and location. We have admin features in our application to give researchers more control over the data, and user sign-in features that allow users to sign in from social media accounts. Throughout the project, there were challenges in terms of adhering to project requirements. Those challenges were an opportunity for us to learn. So we valued our team members’ creativity, experimentation and unique skills to find solutions to the problems that aligned with our project objective.
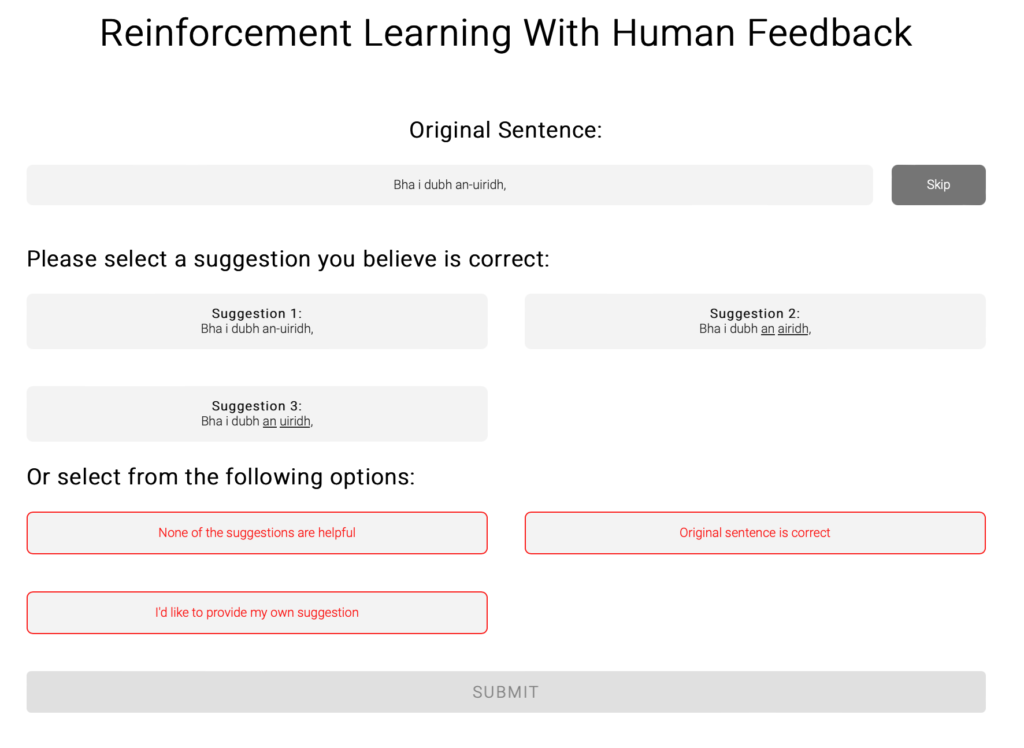
The Reinforcement Learning with Human Feedback App – for crowdsourcing Gaelic speaker judgements on AI-corrected texts
Our project followed an agile mindset that prioritises interactions, customer collaborations and responsiveness to change. As a result, we adapted agile values and principles focusing on short development cycles like creating simpler tasks, allocating them to the team members and receiving constant feedback from the team lead. Also, the agile approach helped us to manage time efficiently through sprint planning, daily standup meetings and optimising our time allocation and productivity.
By using React we have made every feature into a component so it can be easily modified in the future. By using the Passport module we have made the application more secure. Implementing it into the application was a challenge, however, and took a lot of the time. Before coming up with the passport, we tried a few different authentication tools but they did not give us the ability to be used as login with other social media accounts.
Our project relies on data and the Postgres database management system is useful for storing and managing our data efficiently. Our database Schema design considers scalability in mind to handle a growing dataset and increased user load. We also implemented proper encryption and access control, to protect users’ data and maintain user privacy through admin features.
As the Decoding Hidden Heritages project is nearing the end of its digitisation and metadata collection stage, this is a good opportunity to share some insights from the project on the importance of archival work for the representation of women’s heritage. While the project’s main focus is on the narrative traditions of Scotland and Ireland, valuable information has also been discovered that has wider cultural implications, such as the influence of gender on narrative traditions. These discoveries have been made possible by the digitisation process because it has allowed a re-examination and re-documentation of the archive’s collection. As part of this process at the School of Scottish Studies Archives, I have been able to employ what Prof Melissa Terras terms feminist digitisation practices, which ‘are both an attitude, and an application of technology in an efficient way’.[1] She described this practice as ‘an act of owning women’s history, using digital means, to collate information and histories that the mainstream – for whatever reason – has not tackled’.[2] For this project, that has involved ensuring that women’s material in the archive is accessible to and discoverable by the public through digitisation and accurate metadata collection.
