Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
Last month (8-12 November), the Scottish Bowel Cancer Intelligence UK team at Edinburgh Health Economics attended the National Cancer Research Institute (NCRI) Festival: Making cancer research better together, with a poster on their recent work “Early colorectal cancer treatment and outcomes in Scotland: real world evidence from national linked administrative data”.
You can see more plain language summaries for the wider Bowel Cancer Intelligence programme on the BCIUK website.
Background: Whenever a patient interacts with the healthcare system, data is routinely collected, this is called “Administrative Healthcare Data”. This data can be used to provide information on screening, surveillance, existing health conditions, diagnosis, treatments and patient outcomes. It can also be used to provide information on the real-world cost of healthcare. The data is held in individual datasets, which can be linked together to provide more information than just one dataset alone.
In the UK, Administrative Healthcare Datasets are generally held separately within each nation. In Scotland, cancer data is collected by the cancer registry. This dataset contains a lot of information such as the date of diagnosis and the type and stage of cancer, but it does not include detailed information on the treatment that was delivered. In order to be able to see a full picture of what the cancer services currently look like, the cancer registry data needs to be linked to other Administrative Healthcare Datasets.
The aim of this project is to create a linked dataset to allow mapping of the bowel cancer landscape in Scotland to identify differences in the treatment offered to patients and the outcomes associated with the different treatment approaches. An additional aim is to calculate the healthcare resource needed for bowel cancer diagnosis and treatment on a national scale, and the cost of providing this.
This manuscript documents the process of creating a specific and complete bowel cancer dataset for research in Scotland.
What we did: There were four main stages in accessing and linking datasets on a national level.
Stage 1 – The first stage in accessing the data was to define the study requirements to apply to the Public Benefit and Privacy Panel (PBPP) for Health and Social Care in Scotland. The role of the PBPP is to weigh up the public benefits of granting access to healthcare data against the risks that the sharing of the data poses to an individual’s privacy.
Stage 2 – The second stage was to acquire the datasets to transfer them into the National Safe Haven (NSH). The NSH is a secure platform where the data can be used for research and analysis.
Stage 3 – All datasets that were to be released to the research team to analyse were checked by the electronic Data Research and Innovation Service (eDRIS) to make sure they matched the approved specification. The linkage of the datasets was performed by eDRIS once all the pre-checks had been completed.
Stage 4 – After the data linkages had been performed, the datasets were transferred to the National Safe Haven where researchers, with the correct approvals, could access the data. In this setting, all patient information like names and addresses were removed.
Conclusion: Linked Administrative Healthcare Datasets have huge potential to aid understanding of how patients interact with healthcare services and provide a detailed picture of the care they receive. This project demonstrates that the creation of a national linked administrative dataset is possible, by using bowel cancer data in Scotland as an example. It is however only possible through substantial effort and collaboration between researchers and the central team coordinating the data transfers and linkages.
The linked datasets have huge potential public and patient benefit by enabling researchers to analyse real world cancer data to improve outcomes for patients as well as the delivery of cancer services.
Several forces are contributing to an increase in the number of people living with and surviving colorectal cancer (CRC). However, due to the lack of available data, little is known about the implications of these forces. In recent years, the use of administrative data to inform research has been increasing. Administrative data is collected routinely ‘by government departments and other organisations for the purposes of registration, transaction and record keeping, usually during the delivery of a service’ (Woollard, 2014). Examples include hospital admissions data, education records and tax records.
The aim of one of our recent pieces of work was to investigate the potential contribution that this type of data could have on the health economic research of CRC. To achieve this aim, we conducted a systematic review of the health economic CRC literature published in the United Kingdom and Europe within the last decade (2009– 2019).
