
This post follows on from Unix file counting challenge, Part 2, which in itself follows on from Part 1. No surprises there.
Post Summary
These are the steps I’ve been taking in developing a short Unix shell script to count a lot of files and directories by type.
Step by tiny step through my Unix shell script development:
(The tininess of the steps is because I’ve already seen how impenetrably confusing Unix can get!)
-
Accessing the right file
First I checked I had the right process for reading the input file path from the command line and accessing it:
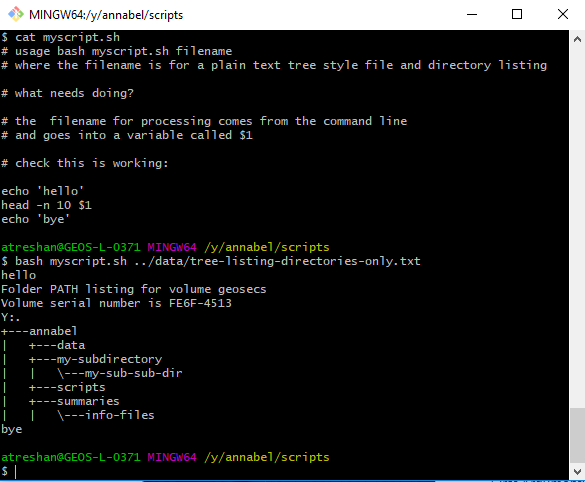
Screenshot showing the beginnings of the script and a first test run, reading the file path from the command line and accessing the data in the file
-
A question: How best to access the data?
Next, I had a question: given the large size of the data file, would it be best to read and process the data line by line from the file, or to read it all into an array and then access that?
It depends which uses the least bad proportion of resources available: accessing a file over and over again, or recreating a large amount of data in memory. Also, if I go for the file access option, does it open and close the file each time or does it stay open until I specifically close it at the end of data processing, and if so, can anyone else access it in the meantime? I assume they probably can’t nowadays, and in fact the whole thing might be copied into memory by the operating system anyway!
Still, this might be another chance to use the
timecommand, to compare how long each option takes. Yay, fun! -
Variable Assignment
I found some simple but useful guides to Bash variables (linked below).
Here are some basic points about using variables in Bash:- Variables can contain numbers and/or characters
- Variables do not need to be declared: they will be created when a value is assigned to them
- When accessing the value in a variable, put a
$at the start of the variable name, but don’t use the$when assigning the value - Variables can be used in the command line when calling a script, by adding them after the script’s filename
- These command line variables can be accessed by ordered numbered variables, starting from
$1, then$2, etc - The variable in
$0is the name of the script - The number of command line arguments is in
$# - It’s possible to return all the arguments by using the variables
$@and$* - Don’t put spaces around the equals sign in the variable assignment statement. Finally figured that out!
In the case of my script, initially I just wanted to use a meaningful name when reading the input filename from the command line. So the way to run the script in Git Bash is by entering:
bash myscript.sh filename,
where filename is the relative path from the working directory to the input data file. So to assign a better name to the variable, all I had to do was edit my script to add the linedatafilename=$1 -
Reading the Input File line by line
As the next screenshot shows, an input text file can be accessed and read line by line using a
whileloop, as for example:
while read -r textline
do
echo "$textline"
done < $"datafilename"
I found a small test file to practise on:Having read each line of text sequentially into my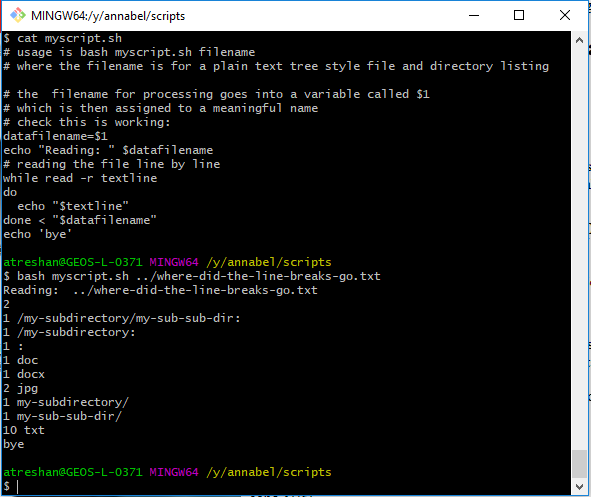
Screenshot: creating meaningful variable names and reading the input text file line by line, outputting the results to the terminal window
$textlinevariable, I now need to find out what I can do with them while I’ve got them as strings. -
String Data Processing
Thanks to the options used in my original file listing and counting commands, my text strings end in
/if they are directories and:if they are headings.For my next step, I thought it would be helpful to get the last character in each string, and then use it to filter out filenames into one list and directory names into another list.
