
A Study in CMYK – Problem Management applied to printing
With Christmas rapidly approaching, I’m sure many of you will be looking forward to enjoying a whodunit, whether in print, film or game.
I’d already referenced Holmes when introducing Kepner-Tregoe problem analysis and by popular demand have been asked to tell a story.
So settle down and grab a mug – are you’re sitting comfortably? Then I’ll begin…
It was just the beginning of a normal workday, when Mrs Hudson, Head of Operational Services bustled in (well, ’tis also the season of panto…).
She brought news of a problem that had been perplexing the local constabulary of Operational Services for nearly a week, but had got inexplicably worse the day before.
Print jobs had been failing intermittently, but now could not be released at all on a third of the multi-function devices and urgency was building as hand-in time was approaching fast.
First order of business was establishing if this was a national emergency (aka a major incident), however the fact that printing could still be collected on the other MFDs and could be printed on any MFD via EveryonePrint meant that there was no need to bother Mycroft.
Uncharacteristically for Holmes (but characteristically for service management best practice), a crack team was assembled and the evidence began to come in. Much of it seemed to be contradictory, incomplete or inconclusive, but none-the-less the team began to sift through it. The offending MFDs were all under the control of a single authentication server which had gone to ground and was no longer communicating, but the other two servers were continuing, if showing signs of strain. “Yes, Watson, we have tried switching it off and back on again!”
The timeline was established – the server had gone on the lam the day before, but even prior to that printing had proved problematic. Changes were examined for a smoking gun, but none could be found. So, detailed analysis was done on the server – character (configuration), known associates (network traffic) and financial records (logs) were simultaneously examined with a fine-toothed comb – each investigation being directed by the team, but carried out by the appropriate expert. Interpol (the supplier) was alerted, but there were no definitive leads. The press had been alerted, so the public (users) could follow the story if they wished.
All the expenditure of shoe leather finally paid out – the authentication server had been shirking and not doing what the others had been doing! A print spooler had been disabled, for why would an authentication server need a spooler? Indeed the supplier had documented that it wasn’t required, yet the other servers had persisted in spooling as well as authenticating. The team were unconvinced, but it was an easy, safe thing to try. Overwork seemed equally plausible, so another authentication server was also recruited to spread the load.
Relief – cloud print jobs could now be released on all MFDs, but as Holmes observed, this was only one of the problems – the intermittent failures were still present. Still, it made a good news story to bring to the late editions that day.
The next day dawned clear, and the team were reconvened – although the frequency of meeting together had diminished, the new fangled technology of the telegraph (Microsoft Teams) had kept everyone up to date with the various leads. Again several different suspects were presented – some had been minor-league thugs, acting up for years, and these were discounted thoroughly as the MO simply didn’t fit the evidence. Still, they were logged as persons of interest for future investigations.
The focus turned once more to overwork, but this time not on a single server, but the whole system. However the timing didn’t match – the system was failing at times that didn’t match the spikes that appeared periodically (jump scares being the lowest form of horror!). Attention instead turned to the point at which things began going downhill – further admissions were forthcoming when the suspects were re-interviewed, with a particular focus on their whereabouts during this narrower window.
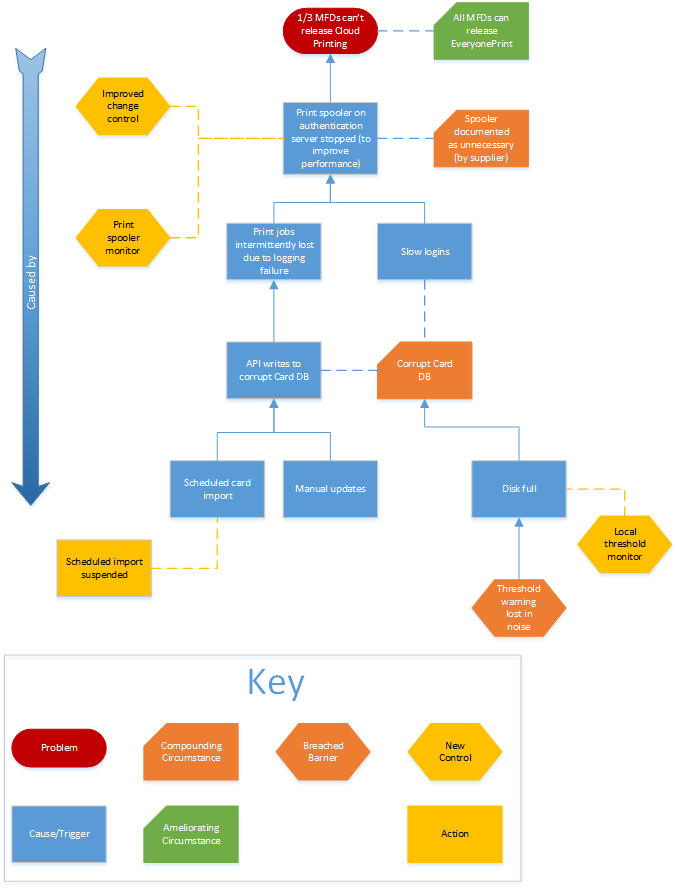
Click through for spoilers!
It turned out that one server had had a skinful, and corruption had resulted – most of the time this wasn’t noticed until certain activities exposed it. The light of a write was found to coincide with the system’s evasive behaviour and this could be reproduced at will. Fortunately uncorrupted innocents are retained for just such an occasion and restoring one of these eliminated the problem completely.
As a final act, the team contrived a scheme to prevent recurrences, including a scheme to preserve server morality, or at least detect any causes of corruption prior to the rot setting in…
Of course, if the end had been known from the beginning, it would be so much easier, but the twists and turns, false leads and alternative truths are what complicate problem management. If it were elementary, the clear head, keen observation, meticulous records and methodical approach would never be required!



Recent comments