While digitising the Tale Archive I discovered several unique factors that affected women’s presence, or rather their absence, in the archive. In particular, I noticed distinct documentation issues with the archive’s material relating to women. The most significant of these issues was the erasure of women’s names in archival documents and metadata.
There are four distinctive scenarios in which women’s names have been erased:
The documents lack women’s first names.
The most common erasure of women’s names in the archive is the use of only women’s surnames, particularly their married surnames, for example Mrs. Stewart. In SSSA_TA_WT042_001 the informant is only listed as Bean Sheumais (‘Wife of James’). This is most likely because that was how these women would have given their names to the collectors, as was the social practice at the time.
Their husband’s full name is used in lieu of women’s names.
The next most common form of women’s names is their husband’s full name used as their married name, for example Mrs. John MacDonald. In some cases, married women’s first names have been discovered and their full names are included in the metadata. For example, Mrs. Hugh Milne has been recorded as Bella Milne in the project database.
The influence of gender on the documentation of names in these records is made clear in SSSA_TA_GH013_001. The metadata for this transcription records the informant as ‘Andrew Stewart and family’ but the document itself listed it as Mrs. Andy Stewart. Despite the fact that this story is told by Mrs. Stewart about her own experience with a ghost, the metadata recorded her husband as the main informant, erasing Mrs. Stewarts’ ownership over her story. When her husband and son interject into her story, the transcript states ‘Carol Stewart, their son, takes over’ and ‘Andrew takes over’ but, rather than use her full name, it says that the ‘story returns home to Mrs. Stewart’. Each of the male members of the Stewart family have their full names recorded while Mrs. Stewart does not. As a result of re-examining this material, the metadata has been corrected and Mrs. Stewart’s story is now properly recognised in the archive.
The names are unrecorded.
In much of the material, women have shared their stories anonymously. This makes it impossible to document who they are. Women are often referred to as ‘girls’ such as ‘Barra Girl’ (SSSA_TA_GH002_002) or ‘a girl who was native of Glenurqhart’ (SSSA_TA_WT043_002) without their names recorded. Yet, even in these cases it is still important to document the informant’s gender in the metadata. For example, one informant was listed as a ‘Native of Lochcarron’ in SSSA_TA_WT037_015. However, by reading their story it can be ascertained this person was a woman, because she states, ‘when they sent me … I was a young girl at the time’. By documenting their gender in the metadata, at least we are able to accurately acknowledge these women’s presence in the archive.
They are not named in the archive’s metadata but are present in documents.
One of the most significant examples of a woman’s erasure from the archive is SSSA_TA_FL025. This document and its metadata records Walter Johnson as the informant of a transcription. However, the transcription is actually of Bella Higgins telling her personal experience of meeting a fairy [Ed. noted here using the dated and offensive term ‘golliwog’]. Even though it is only Bella speaking, her story had been attributed to Walter Johnson. As a consequence of this incorrect documentation, her voice had been hidden in the archive.
Similarly, in a series of transcriptions by John Stewart and his wife Maggie Stewart (SSSA_TA_GH001_022, 23, 25), John was recorded as the only informant. Even though Maggie was present in them as well, her contributions to their stories were unrecognised. As a result of the careful examination of these documents while they were digitised, these women’s contributions were uncovered and are now appropriately documented in the collection’s metadata.
While in some cases these documentation issues may seem small, they have significant consequences. Women’s names being unrecorded or partially recorded in the archives makes tracing women’s histories and family lineages extremely difficult and often impossible. For example, it is impossible to ascertain from the documentation whether a woman recorded as Mrs. MacDonald is the grandmother, mother, wife or sister-in-law to Mr. John Macdonald because all these women would have been referred to identically. Similarly, when women have no name recorded at all, their contributions to the archive are unidentifiable.