I had a look through how-to files for
bash,awkandsed, to find out more, and then found this very helpful question and answer on Stack Overflow: Accessing last x characters of a string in Bash
Thanks to this answer, I could access the last character in each line of text using${textline: -1}and echo it to the terminal, as shown here:
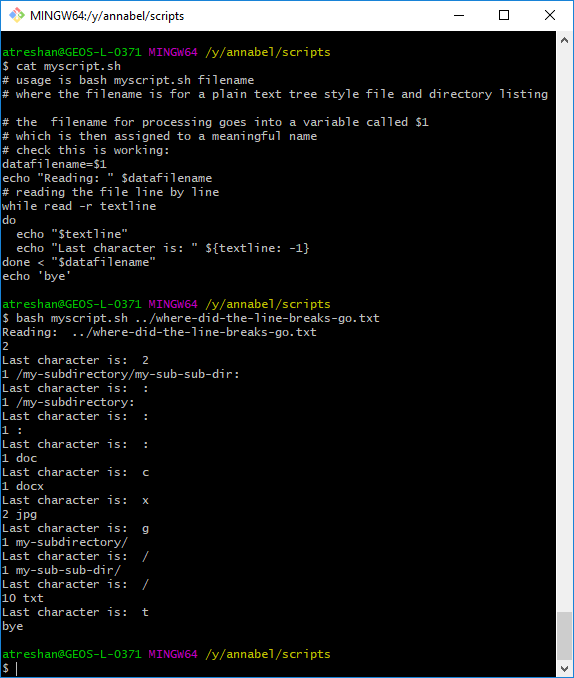
Screenshot showing the last character in each line of text accessed and echoed to the terminal. Woot!
The next step was to do some conditional processing based on that character. -
Conditional Processing
As a first test, to get the basics of conditional processing right, I went for the most basic option of testing for the last character being a forward slash,
/, and appending those lines to an output text file.I thought I was keeping it simple, but even this most basic approach took nearly two hours of googling, tweaking and experimenting with different combinations of the different bracket shapes, spacing and whether to test for equality with ‘
==‘ or ‘-eq‘ that appeared in the explanations online. Eventually I was lucky enough to get a little help and some moral support, which was needed by that point: however much it might make me feel like a 1980s hacker, I was about ready to throw Unix out of the window at times!Finally, I found this combination that worked:
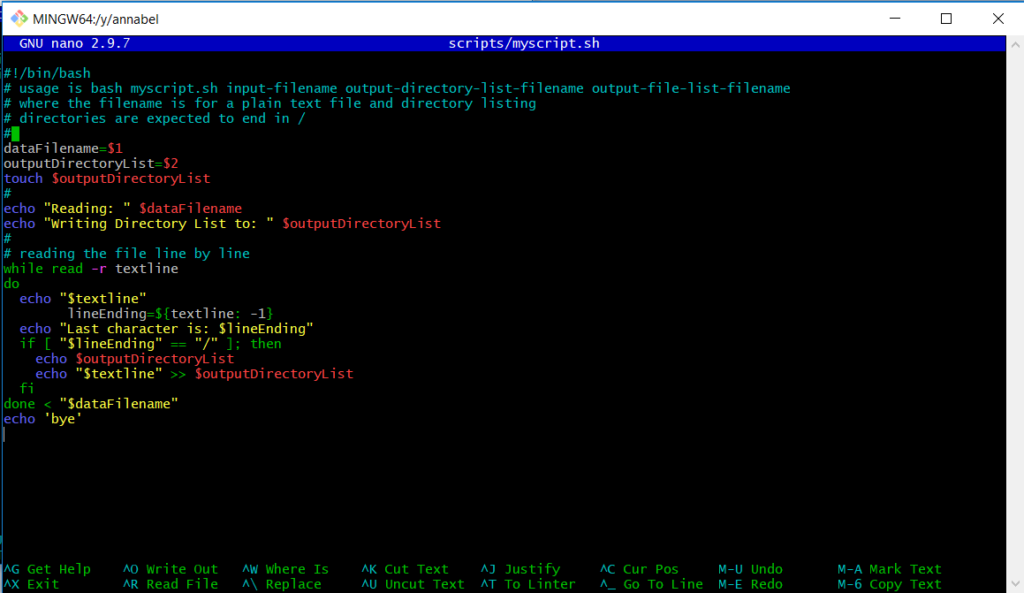
Screenshot: getting the first conditional processing working in the nano text editor, as if Unix itself wasn’t user-unfriendly enough. They’ll be typing with rubber gloves and a blindfold on next.😬
