Well.
I have been given an enormous number of files of different types, in many jumbled up directories and subdirectories on a network drive, to count. That ought to be a job for the Unix commands and shell scripting I’ve been learning at Software Carpentry over the last couple of weeks, right?
My initial thoughts were that this could be done with either the command line, probably involving ls, sort, regular expressions with uniq and counting options or a shell script looping through a file listing with some combination of those.
Time to fire up Git Bash, my trusty Unix terminal for Windows…
My first step was to look up the various options for the ls (list files) command. This can be done by typing ls --help in the Git Bash / Unix terminal window, but they’re also available online in the Software Carpentries course materials here: http://swcarpentry.github.io/shell-novice/02-filedir/index.html#the—help-option
I was thinking at first it would be helpful to list through each directory recursively, with file types, authors, and dates of last access.
I would also like to save the ls output to a text file, thinking there would be lots of helpful grep (get regular expression and print) and wc (word count) search type commands I could run on an output text file to get more summary information.
Realising this, my next step was to make an ‘annabel’ directory to store my output text files in, making my problem only slightly bigger. 😁
This is a sample of the output to my terminal window when I tried the ls command without any options (note, this only lists the top level directory contents):
Terminal window screenshot showing a sample of the ls command output with no options
Next I tried all the options that looked handy, saving the output to a file, and causing myself an error message too:
ls -RFaSslcu1 --color --file-type --author --group-directories-first >annabel/dir-listing.txt
ls: reading directory './.TemporaryItems/folders.501': Input/output error
$ less annabel/dir-listing.txt
"annabel/dir-listing.txt" may be a binary file. See it anyway?
Yep. Not that.
These are the options I tried, by the way:
| Option | What it was meant to do | Did it work? |
|---|---|---|
-R |
list subdirectories recursively | Yes |
-F |
append indicator (one of */=>@|) to entries | Hard to tell, but no |
-a |
do not ignore entries starting with . | Yes: probably the cause of the error |
-S |
sort by file size, largest first | Hard to tell – may have sorted files within directories – yes, this is what it does |
-s |
print the allocated size of each file, in blocks | Yes |
-l |
use a long listing format | Yes |
-c |
with -lt: sort by, and show, ctime (time of last modification of file status information); with -l: show ctime and sort by name; otherwise: sort by ctime, newest first |
Hard to tell – doesn’t change which time is shown but does sort by time if both -l and -t are also there |
-u |
with -lt: sort by, and show, access time; with -l: show access time and sort by name; otherwise: sort by access time, newest first |
Yes – I think this could be useful |
-1 |
list one file per line. Avoid ‘\n’ with -q or -b | Yes, but not with the first set of options |
--color |
–color[=WHEN] colorize the output; WHEN can be ‘always’ (default if omitted), ‘auto’, or ‘never’; more info below |
Not in this case, but default may have been not to use colour |
--file-type |
append indicator (one of */=>@|) to entries, except do not append ‘*’ | Possibly, but not in the way I wanted |
--author |
with -l, print the author of each file | No: lists me as the author of everything! |
--group-directories-first |
group directories before files; can be augmented with a –sort option, but any use of –sort=none (-U) disables grouping |
Yes, though not with the first set of options, maybe because it didn’t complete |
> |
Send output to a file | Yes, at least until the error |
The output that did make it to the file was a solid mass of unreadable mostly text, like this:
Unreadably garbled text output file
Next I tried removing the -a and -l options to fix the Input/Output error and make the output a bit more readable:
$ ls -RFSscu1 --color --file-type --author --group-directories-first >annabel/dir-listing2.txt
Well, the error was gone but the output file was still a jumbled up mess:
Directory Listing 2 (word wrapped, showing directories grouped and listed first)
It also took an impressively long time to run!
So next, I tried making a small test file and directory structure, cutting out most of the options, introducing some that I thought would tidy up the output and testing them by reintroducing them one at a time to find a good combination:
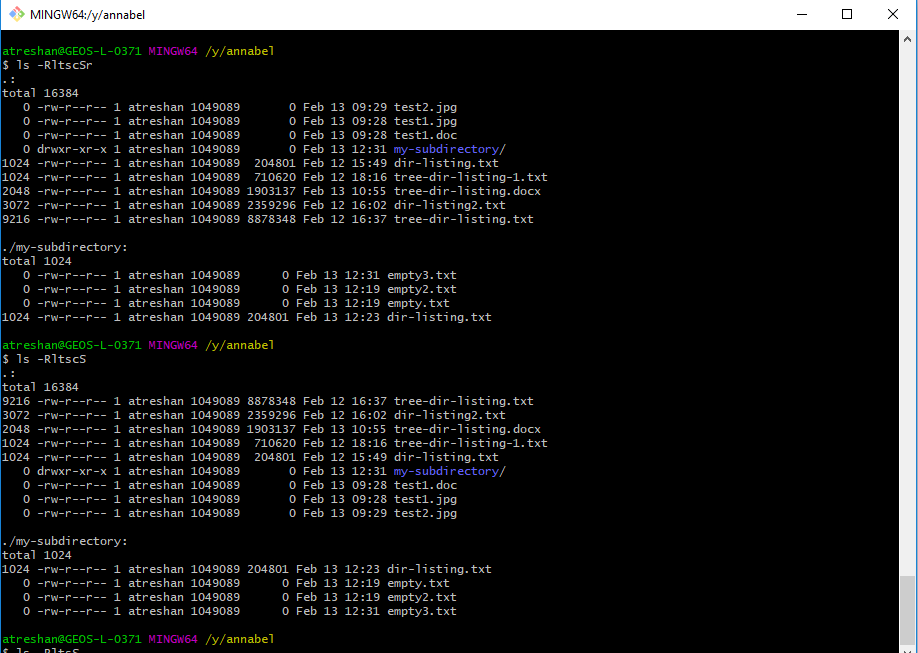
Test file and directory structure showing the output from two sorts
One important thing I discovered was that when two sorting options are used, the output ends up sorted by the last one (as in the screenshot above).
