
Summary:
I’ve got a project coming up that will involve some major tidying up of a big shared network drive that has been used in different ways by many different people over many years.
One of the first steps is to find out what kind of files are on the network drive, how many of them there are, whether they’re still being used, and where they are stored in the directory structure.
I use a Windows laptop at work, which has a VPN connection to the University’s network and a MacBook at home, which doesn’t (yet). I’ve also been attending a training course in Unix skills, which seem like they could usefully be applied to this problem, and I’ve been really enjoying finding out more about this.
So that’s the combination of things going on.
This post is continued from Part 1, which is:
Can I turn a massive bureaucratic, er, challenge into a fun Unix challenge?
Here’s my progress so far:
- I’ve produced a complete tree style file and directory listing in a (massive!) text file. In the process, I discovered that each of my Unix terminal versions had a different version (or no version) of the
treecommand, and in fact I ended up calling the Windows command line to execute itstreecommand, and having Unix send the output to a text file. I could have run more commands on it in between, but I thought the plain, structured text listing would be useful in its own right. - I’ve uploaded the text file to a shared directory on SharePoint and imported it into Word, so we can add notes alongside the directory listings. The Word file turned out to be 3138 pages long.
- I ran some Unix terminal commands intended to list each file extension type, sort them, count them, and write that output into another text file.
The command I came up with that produced the output file was:
$ time ls -R1 --sort=extension | cut -d . -f 2 | sort | uniq -c | sed 's/$/\r/' > annabel/big-file-count.txt | date,
followed by:$ cat working/big-file-count.txt | sort -r > data/sorted-count.txt,
to rank the results by file count and write the results to a second text file.(The time and date were because I could tell it would take a long time and wanted to measure it!).
I’d say that was close to working, but the results are not completely accurate because of irregularities in the file naming (see examples below). It also took nearly 23 minutes to run, and I realised afterwards that the
sortbefore thecutwas no longer necessary, while a secondsortwas needed to rank the list by file count afterwards instead. So the improved version of the command would be this:
$ ls -R1 | cut -d . -f 2 | sort | uniq -c | sort -nr > annabel/data/sorted-count-2.txt
- My next step will be to tracking down the causes of the errors appearing in the count output file. This is important to know for two reasons:
- so that I can use shell scripting to improve on the accuracy of the file count.
- so that we have a better idea of the administrative procedures being used before we try to adapt them to SharePoint.
Here are some examples of what I mean by irregularities in the data:
Example 1: Dots used in directory names
Looking through the directory structure, I discovered that one type of the odd errors in the count output file was caused by someone giving some of the subdirectories inside the PGT directory names like 2005.2006, and this is why (for example) 49 /PGT/MSc GIS cluster/[Name removed] GIS archive/2005
appears in the count file, because I used the . to separate the file paths into columns to get the suffixes. Here is a screenshot, with names removed:
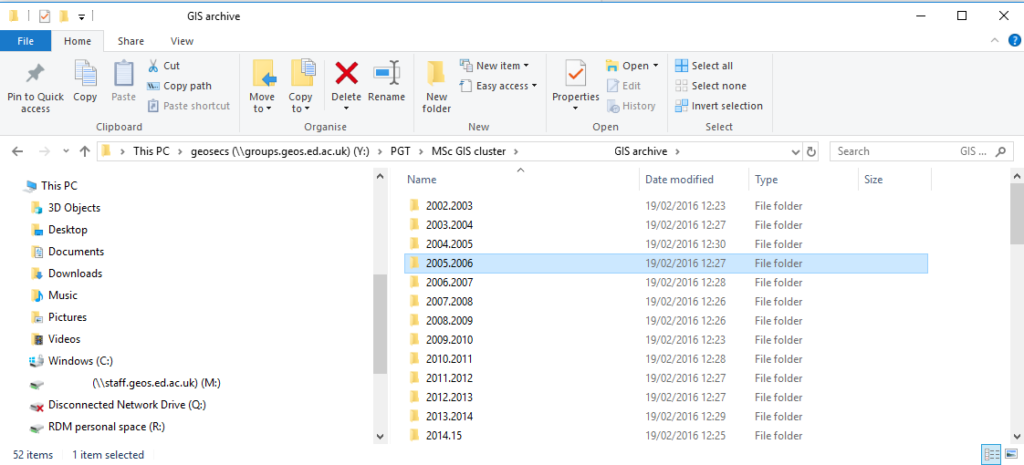
Screenshot of directory structure in Windows, showing names joined by full stops.
