
By Lucy Evans
In our last blog post, we outlined some of the data preparation that is necessary to train the acoustic model for our Scottish Gaelic speech recognition system. This includes normalization and alignment. Normalization is where speech transcriptions are stripped of punctuation, casing, and any unspoken text. Alignment is where each word in a transcription is stamped with a start and end time to show where it occurs in an audio recording.
After these steps, speech data can be used to train an acoustic model. Once combined with our lexicon and language model (as described in our last blog post), this forms the full speech recognition system. In this blog post, we explain the function of the acoustic model and outline two common forms. We also report on our most recent Gaelic speech recognition results.
The Acoustic Model
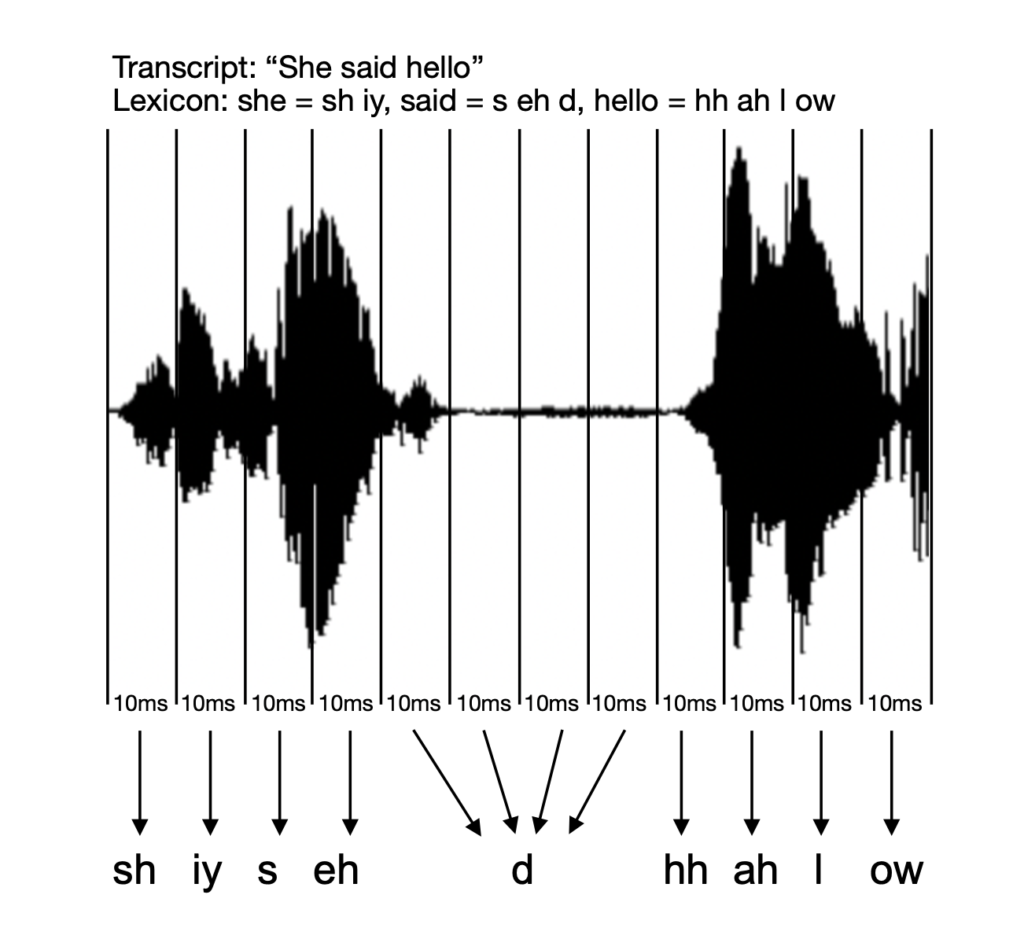
The acoustic model is the component of a speech recogniser that recognises short speech sounds. Given an audio input where a speaker says, “She said hello”, for example, the acoustic model will try to predict which phonemes make up that utterance:
| Audio Input | Acoustic Model Output |
| Speaker says “She said hello” | sh iy s eh d hh ah l ow |
The acoustic model is able to recognise speech sounds by relying on its component phoneme models. Each phoneme model provides information about the expected range of acoustic features for one particular phoneme in the target language. For example, the ‘sh’ model will capture the typical pitch, energy, or formant structure of the ‘sh’ phoneme. The acoustic model uses the knowledge from these models to recognise the phonemes in an input stream of speech, based on its acoustic features. Combining this prediction with the lexicon, as well as the prediction of the language model, the system can transcribe the input sentence:
| ASR System Component(s) | Output, given a speaker saying: “She said hello” |
| Acoustic Model Prediction | sh iy s eh d hh ah l ow |
| + Lexicon | sh iy = she
s eh d = said hh ah l ow = hello |
| + Language Model Prediction | She said hello |
Training the Acoustic Model
In order to train our acoustic model, we feed it a large quantity of recorded speech in the target language. These are split up into sequences of 10ms ‘chunks’, or frames. Alongside the recordings, we also feed in their corresponding time-aligned transcription:

Aligned Gaelic speech
Using the lexicon, the system maps each word in the transcript to its component phonemes. Then, according to the start and end times of that word, it can estimate which phoneme is being pronounced during each 10ms frame where the word is being spoken. By gathering acoustic information from every frame in which each particular phoneme is pronounced, the set of phoneme models can be generated.