I was also able to update my table of ls options (above) once the simplified test directory structure gave me a clearer view of how (and if) the options were working in my Git Bash terminal.
I settled on a minimum of -R (which lists through each directory and subdirectory recursively), and -1 (which lists a single file on each line of text output).
The -u option (showing and sorting by last access time) also seemed like one that could be useful in future, for determining which files are still being used, while -s or better still -lh looked useful for comparing their size:
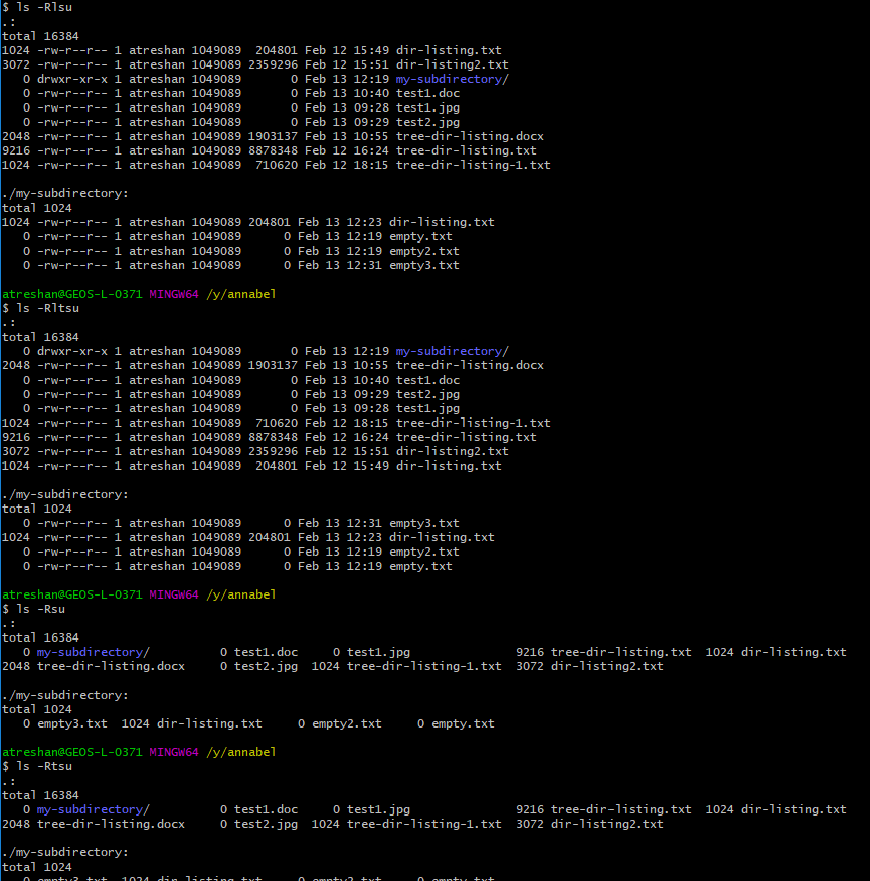
Listing and sorting with the -u option
Another thing I thought would be very helpful would be to get a tree style listing of the file and directory structure. I know that Unix has a tree command that would be ideal for this purpose, but it turns out tree is not included in Git Bash.
That leaves me two options:
- Find another way to run
treein Git Bash - Find a different shell terminal that will run
tree
– and luckily both of these are possible.🤪 Kind of.
Option 1: Run tree another way in Git Bash:
According to a very helpful answer on SuperUser.com, Git Bash can call the Windows terminal cmd’s tree command by using cmd //c tree to launch cmd with the ‘/c‘ argument to run tree and then terminate (the extra slash before the /c is for escaping).