The next screenshot shows the program running (as demonstrated by some console logging messages), the output file that lists two directories, and the input file, which lists the same two directories among a mixture of other lines:
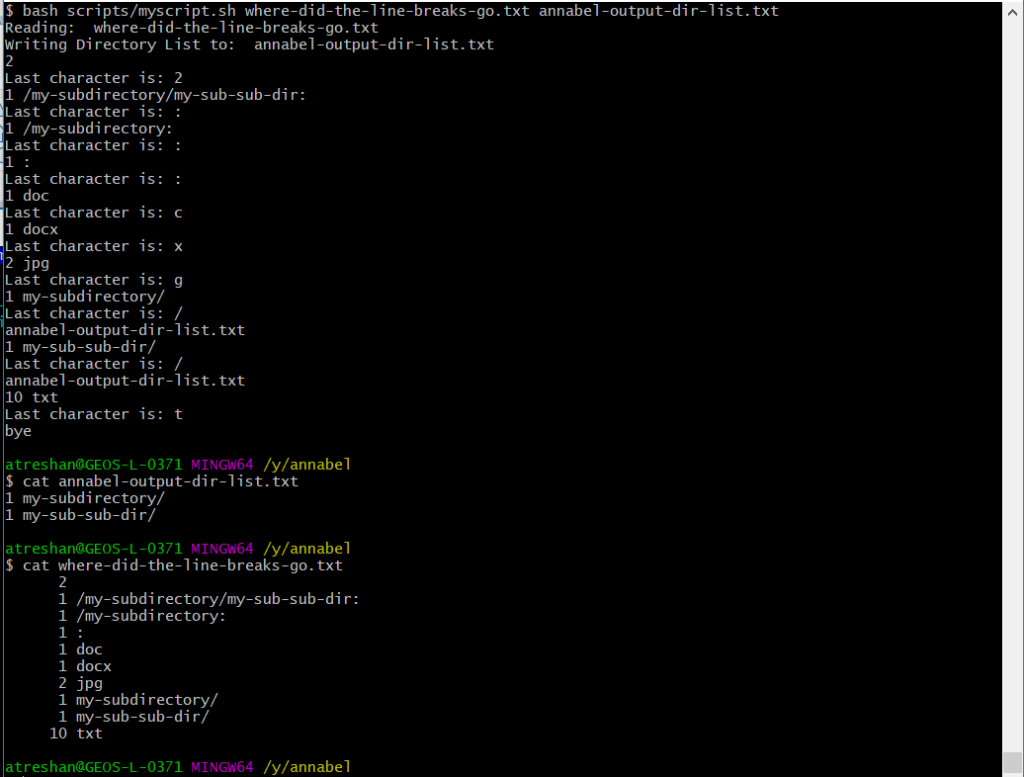
It works! It works!! A-HAHAHAHAHA it works!!! HA Unix! Thought you’d get me with your spacing and your brackets!! HA!
The next step will be to add more conditions to theifstatements (and Ok, I love that theifstatements end withfi!), and divert the listings of files to a second output file. -
A better Editor
At this point I also had the genius idea of switching my code editing from
nanotoAtom. 😏 Finally! This will make it MUCH easier to find my way around the code, find line numbers, switch between windows, save my work and copy and paste my code as text. -
The code so far…
#!/bin/bash
# usage is bash myscript.sh input-filename output-directory-list-filename output-file-list-filename
# where the filenames are for plain text file and directory listings
# directories are expected to end in /
#
scriptName=$0
outputDirName="outputs"
errorDirName="errors"
errorFileName="errors.txt"
errorFile=$errorDirName"/"$errorFileName
statsFileName="stats.txt"
statsFile=$outputDirName"/"$statsFileName
dataFilename=$1
outputDirectoryList=$outputDirName"/"$2
outputFileList=$outputDirName"/"$3
touch $errorFileName
mkdir -p $errorDirName 2>&1 | tee -a $errorFileName
mv $errorFileName $errorFile
mkdir -p $outputDirName 2>&1 | tee -a $errorFile
rm $outputDirectoryList $outputFileList 2>&1 | tee -a $errorFile
touch $outputDirectoryList $outputFileList $statsFile 2>&1 | tee -a $errorFile
#
lineCount=0
blankLineCount=0
fileCount=0
dirCount=0
echo "Hello"
echo "Running script: " $scriptName " on " | date | tee $statsFile