Example 2: Message text stored as a filename
Next, I tried using the Unix grep command to search the tree directory listing output file for some of the odd text strings that appeared in the file counting output file, and I discovered that many of them were text messages, ending in ‘.msg’, that were for some reason also stored as filenames on the network drive. Here is an example screenshot, in which I searched for the string ‘Anne has booked own flights’, which was listed in the file count:
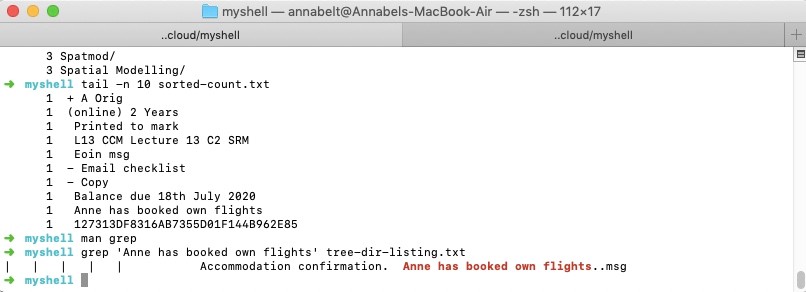
‘Anne has booked own flights’ in both the file count output and the grep results from the tree directory listing
How much of a problem was this, and what opportunities does it offer?
Opening the sorted count files in Notepad++ allowed me to check the beginning and end line numbers to find how many of each file type there were once I got to the point where counts were more likely to contain errors. So here are some examples:
| File Type Count | Beginning line | End line | Total |
|---|---|---|---|
| 10 | 315 | 348 | 34 |
| 9 | 349 | 384 | 35 |
| 8 | 385 | 437 | 53 |
| 7 | 438 | 493 | 55 |
| 6 | 494 | 586 | 93 |
| 5 | 587 | 736 | 150 |
| 4 | 737 | 967 | 231 |
| 3 | 968 | 1411 | 444 |
| 2 | 1412 | 3060 | 1649 |
| How many lines were unique? | |||
| 1 | 3061 | 24297 | 21237 |
Scrolling through the counts file and comparing it with the numbers in the table above, in general there are different characteristics in the data, with the most organised data appearing at the top, and the most anomalies appearing near the bottom.
We can also find out more about how the admin systems are being used by looking beyond the summary numbers. I had a look through the sorted count file in a meeting with my manager and we found some interesting examples that would be useful to discuss in planning the new system, as well as getting ideas for some of the SharePoint content types that we could be creating for it.
Here are some example sections of the sorted count file:
Beginning of File: Most successfully counted
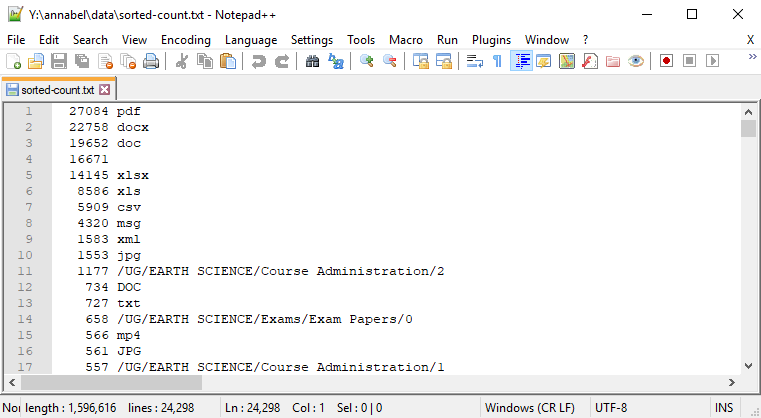
The first 15 lines of the sorted counted list file, and pdf is winning! Yay pdf!