This is a sample of the output to my terminal window when I tried cmd //c tree:
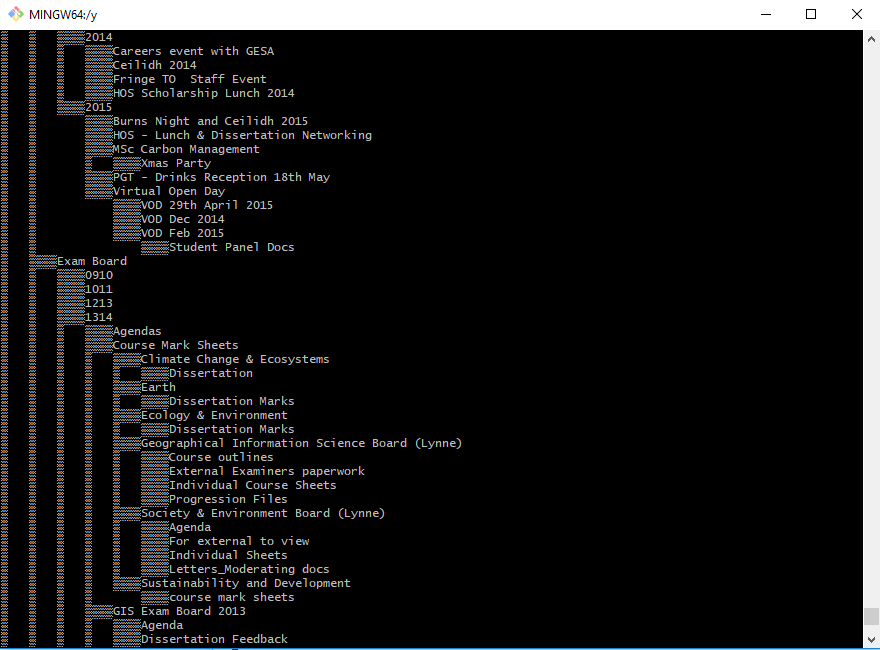
Tree style directory listing with unreadable blocks and no suffixes to show file types – as I eventually realised, this was because only the directories were listed
Unsurprisingly, the output text file wasn’t much better:
Tree style directory listing in output text file with unreadable character codes
Reading the Microsoft documentation led me to add a couple of options to the tree command as follows:
/f |
Displays the names of the files in each directory. |
/a |
Specifies that tree is to use text characters instead of graphic characters to show the lines that link subdirectories. |
That gave me this command:
cmd //c tree //a //f > annabel/tree-dir-listing.txt
which gave me a much clearer and more useful output file to work with:
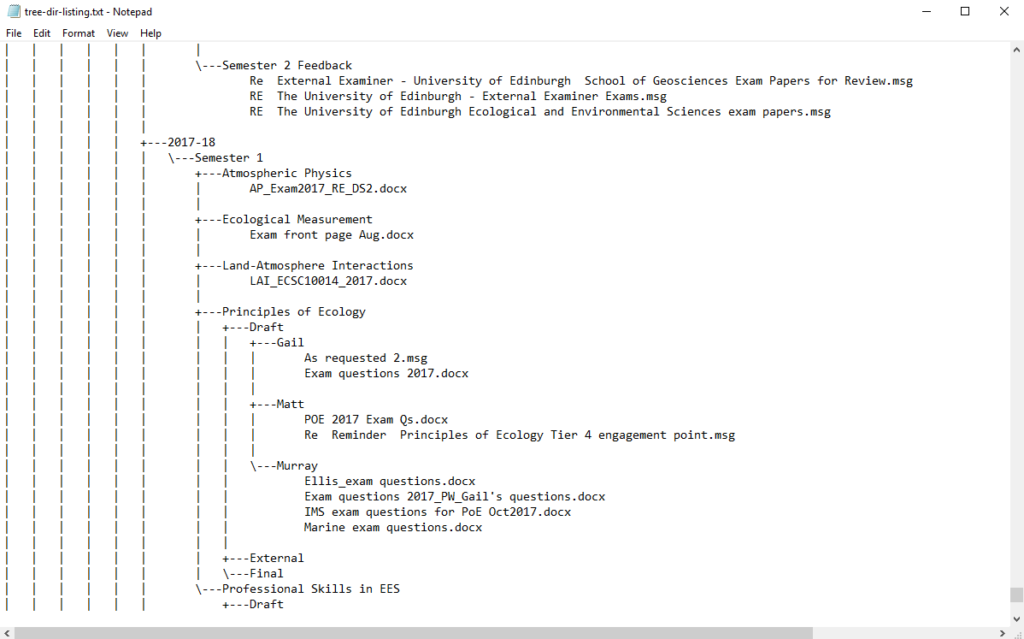
Sample of the output text file showing tree directory structure and files with file type suffixes
(Ironic that it’s been a Windows command that’s been most helpful in my Unix terminal so far – better still, this tree command was even there in MS-DOS!)
During the morning phone meeting with my manager, we decided to import the first tree listing text file into Word so we could add notes, and I uploaded both the Word and text files to a shared directory in SharePoint. On opening the file in Word, I discovered the directory listing was 3138 pages long – we have quite a job ahead of us!
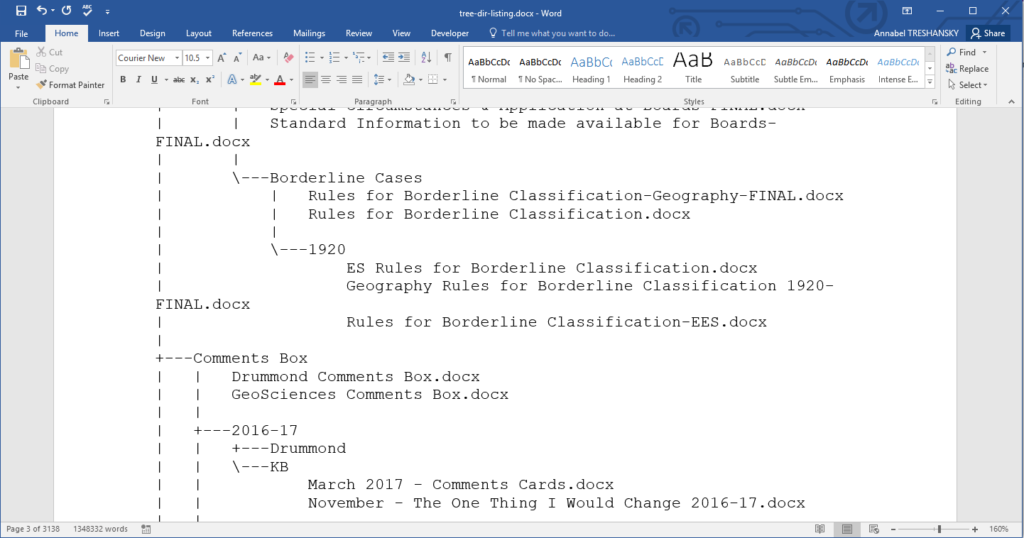
Screenshot from Word, showing the page count as 3138 and word count as 1348332
Option 2 (remember those 2 options?): Find another terminal window that will run tree:
Although I had already created the tree directory text file the first way, I felt it was still worth trying option 2 because of the extra options available for running with the tree command.