The exclusion of these women misrepresents the material within our archives, presenting the collection as more male dominated than it is. Not only is their re-inclusion into the archive’s metadata important as an act of justice for these women, but it also enriches and expands the historical research and data that can be produced from the archive. As historians Andrew Flinn, Mary Stevens, and Elizabeth Shepherd have argued, ‘the archives that are “chosen” for survival, the terms in which they are described, and the processes by which these decisions are made, do ultimately impact on the collective memory and public histories that are produced from them’.[3]
This is particularly important in the context of the increasing trend in historical research, where historians seek to write women who have been hidden in accounts back into history. A recent example of this is a biography of George Orwell’s wife, ‘Wifedom: Mrs. Orwell’s Invisible Life’ by Anna Funder. She points out that in Orwell’s novel Homage to Catalonia, written while Orwell and his wife were in Spain, he ‘mentions “my wife” 37 times but never once names her. No character can come to life without a name’.[4] However, Funder was able to reconstruct the life of Eileen when she went ‘back to the biographers’ footnotes and sources and into the archives and found details that had been left out. Eileen began to come to life’.[5] Thus, there is immense value in archival sources which is still being discovered today and archivists play a vital role in ensuring that women’s history in these archives does not remain hidden. It is therefore important to seize the opportunity that digitisation projects such as this present to employ feminist digitisation practices on archival collections to uncover women’s hidden histories and ensure their posterity for the future.
The DHH team would like to thank Catherine for her important and timely blog and her excellent contributions to the project.
Bibliography
Flinn, Andrew, Mary Stevens, and Elizabeth Shepherd. “Whose Memories, Whose Archives? Independent Community Archives, Autonomy and the Mainstream”. Archival Science 9, no. 1-2 (2009)
Funder, Anna. “Looking for Eileen: how George Orwell wrote his wife out of his story”. The Guardian, 30 July 2023. Accessed 4 October 2023. https://www.theguardian.com/books/2023/jul/30/my-hunt-for-eileen-george-orwell-erased-wife-anna-funder.
Melissa Terras. “Interview With Professor Melissa Terras On Feminist Digitisation Practices And The Future Of Our Digital Cultural Heritage”. The University Of Edinburgh Futures Institute, 6 January 2023. Accessed 4 October 2023. https://efi.ed.ac.uk/interview-with-professor-melissa-terras-on-feminist-digitisation-practices-and-the-future-of-our-digital-cultural-heritage/.
[1] Melissa Terras, “Interview With Professor Melissa Terras On Feminist Digitisation Practices And The Future Of Our Digital Cultural Heritage”, The University Of Edinburgh Futures Institute, 6 January 2023, accessed 4 October 2023. https://efi.ed.ac.uk/interview-with-professor-melissa-terras-on-feminist-digitisation-practices-and-the-future-of-our-digital-cultural-heritage/.
[3] Andrew Flinn, Mary Stevens, and Elizabeth Shepherd, “Whose Memories, Whose Archives? Independent Community Archives, Autonomy and the Mainstream”, Archival Science 9, no. 1-2 (2009): 76.
[4] Anna Funder, “Looking for Eileen: how George Orwell wrote his wife out of his story”, TheGuardian, 30 July 2023, accessed 4 October 2023. https://www.theguardian.com/books/2023/jul/30/my-hunt-for-eileen-george-orwell-erased-wife-anna-funder.
At our recent steering group meeting our Chair, Prof Melissa Terras, noted that the index cards I shared in the post on Alan Bruford’s Tale Types make great writing prompts. This immediately cast me back to my Am-Dram days, when our director would ask us to pick a number and assign us whichever ATU tale type that corresponded, to create a short play with. This is a really useful tool for creativity and I thought I would share some Tale types and a few examples from the card index, which you may wish to explore.
These index cards summaries one part of a recording, or a manuscript in the SSSA collections. Often they are just the most brief description of the tale and other cards go into more detail.
ATU 1696
“What Should I have Said…?”
You can read this above version of this tale type in our Maclagan collection, via the OpenBooks platform (page 11, MML2389).
Tom Robertson told Alan Bruford that this tale was his grandmother’s story.
ATU 510
Cinderella , Cap of Rushes
This is not from recording or a manuscript in SSSA, but I have to say that the way that the summary is written made it stand out to me. There are thousands of variants of Cinderella and many examples in the Tale Archive, including Essie Pattle, the Shetland variant. You can listen to T A Robertson read the story of Essie Pattle (SA1972.238.B1) in Shetland dialect here: https://www.tobarandualchais.co.uk/track/71783
Supernatural Witch Tales
Bewitched Dancing
This is one of the tale types devised by Alan Bruford for classifying Witch Tales. This tale appears in Calum MacLean’s notebooks, collected from Roy Bridge, and is a story of Alasdair nan Cleas – Alasdair of the Tricks – who was Keppoch Clan Chief and thought to be a sorcerer. There is a great blog about this tale over on the Calum MacLean Project blog: http://calumimaclean.blogspot.com/2015/05/dance-till-you-drop.html
ATU 1137
Tales of the Stupid Ogre / Self Did It
These types of tales have origins in the story of Odysseus and the Cyclops.