Training procedure for the Acoustic Model
Types of Acoustic Model: Gaussian Mixture Models vs Deep Neural Networks
Early acoustic modelling approaches incorporated the Gaussian Mixture Model (GMM) for building phoneme models. This is a generative type of model, meaning that it recognises the phonemes in a spoken utterance by estimating, for every 10ms frame, how likely each phoneme model is to generate that frame. For each frame, the phoneme label of the model with the highest likelihood is output.
More recent, state-of-the-art approaches use the Deep Neural Network (DNN) model. This is a discriminative model. The model directly classifies each input frame of speech with a predicted phoneme label, based on the discriminatory properties of that frame (such as its pitch or formant structure). The outputs of the two models are therefore the same – a sequence of phoneme labels – but generated in different ways.
The reason that the DNN has overtaken the GMM in speech recognition applications is largely due to its modelling power. DNNs are models with a number of different ‘layers’, and consequently a larger number of parameters. Parameters are variables contained within the model, whose values are estimated from the training data. Put simply, having more parameters enables DNNs to retain much more information about each phoneme than GMMs, and as such, they perform better on speech recognition tasks.
Another key difference between the two types of acoustic model is the training data they require. For GMMs, we can simply input recordings with their time-aligned transcriptions, as we already prepared using Quorate’s English aligner. On the other hand, training the DNN requires that every frame of each recording is classified with its corresponding Gaelic phoneme label. We obtain these labels by training a GMM acoustic model, which, once trained on the Gaelic recordings and time-aligned transcriptions, can be used for forced alignment. During forced alignment, each frame of the speech data is aligned to a ‘gold standard’ phoneme label. This output can then be used to train the DNN model directly.
Speech Recognition Results
Having carried out the training of our GMM and DNN acoustic models, we are now in a position to report our first speech recognition results. We initially trained our models using only the Clilstore data, which amounted to 21 hours of speech training data. Next, we added the Tobar an Dualchais data to our training set, which increased the size of the dataset to 39.9 hours of speech (NB: the texts in this data are transcriptions of traditional narrative from the School of Scottish Studies Archives, made by Tobar an Dualchais staff). Finally, we added data from the School of Scottish Studies Archives via the Automatic Handwriting Recognition Project to train our third, most recent model, on 63.5 hours of speech.
We evaluated our models on a subset of the Clilstore data, which was excluded from the training data. This evaluation set comprises 54 minutes of speech, from 21 different speakers. Each recording was passed through the speech recogniser to produce a predicted transcription. We then measured the system’s performance using Word Error Rate (WER). The WER value is the proportion of words that the speech recogniser transcribes incorrectly for each input recording. The measure can also be inverted to reflect accuracy.
As can be seen from the table below, our results have been encouraging, especially considering that DNN models perform best when trained on much larger quantities (100s of hours) of data. We are particularly pleased to report that our latest model passed below 30% WER (i.e. > 70% accuracy), an initial goal of our Gaelic speech recognition project.
|
Model |
Training Corpus (hours of speech) | Word Error Rate (WER) | Accuracy |
WER Reduction (from previous model) |
| A | Clilstore (21) | 35.8% | 64.2% | – |
| B | Clilstore
+ Tobar an Dualchais (39.9) |
31.0% | 69.0% | 4.8% |
| C | Clilstore
+ Tobar an Dualchais + Handwriting (63.5) |
28.2% | 71.8% | 2.8% |
To showcase our speech recogniser’s current performance, we have put together some demo videos. These are subtitled with the speech recogniser’s predicted transcription for each video. Please note that the subtitles will have imperfections, given that we are using our speech recogniser (with 71.8% accuracy) to generate them. Take a look by clicking this link!

Demo video screenshot
Next Steps…
With just 2 months left of the project, the countdown is on! We plan to spend this time adding a final dataset to the model’s training data, with the hopes of further reducing the WER of our system. After this, we plan to experiment with speech recognition techniques, such as data augmentation, to maximise the performance of the system on the data we have collected thus far. Make sure to look out for further updates coming soon!
Acknowledgements
With thanks to Data-Driven Innovation Initiative for funding this part of the project within their ‘Building Back Better’ open funding call
![]()