Luckily, my other Unix terminal emulator, Cmder, does include the tree command:
Using more for a paged listing of my directory tree in Cmder. I see node_modules, so this could go on a while…!
Now I just have to find my way to the right part of the network, because Cmder doesn’t recognise my mapped Windows network drive 😬
Here’s the fun time that that was, but the upshot of it is that the way to find it in this case is by typing y: (as my mapping of the network drive is to Y – in my Git Bash window it is cd y: ):
Finding my mapped network drive in Cmder – yay
But…
After all that, the Unix command options for tree don’t work in Cmder anyway 🙄
(I found out later that the Windows command options do).
Looking a bit more into cmd, I think Windows PowerShell must have a way to do this too. But I don’t know anything about that at all.
Next I tried logging into one of our Linux computers using Remote Desktop Connection, which took me to yet another different starting point and Unix setup within our network, and I haven’t figured out how to get to the right location yet*.
So, it’s Press on with Option 1 then…
Google is my Friend
Back in Git Bash, I may have found something exciting with some Googling – something that wasn’t in the original list of options for ls:

The --sort=extension option allows for ls with sorting by file extension! Yay!!
Extreme Progress!
Having found the option for sorting by file extension, I knew the commands I already knew could get me the rest of the way. I tried a couple of experiments with listing and sorting with wildcards, but they didn’t get beyond the top level directory. Next, I tried out piping the output from --sort=extension to the uniq command with the -c option to count each unique line. Obviously the lines weren’t yet ready to be compared though, because I still needed to separate out the file extensions from the rest of the text:
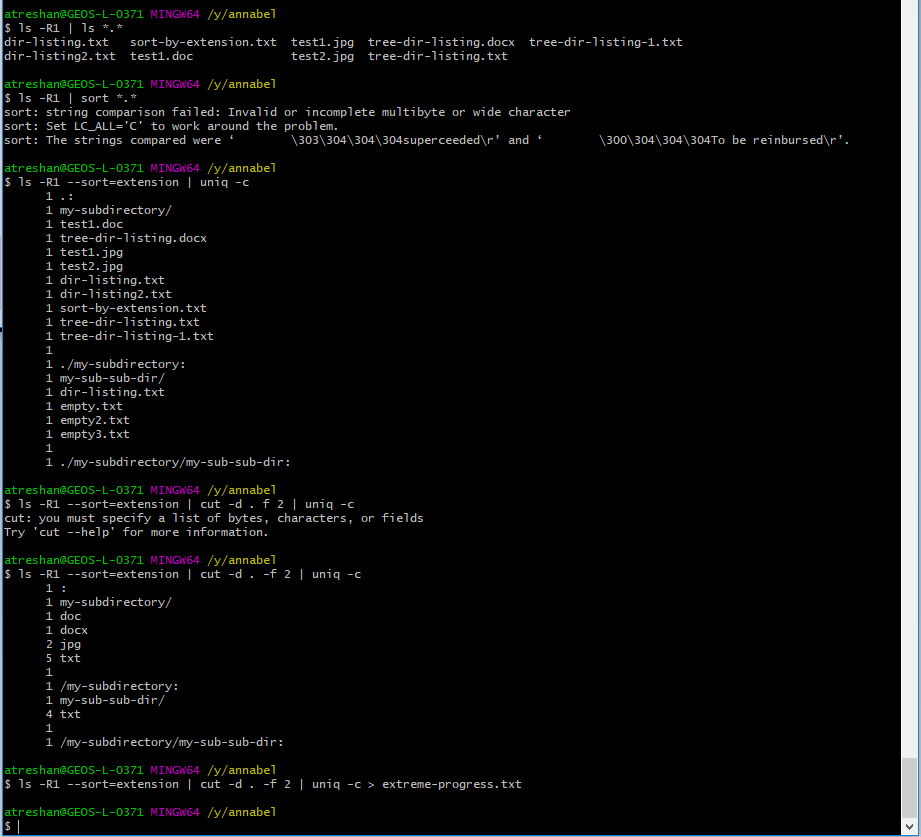
Filtering and aggregating my file and directory listings with the uniq and cut commands – nearly there now!
I separated out the file extensions with another pipe, adding in
cut -d . -f 2, which should isolate the file extensions by separating each line of text into fields before and after the
. (the delimiter) and then only taking the second field on each line where there is a . (I hoped that in this way cut would get rid of the directories too, but it does keep at least some of them (maybe the lines that start with a . for the current directory?)