ATU 1452
Choosing a Wife
The above tale, told by Lucy Stewart (SA1960.167.A12). is a variant of a type of bride tests tale which includes stories which feature the selection of a wife on how she cuts cheese! You can listen to this recording via the SSSA material on Tobar an Dualchais: https://www.tobarandualchais.co.uk/track/22452
ATU 1408
The Foolish Husband & His Wife / The The man who does his wife’s work
Angus MacLellan told the story of a crofter who thought his wife was useless, until she asked him to swap places with him. The recording is on Tobar an Dualchais, with a summary in English. https://www.tobarandualchais.co.uk/track/34492
We also have a version of this in Maclagan, from Islay, MML 2386
Romantic Tales: The Lad and his Dream
Ending with a take from the Romantic Tales Index here at SSSA – two strangers dream of one another and set off to find the other!
If you feel inclined to use any of these prompts, we would love to see your work!
“Port Ness Beach, Isle of Lewis, Scotland” by Chris Golightly is licensed under CC BY-NC-SA 2.0.
Today (October 3rd) is Scottish Museums Day, a day to celebrate everything great and wonderful about Scottish Museums, galleries and archives! This year, the theme is: A Museum of Happiness, inspired by Stuart A. Paterson’s poem…
I’ve made my own Museum of
Happiness, which isn’t built of brick
or stone or wood, its walls the thickness
of the day, a flapping tongue of canvass
held in place by rope & peg to stop
it flying off & joyously away
up into everywhere in time & space
I’ll carry it around with me to pitch
beside the sea, in a field or by
that river, a billowing rickety marquee,
a travelling show of personal delights
performing one night only & forever…
A search for ‘happiness’ on Tobar an Dualchais produces some great results, and I thought I would share four School of Scottish Studies Archives stories/songs that demonstrate four different kinds of ‘happiness’.
Despite the title, the happiness spoken about in this song is not about a place, but about the memories and feelings of spending time with a loved one.
A story about finding happiness (and health, a princess and a kingdom) through embracing generosity and turning away greed – at least if you’re a character in a folktale!
This story can be interpreted in various ways, but I see it as a lesson to not rely on external factors to bring you happiness, or that you can search far and wide, but the key to happiness might have been in front of you all along.
What do you think of these stories? Is there a particular folktale or traditional song about happiness that makes you smile?
Here in the The School of Scottish Studies Archives we have tales classified under the ATU index, as well as tales grouped together under story types, such as Robber Tales, Historical Tradition; Romance Tales; Hero Tales and Legends.
There are also indexes of tales which are classified under “Supernatural Witch” and “Supernatural Fairies” which were part of the work of Alan Bruford (1937-1995) to survey the Central Index and pull together material of “recurrent plots and motifs from the tangled mass of Scottish, and especially Gaelic, local traditions of supernatural and historical events” [Bruford, 1967].
There isn’t a great deal written on the ongoing work of these type-lists, but it is clear that Bruford continued to work on this until his death. Donald Archie MacDonald (1929-1999) published a broader paper on the type-lists in 1995 and I link to that at the end.
Bruford, Alan 1967, ‘Scottish Gaelic Witch Stories: A Provisional Type-list’, Scottish Studies (volume 11), pp 12-47
MacDonald, Donald Archie 1994-1195. ‘ Migratory Legends of the Supernatural in Scotland: A General Survey’, Béaloideas (62/63), pp 29-78 https://www.jstor.org/stable/20522441
*The Maclagan Mss is in the process of being added to the University of Edinburgh’s OpenBooks platform as an open access resource. This is a work in progress but the pdf batches so far can be accessed here: https://edin.ac/3UdzSSz
The ‘secret’ of making heather ale has been a popular folktale in Scotland, with claims that the brewing of it dates back to ancient times.
I came across a few references to it while digitizing the ATU index cards in the SSSA’s Tale Archive.
Read the full Gaelic version from Calum Maclean’s collection of Fìion an Fhraoich (IFC MS 1028, pp. 103-105).
Accounts differ, as to whether it was the Vikings or ‘The Pechs’ that held the secret to making the ale, but the similar vein that runs through them is that eventually there were only two people in the world who held the secret: a father and his son. When they were forced to disclose their secret, the father claimed he would share the recipe, but only if his son was killed first. This request was followed through and the father then exclaimed that he had lied – he never intended to share the recipe, but believed that his son would have, being weaker than himself, and therefore had him killed to protect the secret forever!
