
A Linguistic Toolkit for Scottish Gaelic
Dr Loïc Boizou (Vytautas Magnus University) and Dr William Lamb (University of Edinburgh) have collaborated on a new bilingual website that provides a linguistic toolkit for Scottish Gaelic. Called Mion-sgrùdaiche Cànanachais na Gàidhlig or the Gaelic Linguistic Analyser, the site provides users with tools for analysing the words and structures of Gaelic sentences. The information provided by these tools can be used for additional natural language processing (NLP) tasks, or just for exploring the language further. This new website presents the tools together for the first time and provides users with two ways of interacting with them: a graphical interface and a command line method.
‘Like black magic’
The website’s development goes back to the late 1990s, when Lamb was working on his PhD. In order to investigate grammatical variation in Gaelic, Lamb constructed the first linguistically annotated corpus of Scottish Gaelic, spending over a year annotating 80,000 words of Gaelic by hand. He says, ‘It was a slog. Typing in 100,000 tags by hand… just don’t do it. I developed a nasty case of repetitive strain injury and vowed never to do this sort of thing by hand again.’ After returning to the University of Edinburgh in 2010, after 10 years at Lews Castle College Benbecula, he revisited his corpus to develop an automatic part-of-speech tagger and make the corpus available to other researchers. Today, the corpus is known as the ‘Annotated Reference Corpus of Scottish Gaelic’ or ARCOSG and is available freely online.
The corpus forms the backbone of two of the tools on the new website: the part-of-speech tagger and the syntactic parser. They were created using machine learning techniques, modelling the kinds of patterns that you find in Gaelic speech and writing. Lamb said, ‘what you can do today even with a relatively small amount of text is tremendously exciting. When we looked at developing a POS tagger in the 90s, we would have had to program each type of pattern manually to enable the computer to recognise it properly. Now, you can just run the corpus through a set of algorithms and the computer works the patterns out itself. It’s like black magic’.

Dr Will Lamb
The lemmatiser was developed in a different way, using a form of the popular online dictionary, Am Faclair Beag. Lamb explains: ‘When we were working on the part-of-speech tagger in 2013 or 14, Sammy Danso and I got in touch with Michael Bauer and Will Robertson, who put together the fantastic Am Faclair Beag. We were going to try to leverage some of the information in the dictionary, and they generously offered their data for this purpose. While that plan didn’t materialise, I was able to create a root finder or lemmatiser with it years later, which we used to help create the first neural network for Gaelic. The lemmatiser sat in the virtual cupboard for a while, until I was contacted by Loïc in 2017. Loïc wanted to create a proper Gaelic lemmatiser, and I was onboard.’

Dr Loïc Boizou
Dr Loïc Boizou is a Swiss French NLP specialist working in Lithuania (Vytautas Magnus University) who is interested in computational tools for under-resourced languages. He received his PhD in Natural Language Processing at Inalco (Institute of Eastern Languages and Civilisations) in Paris. About the project, he said, ‘I am very supportive of cultural diversity and Gaelic is one of the few endangered languages that provides serious opportunities for distance learning, thanks to Sabhal Mòr Ostaig. I really enjoyed learning the language and I decided to use my NLP skills to give it a bit of a boost. I learned about Will’s corpus and found we could cooperate very nicely.’
Roots, Trees and Tags
The website provides different ways of exploring Gaelic text. Lemmatisation is simplest of the tools and involves retrieving a word’s root form. If you were to input a sentence like tha na coin mhòra ann (‘the big dogs are here’), the website would return ‘bi’, ‘cù’ and ‘mòr’ as the lemmas (root forms) of bha, coin and mhòra. The website also offers part-of-speech tagging, which provides grammatical information about words in a sentence. Using the previous example, the website’s algorithms would assign ‘POS tags’ to each word, as in the third tab-separated value in each line below (glossed in inverted commas):
tha bi V-p 'Verb: present tense' na na Tdpm 'Article: pl masc def' coin cù Ncpmn 'Noun: common pl masc nom' mhòra mòr Aq-pmn 'Attributive adjective: plur masc nom' ann e Pr3sm 'Prep pronoun: 3rd person sing masc'
The grammatical information in this example is quite precise, but such precision comes at a cost: the default tagger is subject to error about 9% of the time. For users who want simpler POS tags and more accurate tagging, the website also offers a ‘simplified tagset’ option, which provides 95% accuracy. The same sentence above, submitted with this option would provide the following:
tha bi Vp 'Verb: present tense' na na Td 'Article: definite' coin cù Nc 'Noun: common' mhòra mòr Aq 'Adjective: attributive' ann e Pr 'Prepositional pronoun'
In addition to lemmatisation and POS-tagging, the site also offers syntactic parsing, using a syntactically annotated corpus developed by Dr Colin Batchelor (Royal Society of Chemistry). Again, using the same sentence, the website returns the following if parsing is selected:
1 tha bi V-p 0 root 2 na na Tdpm 3 det 3 coin cù Ncpmn 1 nsubj 4 mhòra mòr Aq-pmn 3 amod 5 ann e Pr3sm 1 xcomp:pred
The number in the 4th column indicates which element in the sentence the word is governed by. In the case of tha, the number is 0, because it is the syntactic root. Both na and mhòra, on the other hand, are parts of a noun phrase governed by element 3, coin. This is a numerical way of displaying the kind of information that is often conveyed in a syntactic tree, such as in the example below. The information in column 5 indicates the function of the element in the sentence. For example, the function of coin is nsubj or ‘nominal subject’. More information on Dr Batchelor’s parser can be found here.
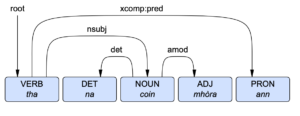
Syntactic tree for tha na coin mhòra ann
Next Steps
When asked what the next steps are for the language, Lamb explains that it’s an exciting time: ‘Well, this is really just an interim step and there is a lot to do. For a start, we hope to improve the accuracy of the tools gradually and perhaps augment them. Gaelic is, in some ways, in a very fortunate position when it comes to language technology. Advanced tools are starting to come online — like Google Translate, a handwriting recogniser and speech synthesiser — and we can exploit great resources like DASG, ARCOSG and recordings from the School of Scottish Studies Archives to push into territory that would have seemed like science fiction a few years ago.’
The dream is artificial general intelligence. ‘Elon Musk is famous for saying that one day, he’d like to die on Mars – just not on impact. Before I kick the proverbial bucket, I’d like to chat with a computer that has better Gaelic than I do’.


Leave a Reply