echo "Reading: " $dataFilename | tee -a $statsFile
echo "Writing Directory List to: " $outputDirectoryList | tee -a $statsFile
echo "Writing File List to: " $outputFileList | tee -a $statsFile
echo "Writing Summary Stats to: " $statsFile | tee -a $statsFilewhile read -r textline
do
lineEnding=${textline: -1}
((lineCount++))
echo $textline
# echo $lineEnding
if [ "$lineEnding" == "/" ]; then
((dirCount++))
echo "$textline" >> $outputDirectoryList
elif [ "$lineEnding" == ":" ]; then
((blankLineCount++))
else
((fileCount++))
echo "$textline" >> $outputFileList
fi
# if [[ "$lineCount" -gt 100 ]]; then
# exit 1
# fi
done < "$dataFilename"
echo $lineCount " lines processed" | tee -a $statsFile
echo $blankLineCount " blank lines found" | tee -a $statsFile
echo $dirCount " directory names found" | tee -a $statsFile
echo $fileCount " file types found" | tee -a $statsFile
echo "Finished on " | date | tee $statsFile
echo 'bye' | tee -a $statsFile
The indentation has pasted in a bit strangely but the code so far is all there. If only it was working! It’s not recognising the trailing slash on directory names in the real input file. I’m currently running the long process to try making another list file. (This is the command I’m trying at the moment):
$ ls -R1ult --time-style=+"%Y" | cut -d $'\t' -f 5,6,7 > annabel/data/file-list-size-year-tabs.txt
I just know it’s so nearly there! -
Line feeds strike again!
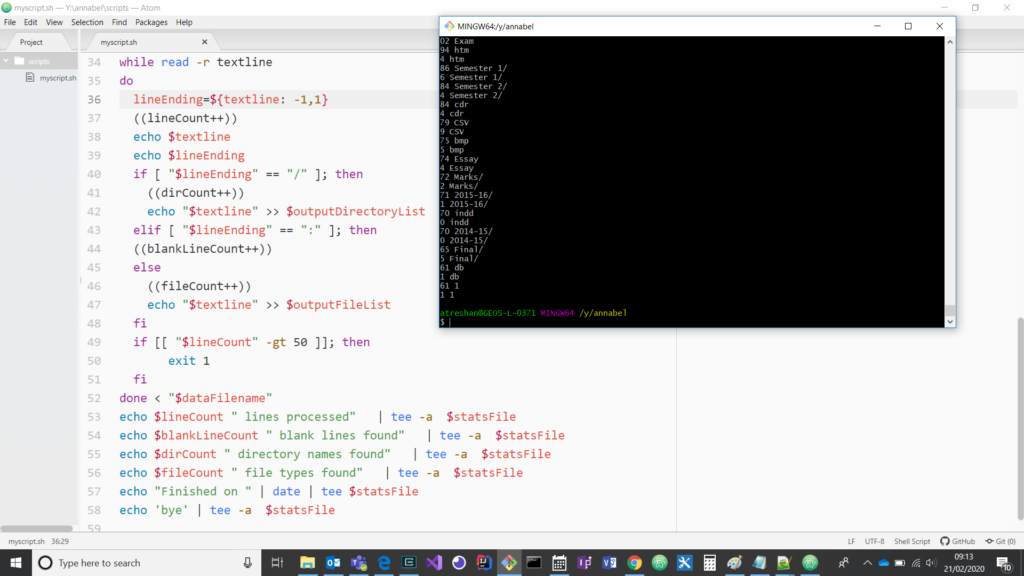
Screenshot with console log output showing the program picking up line feed characters as the end of the line
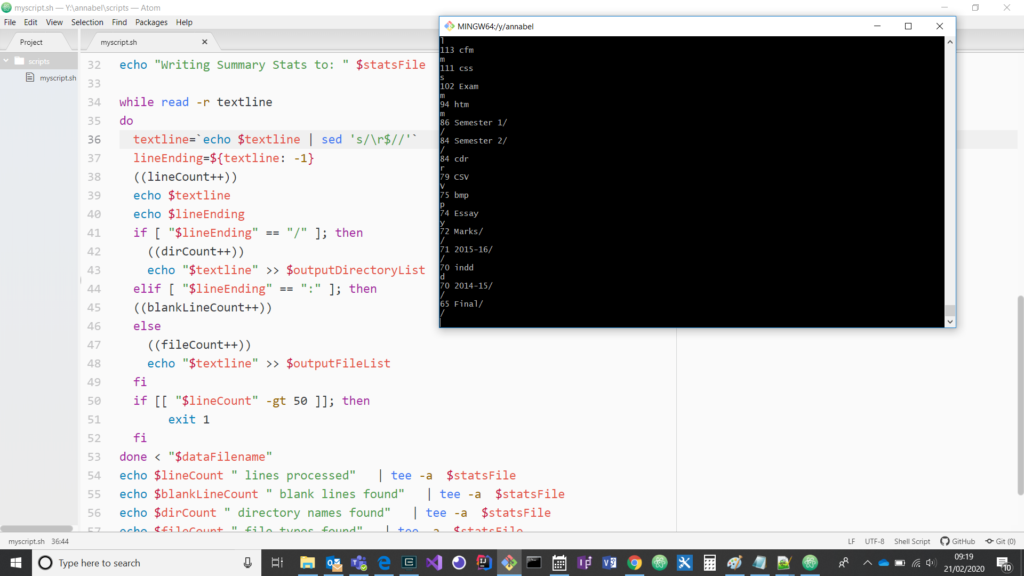
Code and output screenshot showing the line feed issue fixed with sed
-
Re-run – will the endings be right this time?