“LONG ago there were people in this country called the Pechs; short wee men they were, wi’ red hair, and long arms, and feet sae braid, that when it rained they could turn them up owre their heads, and then they served for umbrellas.”
Another wonderful reference to this story is the 1890 poem “Heather Ale” by Robert Louis Stevenson.
From the bonny bells of heather
They brewed a drink long-syne,
Was sweeter far than honey,
Was stronger far than wine.
They brewed it and they drank it,
And lay in a blessed swound
For days and days together
In their dwellings underground.
There rose a king in Scotland,
A fell man to his foes,
He smote the Picts in battle,
He hunted them like roes.
Over miles of the red mountain
He hunted as they fled,
And strewed the dwarfish bodies
Of the dying and the dead.
Summer came in the country,
Red was the heather bell;
But the manner of the brewing
Was none alive to tell.
In graves that were like children’s
On many a mountain head,
The Brewsters of the Heather
Lay numbered with the dead.
The king in the red moorland
Rode on a summer’s day;
And the bees hummed, and the curlews
Cried beside the way.
The king rode, and was angry,
Black was his brow and pale,
To rule in a land of heather
And lack the Heather Ale.
It fortuned that his vassals,
Riding free on the heath,
Came on a stone that was fallen
And vermin hid beneath.
Rudely plucked from their hiding,
Never a word they spoke:
A son and his aged father—
Last of the dwarfish folk.
The king sat high on his charger,
He looked on the little men;
And the dwarfish and swarthy couple
Looked at the king again.
Down by the shore he had them;
And there on the giddy brink—
“I will give you life, ye vermin,
For the secret of the drink.”
There stood the son and father
And they looked high and low;
The heather was red around them,
The sea rumbled below.
And up and spoke the father,
Shrill was his voice to hear:
“I have a word in private,
A word for the royal ear.
“Life is dear to the aged,
And honour a little thing;
I would gladly sell the secret,”
Quoth the Pict to the King.
His voice was small as a sparrow’s,
And shrill and wonderful clear:
“I would gladly sell my secret,
Only my son I fear.
“For life is a little matter,
And death is nought to the young;
And I dare not sell my honour
Under the eye of my son.
Take him, O king, and bind him,
And cast him far in the deep;
And it’s I will tell the secret
That I have sworn to keep.”
They took the son and bound him,
Neck and heels in a thong,
And a lad took him and swung him,
And flung him far and strong,
And the sea swallowed his body,
Like that of a child of ten;—
And there on the cliff stood the father,
Last of the dwarfish men.
“True was the word I told you:
Only my son I feared;
For I doubt the sapling courage
That goes without the beard.
But now in vain is the torture,
Fire shall never avail:
Here dies in my bosom
The secret of Heather Ale.”
Nowadays, in the age of the internet and search engines, the guarding of a recipe to the death seems quite ridiculous! Also, to our modern sensibilities allowing a tradition to die out and not be preserved in some form or another would be almost unthinkable. The School of Scottish Studies Archives, and others like it around the world, exist to collect, preserve and share oral and written tradition. This work is very important, and crucial to our understanding of the past, present and future. The world is a much richer place for it!
If you’d like to try making your own heather ale, check out this recipe. Let us know how it turns out!
Our own Prof Will Lamb is working with Dr David Howcroft (lead investigator) and Dr Dimitra Gkatzia from Edinburgh Napier university to build the first tools for Gàidhlig chatbots. This is starting with the creation of a new dataset to train AI models.
Our current experiments (which you can participate in if you speak Gàidhlig!) are focused on building our dataset: we need examples of humans asking and answering questions about museum exhibits in a chat conversation. Participants are paired up and given a set of exhibits from the National Museum of Scotland to discuss, briefly summarising their discussions as well.
The next step? Well, after a bit of data cleanup and anonymisation, it’s time to see how well neural network models for natural language generation work for this amount of data. One of the interesting challenges for this project is trying to see how far you can get in building a chatbot with as little data as possible. The lessons we learn in this work will inform future work, not just in Scottish Gaelic, but in Natural Language Generation more generally!
Why build chatbots for Scottish Gaelic?
We believe the world is a better place when everyone can learn in their preferred language. Scottish Gaelic has fewer language technologies available than languages like English or Mandarin, and we’d like for our research in natural language generation to help in some small way to address this gap.