Our specific objectives were:
To summarise the existing health economic research of CRC in the UK and Europe;
To identify whether and what types of administrative data were used within this research;
To explore the benefits and limitations of using administrative data in this research;
To discuss the ways in which administrative data, using Scotland as an exemplar, could contribute to this research in the future
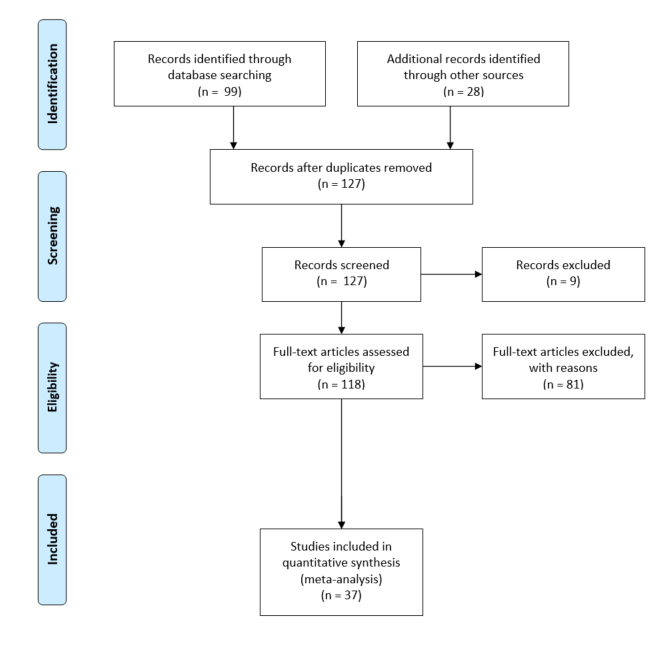
The literature search identified thirty- seven relevant studies, which we divided into economic evaluations, cost of illness studies and cost consequence analyses.
Findings:
We found that the use of administrative data, including cancer registry, screening and hospital records, within the health economic research of CRC is commonplace. However, we found that this data often come from regional databases, which reduces the generalisability of results.
Further, we found that administrative data appear less able to contribute towards understanding the wider and indirect costs associated with the disease, particularly with respect to social care and indirect costs such as unpaid care.
We also found that very few papers adopted a societal perspective when carrying out their evaluation meaning that often only direct medical care costs were included.
Finally, we found that administrative data were less able to contribute when it comes to measuring patient health related quality of life (HRQoL) and preferences for those health states, which is vital particularly in EEs.
We explore several ways in which various sources of administrative data could enhance future research in this area. If you want to find out more, head on over to the European Journal of Cancer Care website where you can read the article in full.
At the end of April, Peter and Elizabeth, along with lead author Dr Catherine Hanna and patient representative Mr Steve Clark, presented their recent publication at the Power of Population Data Science Webinar Series.
Lucky for you, if you missed the webinar, you can watch it again on the Population Data BC YouTube channel here and see our slides from the event here.
The webinar was very well received with over 111 people signed up to the event and around 70 in attendance on the day. We were thrilled to spread the word about all of the hard work that has gone into creating this dataset, as well as all of the research we have planned so watch this space!
People who are nearing the end of life are high users of hospital services. The absolute cost to providers and its value is uncertain. There is a need to identify which groups of people spend a lot of time in hospital so that care can be modified to better tailor care to patients preferences and to improve the efficiency health services in this context.
Research Summary
Objectives: To describe the pattern, trajectory and drivers of secondary care use and cost by people in Scotland in their last year of life. Methods: Retrospective whole-population secondary care administrative data linkage study of Scottish decedents of 60 years and over between 2012 and 2017 (N=274,048).
Results: Secondary care use was high in the last year of life with a sharp rise in inpatient admissions in the last three months. The mean cost was 10,000 pound. Cause of death was associated with differing patterns of healthcare use: dying of cancer was preceded by the greatest number of hospital admissions and dementia the least. Greater age was associated with lower admission rates and cost. There was higher resource use in the urban areas. No difference was observed by deprivation.
Conclusions:
Hospitalisation near the end of life was least frequent for older people and those living rurally, although length of stay for both groups, when they were admitted, was longer.