Then I piped the output from cut to uniq -c, which aggregates adjacent lines that match and counts them.
This was looking good enough for me to save the output to a text file called extreme-progress.txt.
The next step was to add in another sorting command in between cut and uniq:
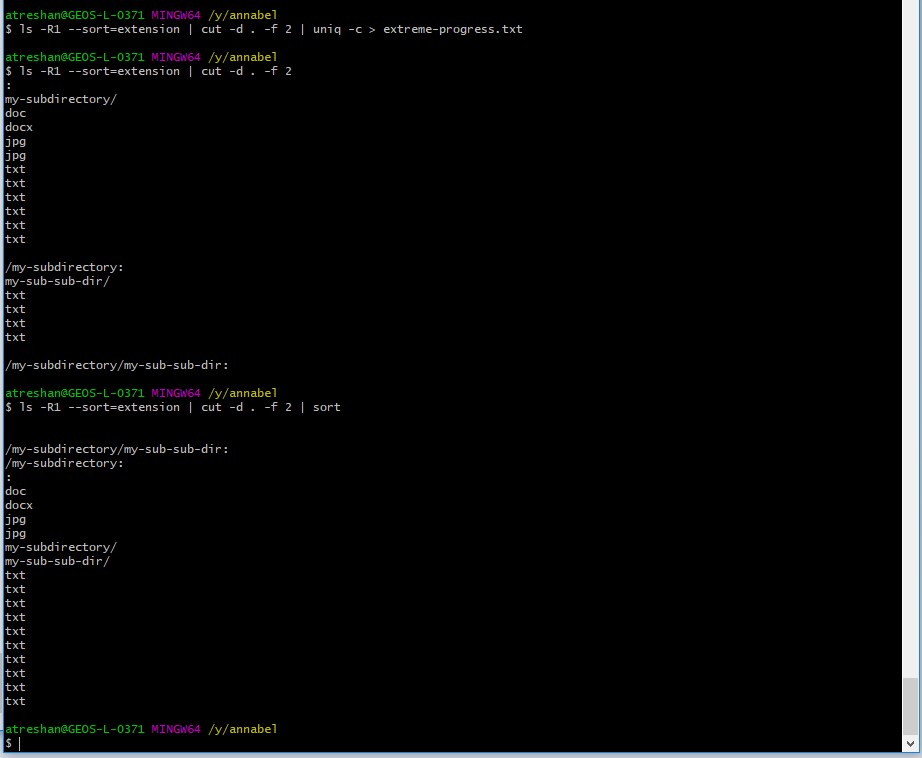
Sorting by file extension, cutting out the rest of the text and then sorting again
The sorting order doesn’t matter: the point is to group the same extensions together so that
uniq could aggregate each group into one line and count them.
So that’s what I did next:
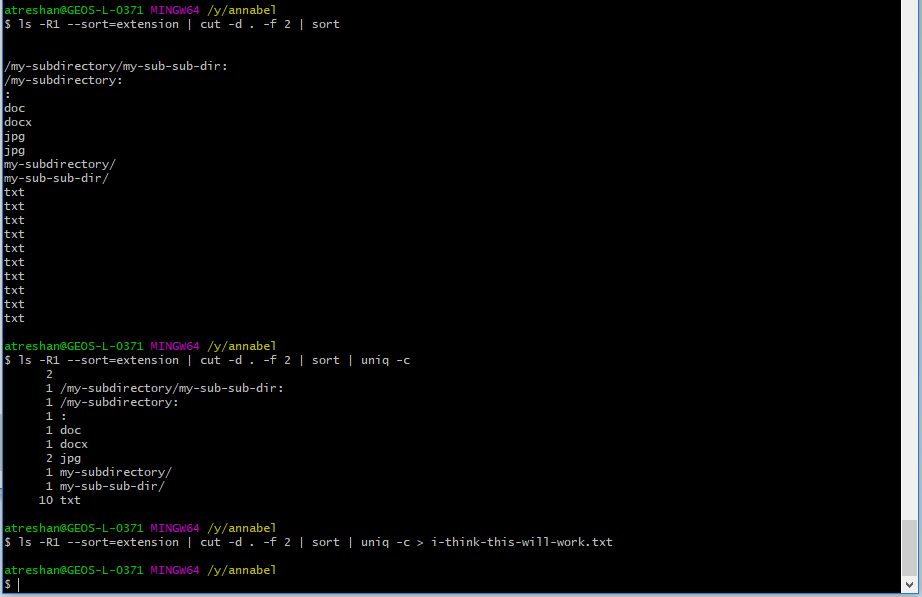
It works! An aggregated list of file types by extension, with a count for each type
I checked the output in the terminal and saved it to a text file called i-think-this-will-work.txt
This is the point where I did my victory dance, and set off the real program.
Did I mention it was taking a while?
While it was running, I opened the output text file in Notepad and discovered Windows had lost the line breaks that appeared fine in the Unix terminal…

Windows Notepad: Where did the line breaks go..?
So I stopped my mammoth program with a CTRL-C, and looked into fixing my output formatting.
As Google is still my friend, I found a couple of helpful answers.