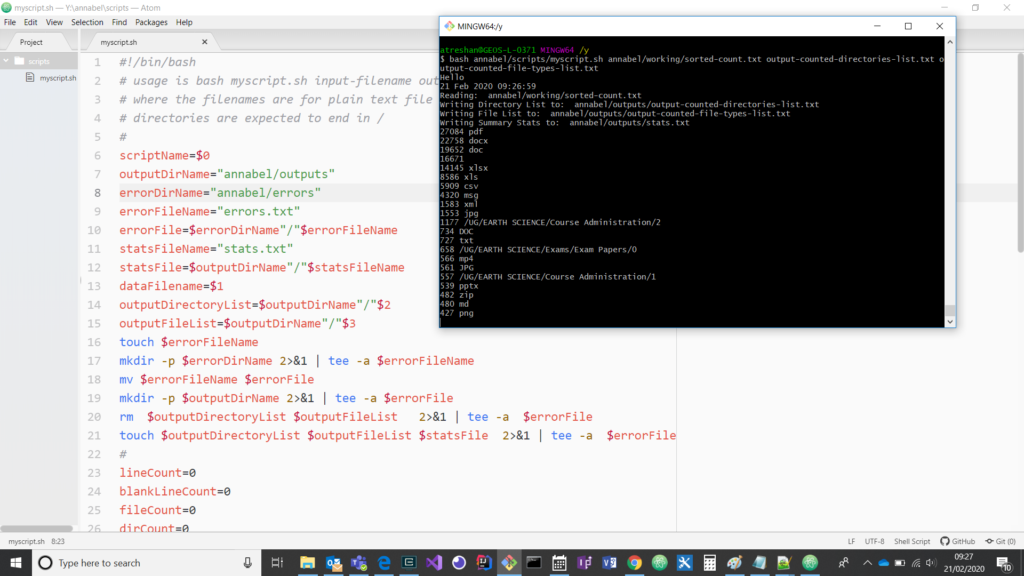
Screenshot of the program running again, with edits to directory locations. It’s listing about one per second so this could take a while…
To be continued…
Links
- Software Carpentry – The Unix Shell
- How to read command line arguments in a bash script
- Variables – BASH Programming – Introduction HOW-TO
- Variable Assignment – Advanced Bash-Scripting Guide: Chapter 4. Introduction to Variables and Parameters
- Linux/UNIX: Bash Read a File Line By Line
- Accessing last x characters of a string in Bash – Stack Overflow
- Bash Guide for Beginners – Chapter 7. Conditional statements
- bash programming-append single line to end of file – LinuxQuestions.org
- How to append output to the end of a text file – Stack Overflow
- How can I declare and use Boolean variables in a shell script? – Stack Overflow
- Bash scripting cheatsheet – Devhints.io
- How to Increment and Decrement Variable in Bash (Counter)
- How to mkdir only if a dir does not already exist? – Stack Overflow
- How to redirect output to screen as well as a file? – Stack Overflow
- bash ls; output a time of modification of files including year and seconds [closed] – Stack Exchange
- 7.2.5. Using the exit statement and if – Bash Beginners Guide
- 6 Bash Conditional Expression Examples ( -e, -eq, -z, !=, [, [[ ..) – The Geek Stuff
- How do I use cut to separate by multiple whitespace? – Stack Exchange
- How to define ‘tab’ delimiter with ‘cut’ in BASH? – Stack Exchange
- How to automatically repeat YouTube videos – Computer Hope
(Main image: No surprises - Radiohead, via YouTube. Buy & stream it here: https://radiohead.ffm.to/okcomputer)


Leave a Reply