Although this part of the list appears most organised, several issues are already clear:
- I will need to alter my search to be case insensitive, as for example, files with
.docand.DOCextensions are being counted separately - We have 16,671 mystery entries that are blank. Could these have been file or directory names that ended with ‘
.‘? Why? And if not, what else are they? - We have older and newer versions of the same file type, eg ‘
.doc‘ and ‘.docx‘. Do we count those as the same (giving us more Word files) or different (giving us more PDFs)? - Why on Earth (no pun intended) do we have 1177 of ‘
/UG/EARTH SCIENCE/Course Administration/2‘?
Lower counts: Less common file types
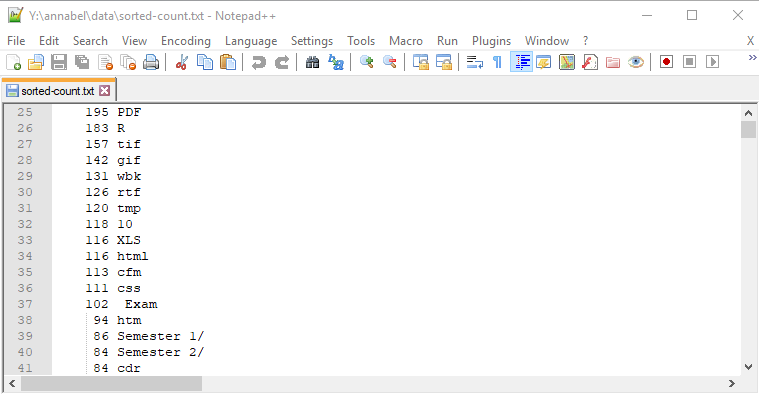
Lower numbers in the sorted count file: older and less common file extensions and commonly used directory names
This section has an interesting crossover of directory names that it makes sense to see appearing often, and older or less common file types such as .cfm (ColdFusion), .cdr (Corel Draw) .css (Cascading Style Sheets), .R (a statistical programming language), .htm (a less common alternative to .html), and .PDF, the capitalised version of .pdf.
In the case of the directory names, seeing 86 of ‘Semester 1/‘ and 84 of ‘Semester 2/‘ with the same capitalisation, number format and spacing, suggests to me that either a naming convention or copies of standard directories were being used, and it makes sense that these directory names would be used very often in this context.
I also wondered if some of the admin staff might have been making useful empty directory structures as templates that they could copy from one course or year group to another.
What kind of things are there 2 of?
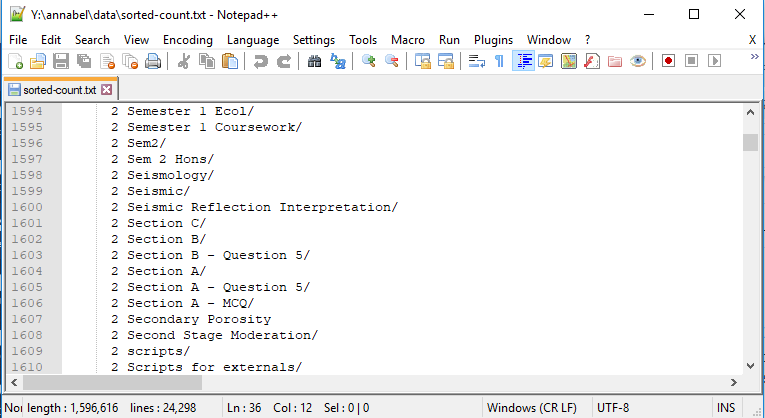
Sample list of names that appear twice
To me, seeing two of each of these unusual, related looking directory names implies either a backup copy somewhere within the same drive or a directory structure that has been copied and pasted from one year’s course to the next.