Why focus on ‘Exhibits’?
Museums are a primary tool for learning outside of schools, libraries, and documentaries, and are increasingly leveraging mobile applications and chatbots to enhance visitor experiences. However, these chatbots are generally available for only a few languages, due to a lack of linguistic and technical resources for minority languages like Scottish Gaelic.
How can I contribute?
If you speak Scottish Gaelic and live in Scotland, you can take our short comprehension quiz (5-10 minutes) and sign up to participate in the study! The full study (after the quiz) takes up to two hours to complete, and participants will receive up to £30 in compensation for their contribution. Additionally, you’ll have the opportunity to be named as contributing to this important Gaelic resource if you so desire! More details here: https://nlg.napier.ac.uk
If you don’t speak Scottish Gaelic or live outside of Scotland, you can share this blogpost with all the Gaelic speakers you know! Encourage them to participate or to spread the word to their friends. All in all, we hope to recruit about 100 people to participate in our study, and we have a ways to go before we reach this goal. If you don’t know what to say to your contacts, how about:
Researchers in Edinburgh are trying to build the first chatbots for Scottish Gaelic and they’re recruiting participants for an experiment paying up to £30! Find out more at: https://blogs.ed.ac.uk/garg/2022/08/23/scottish-gaelic-chatbots-for-museum-exhibits/ or sign up at https://nlg.napier.ac.uk
Today is International Cat Day and that is as good as excuse as any to look in the Tale Archive for any material purrtaining to Felis Catus. Don’t worry though – should you not hold with such cosy nonsense – for the tale I’ve chosen is far removed from cute and fluffy!
Tocher, Vol 7. (1972)
‘Sùil a Sporan agus Sùil a Dia’ was a tale given by Donald Alasdair Johnston on two separate occasions to fieldworkers for The School of Scottish Studies (SA1969.120.A1; SA1970.214.A1). It is classified as a variant of ATU 613 – Two Travellers. We have a third version of this type in the Tale Archive, which John Shaw collected from Cape Breton in 1978, from Flora MacLellan.
Donald Alasdair’s story was published in Tocher in 1972 and tells the story of two brothers. Sùil a Dia believed that God would provide all he needed in life, but Sùil a Sporan argued that his purse could provide him with everything. So serious was this argument that the best way to test this out – it seemed – was for Sùil a Sporan to dash out his devout brother’s eyes, in order to see if God would restore them.
Now blind, Sùil a Dia took refuge in a house which belonged to the King of Cats, Gugtrabhad, and his company. Sùil a Dia overheard the messenger kitten, Piseag Shalach Odhar, tell the clowder of a healing well. Once they left, the blind brother scrambled on hand and knee til he found the well, restored his sight and returned to his brother.However – if not dark enough already – this tale takes a few more sinister turns!
Sùil a Sporan asked his brother to put out his eyes next to make certain of the miracle. Once blind and alone, Sùil a Sporan felt his way inside the same house, to the same spot of refuge. When the cats assembled again there was outrage when Piseag Shalach Odhar told them that a human had been listening to them the night before. They hunted around the house and – mistaking Sùil a Sporan for his brother – exact their revenge. The story doesn’t really end well for anyone – certainly not Sùil a Sporan or the cats, ultimately, who meet a fiery end!
You can read the story as transcribed in Tocher (SA1969.120.A1), by clicking on the image below (link opens a pdf)
Click the image for a PDF of this tale, from Tocher, Vol 7 (1972)
Further Information
John Shaw wrote an article for Scottish Studies which compares Donald Alasdair’s tale with Sgeulachd a’ Chait Bhig ‘s a’ Chait Mhóir, collected from Cape Breton:
Shaw, J 1991, ‘Sgeulachd a’ Chait Bhig ‘s a’ Chait Mhóir‘, Scottish Studies, vol 30. Pp93-106
There are several versions of ATU 613 collected in Ireland, mainly in the Schools collection and these are held online at Duchas.ie: https://www.duchas.ie/en/aath/cbes/0613
For more cats in the collections held at SSSA, you can read this post over on the SSSA blog: Puzzling Black Cats

![Image shows metadata, a PDF and AI-recognised text for the Scottish Gaelic tale 'Biast na[n] Naoi Ceann' ['Beast of the Nine Heads']](https://blogs.ed.ac.uk/garg/wp-content/uploads/sites/1179/2025/06/Screenshot-2025-06-05-at-11.14.05.png)