Research is required to understand if variation in hospitalisation is due to variation in the quantity or quality of end of life care available, varying community support, patient preferences or an inevitable consequence of disease-specific needs.
In this post, written for the Early Career Researchers Using Scottish Administrative Data (eCRUSADers) blog, Catriona Keerie, Senior Statistician within Edinburgh Clinical Trials Unit (ECTU) talks about her work within ECTU and her involvement on a rare Scottish trial that used administrative health data. She provides some great diagrams to help along the way, which I can tell you are essential if you want to understand the complicated structure of the data! Catriona also highlights some of the key challenges the team faced in terms of data access and use and offers her reflections on what they learned from the project which could help other trials like this one in the future.
Can you tell us a little about your role in ECTU?
My role involves a variety of tasks – however, primarily my role is the statistical reporting of trials run from within ECTU. I typically have up to eight active trials throughout the year. My role varies on these – I am Trial Statistician for approximately half of them, and the ‘reporting’ statistician for the other half. When I have my reporting statistician hat on, I’m responsible for the statistical programming and generating the analysis and results.
How trials have you worked on that have involved using administrative data?
Since I joined ECTU in 2014, I have worked on three trials using administrative data. Two of them used solely routine healthcare data and the third one is running currently, based on a blend of routine data plus data captured within the trial.
Is the use of administrative data in trials becoming more common over time?
The use of administrative data in the trials setting is definitely becoming more common since clinical trials are known to be expensive and time-consuming. The use of administrative healthcare data is viewed as a more efficient means of understanding the health of the population using readily available data. However, there is a trade-off in terms of the quality of the data being captured.
It’s a relatively recent study design that’s increasingly being used to evaluate service delivery type interventions. The design involves crossover of clusters (usually hospitals or other healthcare settings) from control (standard care) to an alternative intervention until all the clusters are exposed to the intervention. This differs to traditional parallel studies where only half of the clusters will receive the intervention and the other half will receive the control. This diagram helps to demonstrate the difference in designs:
The population of interest were patients presenting in hospital with heart attack symptoms. The trial sought to test a new high-sensitivity cardiac troponin assay against the standard care contemporary assay. Specifically, to test if the new assay could detect heart attacks earlier and with a more accurate diagnosis.
How were patients enrolled into the trial and how does this differ from a standard trial?
Step wedge trials usually randomise at a cluster (hospital) level, rather than randomising patients individually, so this was the main difference to a standard trial. So patients were enrolled rather than randomised into the trial. Standard trials require patient consent before randomisation, but in this context, individual patient consent was not needed due to the randomisation being performed at hospital level. Appropriate approvals for consent were sought through the hospitals.
If patients presenting with heart attack symptoms at any of the hospitals were eligible for the trial (based on our pre-specified inclusion/exclusion criteria), then we had permission (at hospital level) to include them in the study and use their securely anonymised data.
How many patients were enrolled into the trial?
Approximately 48,000 patients were enrolled from 10 hospital sites in NHS Lothian (3 sites) and NHS Greater Glasgow and Clyde (7 sites), over a period of just under three years.
Which administrative data sets were used?
We used a total of 12 distinct data sources which were a combination of general administrative datasets and datasets more specific to our area of research from locally held electronic health care records. Prescribing data was obtained from the Prescribing Information System, also ECG data, plus general patient demographics. Trial-specific outcome data was obtained from the Scottish Morbidity Record (SMR01) and also from the register of deaths (National Records of Scotland). All data were captured separately for each Health Board – there is currently no amalgamated data source which holds all data. Health Boards are the owners of their own data.
The main linking mechanism for these 12 data sources was the patient CHI (Community Health Index) number. To ensure patient anonymity, CHI numbers were securely encrypted prior to use.
How did you get approval for these data sets? How long did this approvals process take?