End of File: The last of 21237 unique items
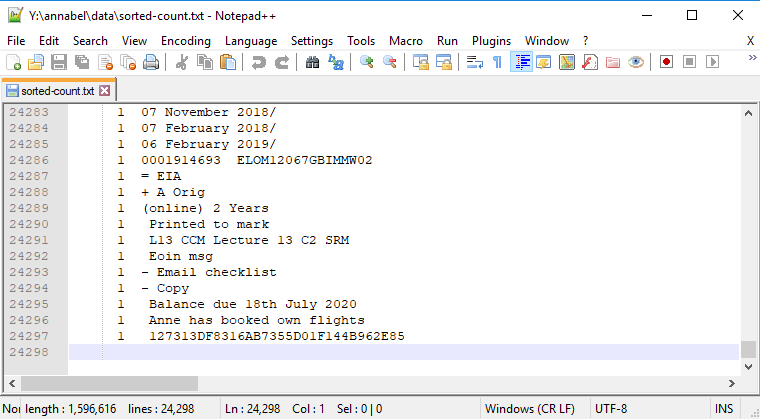
Last 15 lines in the sorted counted file, showing disorganised text strings
Could backups be the cause of some errors?
As someone who has far too many duplicate backups of old photo directories, I thought backups within the same directory structure might have been the cause of many (or many, many, if it was my old photos!) of the entries that appeared two or more times, but weren’t file suffixes, so I did some more tracking down with grep, as well as visually looking through the Windows directory structure.
Replicating directory structures
When I used grep to search for text strings, I was expecting to find backup directories. Instead, I discovered that certain directory names were being repeated from year to year, and possibly from one course to another. If this was common practice, it could explain a lot of the repeated text strings:
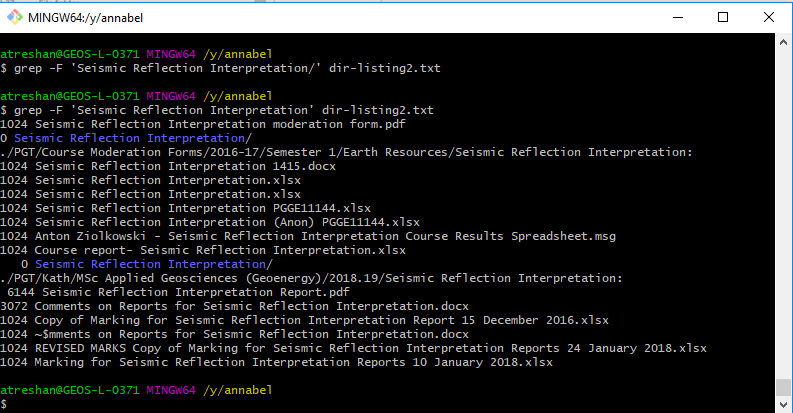
Some directory names (eg Seismic Reflection Interpretation in this example) were replicated from course to course and from year to year
However, I was probably right in guessing that backup directories could be the cause of some of the other repetitions. Here’s a sample screenshot showing many directories called ‘Archive’ being used:
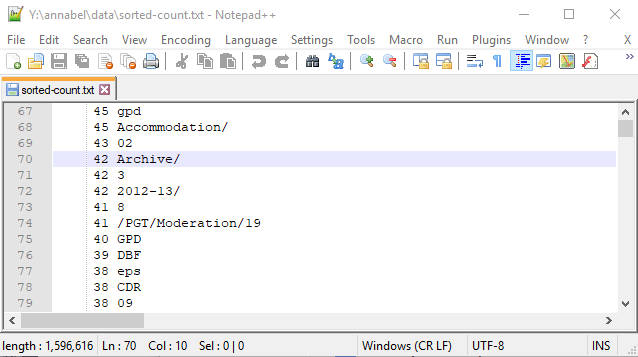
