Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
I’ve got a project coming up that will involve some major tidying up of a big shared network drive that has been used in different ways by many different people over many years.
One of the first steps is to find out what kind of files are on the network drive, how many of them there are, whether they’re still being used, and where they are stored in the directory structure.
I use a Windows laptop at work, which has a VPN connection to the University’s network and a MacBook at home, which doesn’t (yet). I’ve also been attending a training course in Unix skills, which seem like they could usefully be applied to this problem, and I’ve been really enjoying finding out more about this.
I have been given an enormous number of files of different types, in many jumbled up directories and subdirectories on a network drive, to count. That ought to be a job for the Unix commands and shell scripting I’ve been learning at Software Carpentry over the last couple of weeks, right?
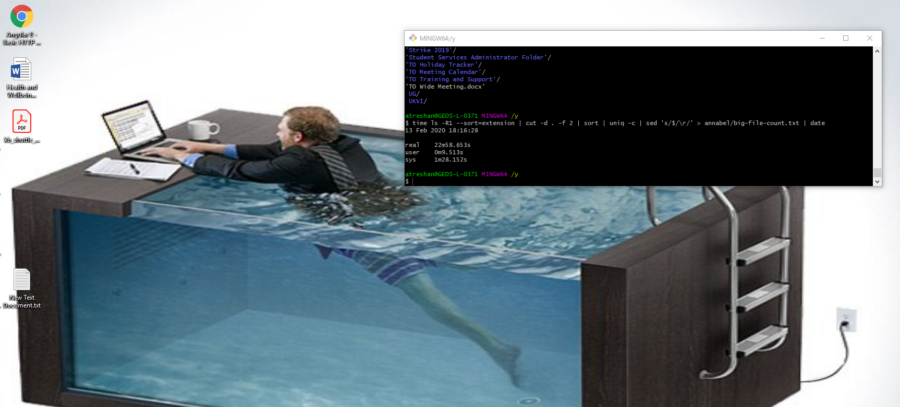
My initial thoughts were that this could be done with either the command line, probably involving ls, sort, regular expressions with uniq and counting options or a shell script looping through a file listing with some combination of those.
Time to fire up Git Bash, my trusty Unix terminal for Windows…