Approvals were required at a number of levels. We required ethics approval, approval to use patient data without consent and Health and Social Care approval (through the Privacy Approvals Committee, predecessor to the Public Benefit Privacy Panel). There were also health board specific approvals required for local data to be released. In addition, we required data supplier approval. Finally, approval was needed for the data to be hosted on the Safe Haven platform.
This process was long! This was ongoing throughout the duration of the trial. Although the data was being captured automatically via routine records, the final dataset wasn’t confirmed until relatively late on in the process due to complexities of mapping locally held healthcare records. One of the advantages of the national datasets is that they are the same across all health boards.
Where were the data sets stored?
Datasets from NHS Lothian and NHS GG&C were supplied separately in their own Safe Havens. The combined dataset was hosted on the NHS Lothian Safe haven space on the National Safe Haven analysis platform .
How did the linkage of the data sets happen?
The data sources from both health boards were combined and hosted on the National Safe Haven analysis platform. This wasn’t a straightforward process. Although we’d anticipated capturing exactly the same patient data across both health boards, the reality was quite different.
Data were captured in different formats with different variable names and different definitions. So there was an unexpected element of data cleaning required before the data could effectively be merged into one large analysis dataset.
The final linkage was done using the securely encrypted CHI number for each patient.
What do you see as the major benefits of using administrative data in this setting?
Use of administrative data in this context is a more efficient process – less resource spent on the administrative aspects of trial enrolment e.g. capturing demographic details such as age, sex, postcode or medical history.
Using administrative data also gave us the opportunity to research a large representative patient population in comparison to the setting of an RCT where a strict pre-specified population, not necessarily representative of the target population, are studied.
Overall, what were the major challenges of the study?
From the data side of things, ensuring the correct data was extracted was difficult. The diagram above is very over-simplified view of what happened! The reality of picking up the required variables from two separate health boards which capture data very differently was difficult.
Another challenging aspect was ensuring that a patient wasn’t enrolled more than once in the study. Patients can present in any hospital with heart attack symptoms more than once, so we needed to ensure they weren’t included in the study each time they came to hospital. This required a de-duplication algorithm using encrypted and de-identified patient data.
However, I think the biggest challenge was for those in the team tasked with obtaining the correct approvals. It was underestimated how complex this would be. While approval for the national datasets was straightforward and the eDRIS team were very helpful, processes for locally held data at the time of trial set up were not established. Legislation around patient data confidentiality was continually changing, so we were faced with keeping abreast of new legislation as time progressed. The safe haven networks are now more established and hopefully, the processes are more straight forward.
Is there anything you would do differently next time?
I think the data validation aspect of the trial is crucial. Ideally we would have had more time spent on this in order to ensure the data was as correct as possible. Involving the clinical team much sooner in this process would have helped – they have a really important role to play in terms of ensuring the data picked up makes sense from a clinical perspective.
For High-STEACS, the access to the data was highly restricted and did not include the clinical team. Many of the data discrepancies were only picked up at the final review stage once data and results had been released out of the Safe Haven area.
Working within the Safe Haven environment creates time lags on both sides of the process – data being imported into the Safe Haven and also results exported out at the end take time. We hadn’t considered this time lag when working to tight timelines.
Do you know if anyone is using the learning from this trial for future trials of this kind?
The High-STEACS trial was directly followed by the HiSTORIC trial, addressing similar research questions and using many of the same data sources. So we have been through the loop again which has made for a more streamlined process. Other trials within ECTU are also making use of the learnings from High-STEACS, particularly from the governance and approvals side of things.
Summary
Thanks for sharing this with us Catriona! It is great to see that administrative data are being utilised alongside clinical trials in Scotland. It is also interesting to hear that despite being part of a trials unit like ECTU, the High-STEACS team still faced many of the same challenges that researchers and eCRUSADers have experienced when using administrative data for research. In particular, we can relate to the issues of permissions, timing and working within the Safe Haven environment. Overall, it seems that the timing issues were due to the use of the locally held data rather than using the national data.