Sample listing including a count of 42 directories called ‘Archive’
Here’s another example, showing archived directories of promotional materials that may or may not be in use any more:
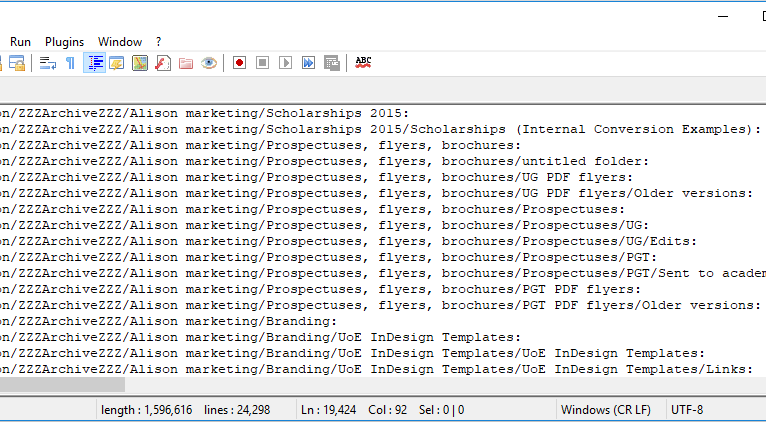
Sample listing of marketing directories archived under ‘ZZZArchiveZZZ’ – not the most exciting sounding place for promotional materials
Other issues raised:
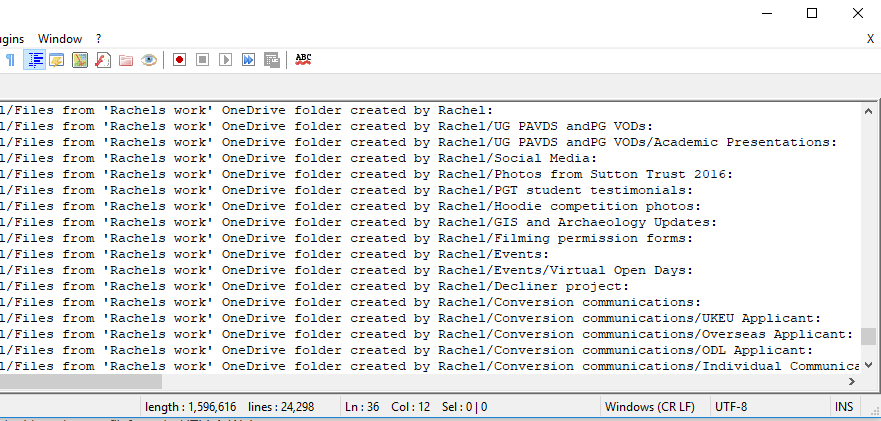
Line beginning 23030: Directories imported from a member of staff’s personal OneDrive area
This screenshot shows two of the types of problems that this project is intended to improve on: standardisation and data protection compliance. The screenshot lists many directories that had to be copied across from a member of staff’s personal OneDrive area, perhaps when that member of staff left. Even if the member of staff only moved to another office within the University, files stored on their personal OneDrive would not necessarily be accessible to their original office any more.
Here’s another standardisation issue: should naming conventions consistently use sentence case, lower case, or upper case, as this person has:
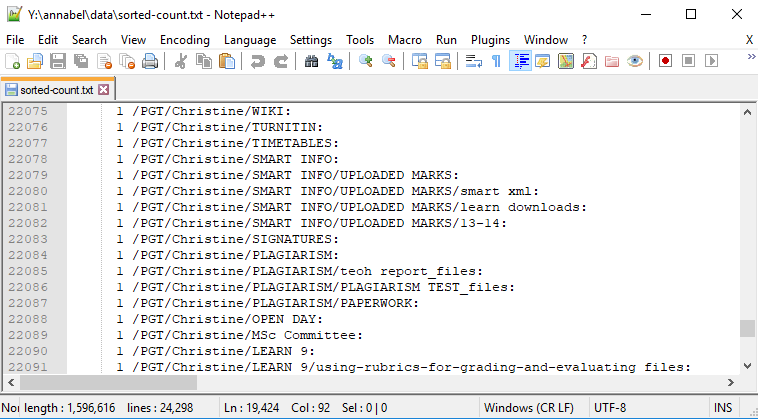
These directories were louder than the others
Another standardisation question: should things have an ‘s’ on the end or not?