First, I found a post on The Unix and Linux Forums that suggested the line breaks might still be there if I opened the file in Word or WordPad, and they were right. Another answer on the same forum explained that Windows uses \r\n as a line break whereas Unix uses \n, and gave an example of how to filter text using sed 's/$/\r/'
Adding this filter into my Unix command allowed me to format my output correctly:
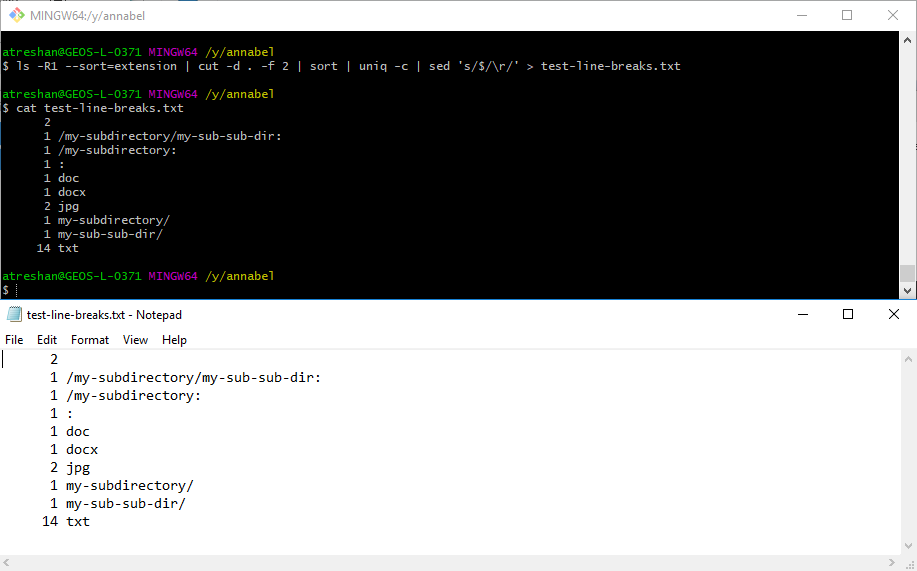
Text output is now formatted correctly, with line breaks
The last piece of the puzzle?
Not quite!
I was becoming very curious to know how long this program was really taking! I looked into timing with Unix commands, and decided I’d like to time my program’s execution time and also get a listing of the time and date it finished, for fame, posterity, etc purposes.
So did this end up being my final Unix command?
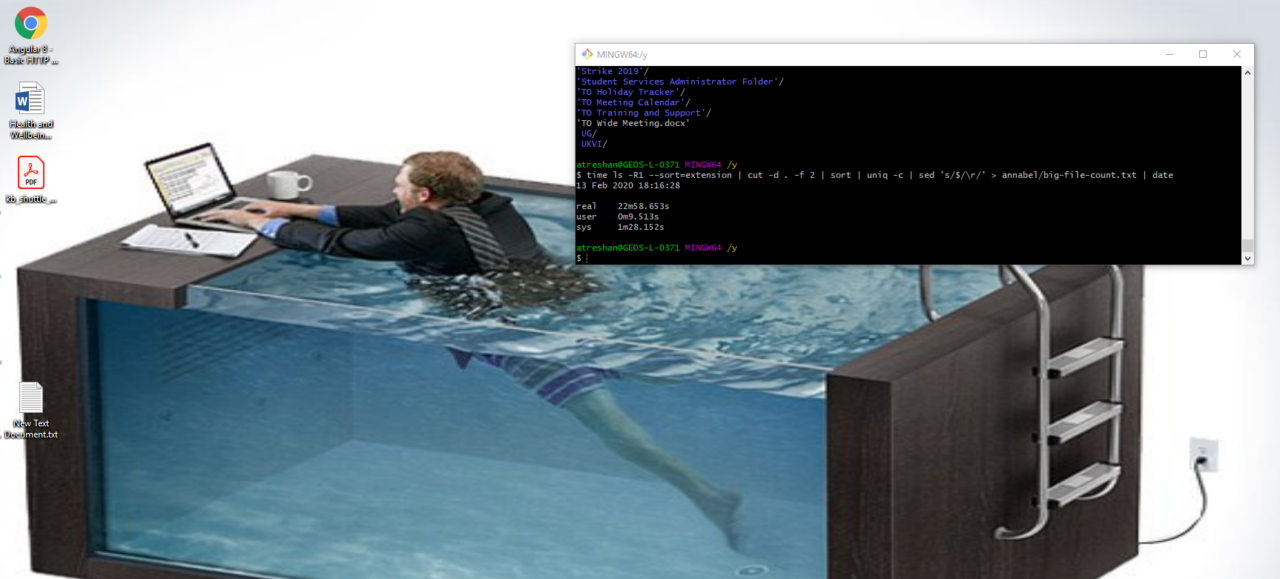
$ time ls -R1 --sort=extension | cut -d . -f 2 | sort | uniq -c | sed 's/$/\r/' > annabel/big-file-count.txt | date
Fingers crossed!
Waiting some more…
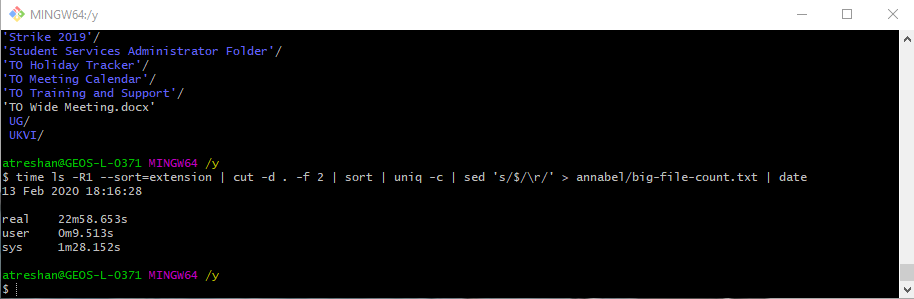
22 minutes later, it finished… something…
So how was the output?