Last week, Elizabeth was invited down to St Andrews House to present her PhD work to the Health and Social Care Analysis team. Specifically, this presentation covered her PhD research on the provision of long term care to older adults in Scotland, with a particular focus on the usefulness of Scotland’s administrative data (data that are collected routinely as part of service provision) in answering her PhD questions. In this post, Elizabeth gives you a quick overview of her presentation.
You might be wondering why there is a photograph of me (top right), my mum (top left) and my grandmother (centre) at the top of this post. As well as showing the increasingly familiar image of a multi-generational family (my mum might prefer if there was another generation in there but I have told her she is going to have to wait a few years for that!), I like to use this photograph to tell the story of my PhD. So here goes….
Paper 1: Variations in domiciliary free personal care across Scottish local authorities
Data used: Social Care Survey (SCS) and other publically available, area level data sets
This paper looks at things from my Grandmother’s perspective as an older person who is receiving personal care services. In particular, it explores variation in the provision of Free Personal Care (FPC) across Scottish local authorities, in order to establish whether or not FPC provision matches the need of the population.
Paper 2: Utilisation of personal care services in Scotland: the influence of unpaid carers
Data used: Social Care Survey (SCS)
This paper looks at things from my mum’s perspective as an unpaid carer who is providing care to my Grandmother. In particular, this paper uses the SCS to try and understand how unpaid carers can influence older people’s use of personal care services.
Paper 3: The cost of unpaid care: a standard of living approach Data used: Family Resource Survey (FRS)
My final paper looks at this from my perspective, as an onlooker to the caring situation going on between my mum and my Grandmother. This perspective asks, “who cares for the carer?”. The aim of this paper was to understand whether or not unpaid carers experience a reduction in their standard of living due to caring, if so then how much would they need to be compensated by in order for them to reach the same standard of living as a non-carer, and finally how would that level of compensation compare to the current Carers Allowance.
If you want to know what I actually did and found in each of these three papers, you can have a look at my thesis here.
My PhD and Administrative Data
I had planned to use a national, linked administrative health and social care data set for my PhD. In fact, I applied for this in April 2016. Unfortunately, I didn’t get access to it until April 2018 and by this point I had had to come up with a plan B and was running out of time/funding to be able to get to grips with the linked data.
As a result, I made do with publically available, geographical level data, survey data and administrative social care data.
Did the administrative data help? Some reflections…
Well yes, of course they did. I was able to do some pretty cool work in my PhD using the SCS and this wouldn’t have been possible without it. However, the PhD really taught me that the administrative data struggle is real! A few things I highlighted in the presentation to the Scottish Government were:
Approvals process and linkage timing. Two years is simply too long in the lifetime of a PhD and I did not foresee that it would take this long.
Administrative data aren’t designed for research- they typically lack important controls that we really want/need in econometric analysis. But if we want to answer policy relevant questions with administrative data, surely they should be designed with this in mind? See this recent blog post I did with my colleague from Napier for the Office of Statistical Regulation.
There were lots of differences between local authorities in terms of data recording, missing information etc, which can cast doubt on the conclusions (of course I have carried out as many sensitivity and robustness checks to ensure this isn’t the case, but there is still doubt).
There isn’t any information about the unpaid carers in the SCS. Again, this is important information that is lacking from the administrative data.
Sadly, I’m still enduring this administrative data struggle in my role here in Edinburgh Health Economics. In an attempt to do something about this, I have spent some time developing a new platform called Early Career Researchers Using Scottish Administrative Data (eCRUSADers). I’m hoping that this will reduce the struggle for any researchers who are new to the administrative data scene. You can find out more about eCRUSADers (or join us?!) on the website here.
View of Calton Hill from the conference room at St Andrews House.











 Paper 2: Utilisation of personal care services in Scotland: the influence of unpaid carers
Paper 2: Utilisation of personal care services in Scotland: the influence of unpaid carers