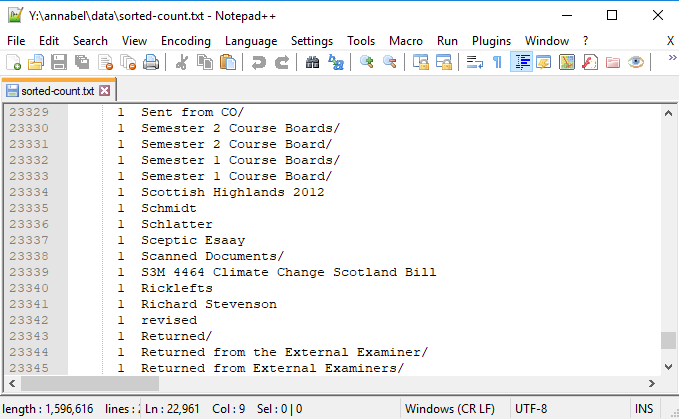
‘Course Board’ and ‘External Examiner’, listed with and without an ‘s’ on the end
Some of the directory names also suggest they may have contained older communications data, reminding us that data protection issues relating to the newer GDPR legislation should also be checked up on, although there is no actual data listed here.
Other sections give us whole lists of directories that can be deleted, such as dissertation feedback forms, because they have been replaced by new SharePoint systems already, and copies of dissertations which have also been anonymised and uploaded to a SharePoint repository:
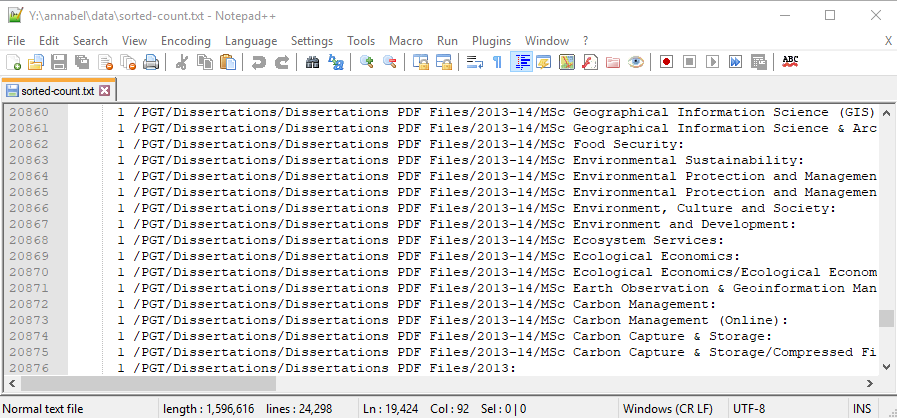
Old dissertation files means lots of extra storage being used for duplicates of what we have on SharePoint
Still more sections give us lists of directories that can be deleted because they relate to old software versions that predate our current systems:
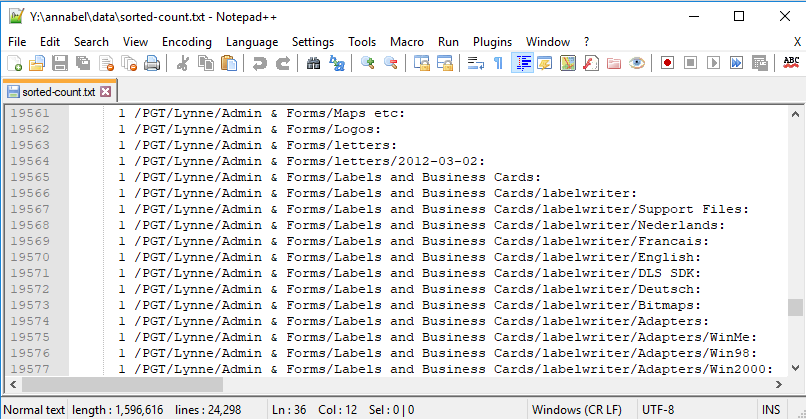
Windows Me, 98 and 2000 adapters, anyone?