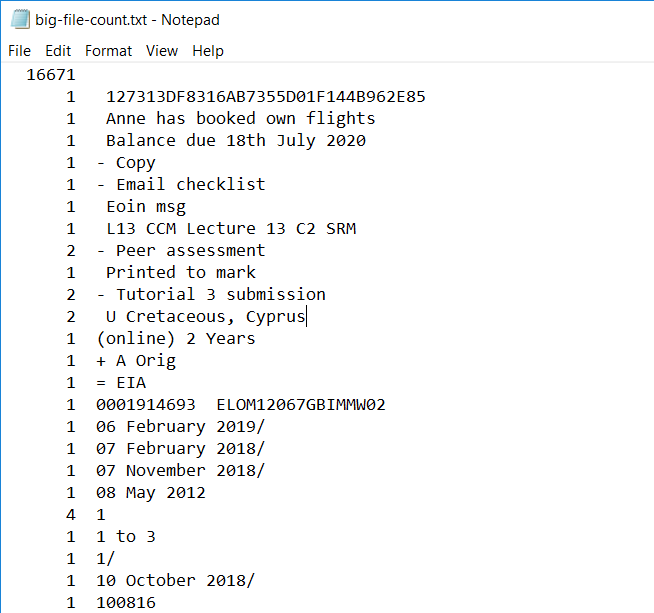
WTF?
Eh, bit weird.
I could see this was going to take some more text processing. Luckily, in a moment of optimism I tried out
cat big-file-count.txt | sort and found it helped a lot, as it sorts by the number at the beginning of each line of text, which is the file count! And a reversed sort to a new output file worked even better:
$ cat working/big-file-count.txt | sort -r > data/sorted-count.txt
Here’s the beginning of the sorted output:
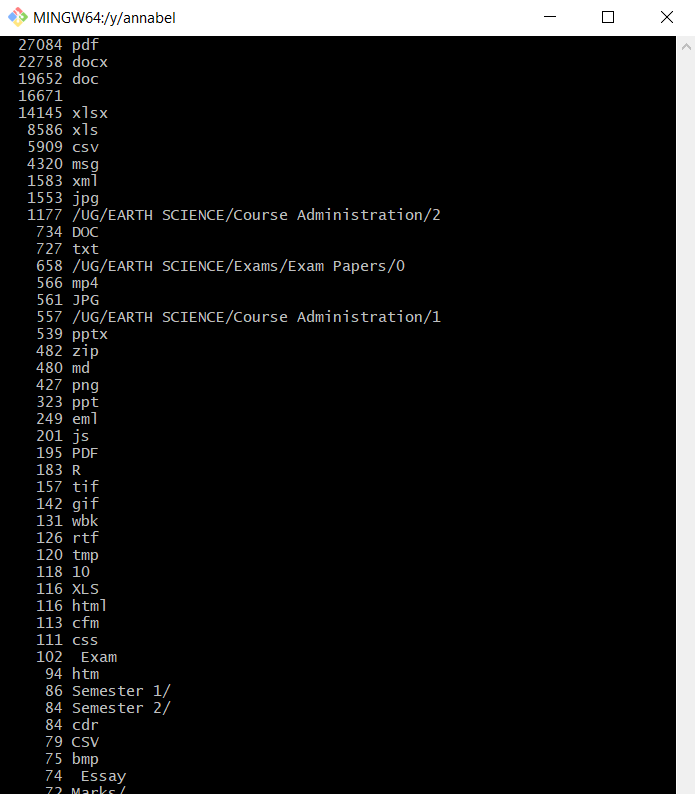
File type listing, sorted by file count
There are some oddities in there (Essays?), but in general, I’ve mostly got some realistic looking counts of file types at the top and listings of directories at the bottom. I’ll have to go into the actual directories to figure out what’s going on with some of these listings, but at this point I think that’s a job for tomorrow, along with some interesting text processing by shell scripting.
Tomorrow is another day!

Yes, let’s be dramatic about this
$ ls -R1 | cut -d . -f 2 | sort | uniq -c | sort -nr > annabel/data/sorted-count-2.txt The command crashed with errors when I tried to run it on the whole data set:
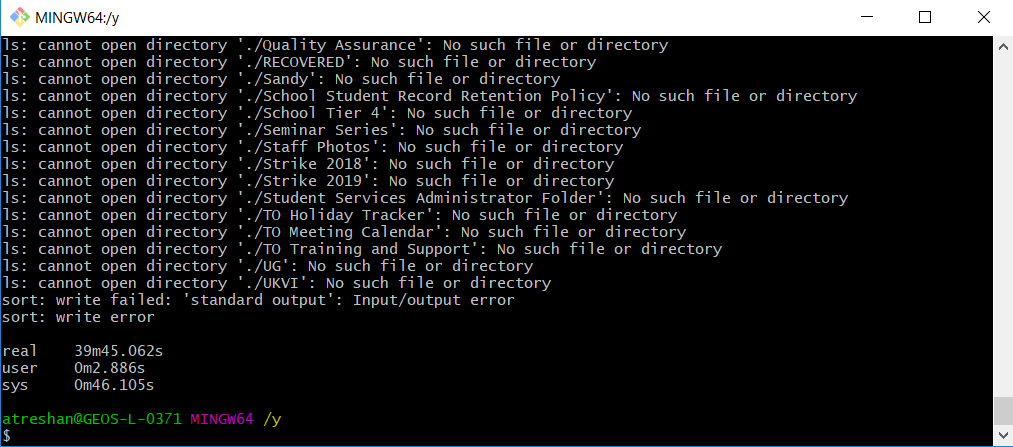
Error! Error! Wibble!
