
Introducing Incident Management

ITIL has been designed to use a common language to describe processes and functions as clearly as possible. Incident Management is a good example of this.
Incident Management is the most mature of the ITIL processes that we use here at The University of Edinburgh. The process was designed in collaboration with the University of St Andrews and Abertay University in 2010, agreed by the IS Directors that summer, then implemented and improved iteratively since then. It’s the “fire fighter” part of the ITIL processes as it’s reactive and can control Incidents before they get out of hand and become Major Incidents
Incident Management is sometimes referred to as “Call Management” and we call it this in UniDesk our IT Service Management tool.
So if you use the “Call Management” module in UniDesk to log calls, or to handle calls that you’ve received from users, you’re using our Incident Management Process.
Here at The University of Edinburgh we have first line and second line Incident Management.
First line is the first team you contact in relation to your Incident or Service Request and will usually be a “Service Desk”. The “Service Desk” is an ITIL Function.
In many cases this will be IS Helpline. If a call can be resolved immediately, or without leaving the “Service Desk” then it is classed as a First line call. If it has to be escalated to another team for resolution it becomes a Second line call.
The Cambridge English Dictionary describes the word incident as
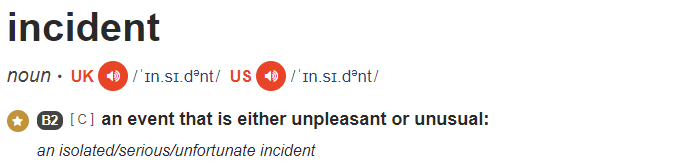
Incident dictionary definition
In ITIL terms an Incident is defined as “Incident: An unplanned interruption to a service or reduction in the quality of service”
Not too different from the dictionary perspective really.
In our Incident Management process an Incident would be something like a computer not starting when the power button is pressed, or a printer with an error on its control panel that can’t be cleared.
Another term used in Incident Management is Service Request and this is defined as “A request from a user or a user’s authorized representative that initiates a service action which has been agreed as a normal part of service delivery”
Again, looking at our process, a Service Request would be something like a new user asking for their UUN and password, or someone asking to be issued a printer toner cartridge because they hadn’t received one through the automatic ordering process.
Building on standard Incident Management, ITIL describes a Major Incident as “The highest category of impact for an incident. A Major Incident results in significant disruption to the business.”
For us a Major Incident would be something like the entire print service being unavailable for half a day during exam revision, due to a problem with the vendor’s software.
The time of year and scale of impact defines the severity of the incident and there are 3 triggers in this particular example
“the entire print service” “half a day” and “exam revision”
A Major Incident can be triggered by a number of things, including the importance of the service to your users, by the duration of the event or by the time of year that the Incident has occurred.
There will be thresholds set for these types of triggers and an incident will always become a Major Incident when it passes over any of your defined thresholds.
A Service Continuity Event is more serious than a Major Incident, it will usually be triggered by a service disruption or organizational risk that requires something greater than the organization’s standard response. The University having to close for 3 days due to severe weather is an example of a Service Continuity Event.
So you can see that ITIL is using common language to describe processes and it not only covers Incident Management, but also request fulfillment.
I’ll speak more about ITIL Incident Management process, ITIL functions and Major Incident Management in future blog posts, so keep following for more on the key ITIL processes

1 replies to “Introducing Incident Management”
Leave a reply
You must be logged in to post a comment.

ITIL Tattle informative as ever!