Others have minutes of long ago meetings: which ones do we still need?
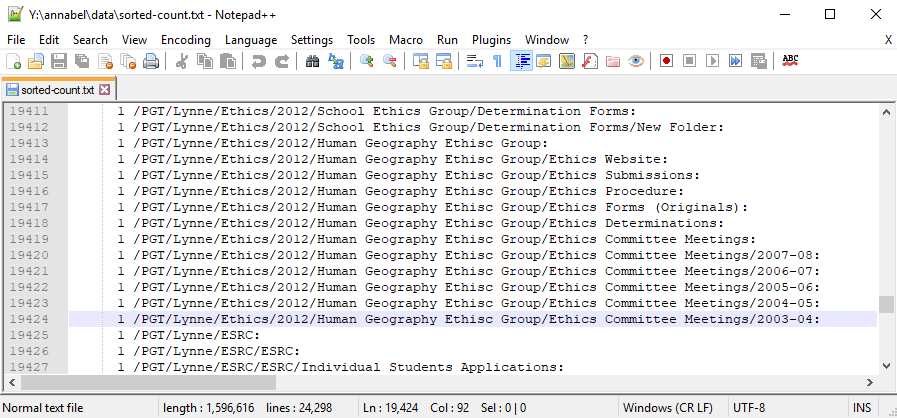
Ethics: have they changed since 2003-4?
A new Tree Listing
I decided a new tree listing of directories only would give us a more useful overview of the filing system structure for answering some of these questions, as it would be much shorter and clearer than the version with files in.
I used my Cmder emulator to run the tree command with Windows options to clear up the output text and then sent it to a new text file, Unix style. The command I used was: tree /a > annabel/data/tree-listing-directories-only.txt.
No I don’t know why it worked that way but it did, so here it is with the first 20 lines of the results:
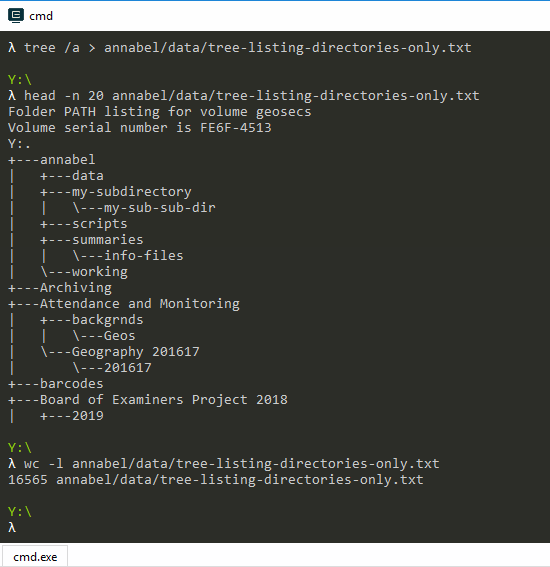
Screenshot showing the tree listing command and the first 20 lines of the output text file, then the wc -l command to get the output line count
Finally, the
wc -l command after it gives the line count of the output text file as 16565, giving a total of 16562 directories and subdirectories once you subtract the first three lines that are extra text for information purposes.
To be continued…
Links
- Notepad++: Very useful text editor with line numbers
- Cmder: Very useful Unix console emulator for Windows
(Scarlett O'Hara: "After all, Tomorrow is another day!", Gone With the Wind, via MagicalQuote.com. This is definitely the kind of thing she had in mind.)


Leave a Reply