I tried again, running the original command and the new version in my test directory without --sort=extension to compare the output and the running times and it worked as I expected:
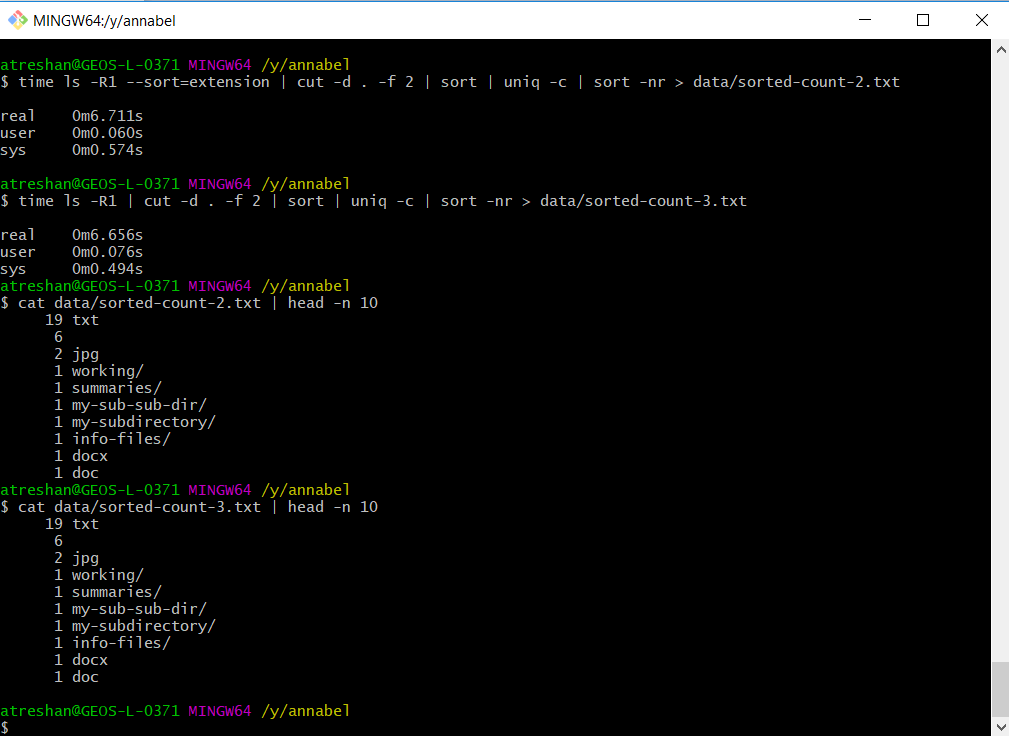
Same output, shorter running time
The output was the same and the running time without the extra sort was slightly faster.
Unfortunately, once I started tracking the cause of the errors through the file system, I realised that my cut command wasn’t quite getting it right (not going to do the pun, no). I’ve found the cause of one of the odd errors in the count output file as an example: someone has been giving some of the subdirectories inside the PGT directory names like 2005.2006, and this is why: 49 /PGT/MSc GIS cluster/Persons Name GIS archive/2005
appears in the count file, for example, because I used the . to separate the file paths into columns to get the suffixes.
I will need to extract the file extensions another way to improve on the accuracy of the counting, maybe counting backwards from the end of each line using regular expressions.
In my next post on this, I’ll be tracking down the errors, and then having a go at sorting and counting my files using shell scripts and regular expressions.
What happened next?
Find out here: Unix file counting challenge, Part 2: Tracking down the errors
*Got the directory path now, but I think things have moved on since then.
Links
- What is the exact meaning of Git Bash?
- What is Git Bash for Windows anyway?
- Software Carpentry: Using –help, and the options for the ls (list files) command
- Super User: how do I add the ‘tree’ command to git-bash on Windows?
- Unix commands: tree
- Wikipedia: tree (command)
- Microsoft Docs: tree (Windows terminal command line)
- Cmder: Portable console emulator for Windows
- Windows PowerShell
- How to make ls sort by file extension and then name?
- cut – Unix, Linux Command – Tutorials Point
- [Solved] line breaks missing when emailed from unix to win – The Unix and Linux Forums
- How to Display the Date and Time in the Linux Terminal (and Use It In Bash Scripts)
- Track the time a command takes in UNIX/LINUX?
- How to Display the Date and Time Using Linux Command Line
(Image: Scarlett O’Hara: “After all, Tomorrow is another day!”, Gone With the Wind, via MagicalQuote.com)
(Main image: My desktop, when my marathon Unix command finished executing. The photo in my desktop background depicts the April Fools' Day Swim Desk from ThinkGeek.com)


Leave a Reply