Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
Here is a process that I have used to generate transcripts for research interviews using locally-installed AI tools. This avoids any concerns about uploading potentially sensitive research data to systems that you don’t control.
I’ve found the quality of these transcripts to be pretty good – there are definitely still some small mistakes, but those are quick to correct on a first pass through the data. It’s also worth noting that the Whisper AI has been trained to eliminate hesitations, so something like “I used, um… I used AI” might just become “I used AI” in the transcript. It also does not identify multiple speakers (e.g., interviewer and interviewee) so that needs to be done separately – again, I’ve found that quick to do on a first pass through the data.
4. Choose the model – I recommend “medium.en” for a balance of quality and speed (you will need to download it the first time you use it)
5. Click the “Generate” button to start the transcription.
You get a progress bar, but it is not very informative!. In practice, I have found that when using medium.en, the transcription process takes about the same duration as the recording.
The transcript will be saves as an .srt file alongside the recording.
To tidy up the output:
1. Open the .srt file in Subtitle Edit.
2. Remove the line breaks:
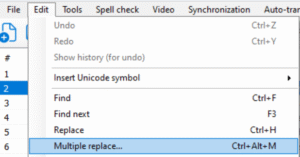
(a) click on “Edit > Multiple replace…”
(b) put a space in the “Replace with” field and “\r\n” in the “Find what” field, to find all line breaks and replace them with nothing:
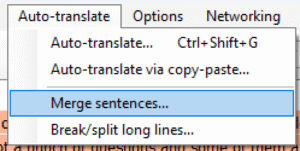
3. Use “Auto-translate > Merge sentences…” to combine any sentences that have been split across multiple lines into a single line:
4. Save the file as a spreadsheet: “File > Save As > csv2” (I’ve not experimented with all of the different output formats, but I’ve found csv2 works quite well).
From 8th to 12th September 2025, I’m taking part in strike action called by UCU Edinburgh, as a result of University of Edinburgh’s refusal to rule out compulsory redundancies.
Management are pushing on with their plans to cut £140 million from the University’s annual budget, including £90 million of cuts to staff. These plans undermine student learning conditions, staff job security, staff wellbeing and the future of quality higher education at the University. For more information, see the Joint Unions Finance Working Group posts: https://www.ucuedinburgh.org.uk/ju-finance-working-group-1
The University’s Senior Leadership Team have done a really poor job of explaining their plan. Why are cuts of this scale needed, and why is their plan the best way to achieve it? They have not been able to give convincing answers, for over a year now! I’m not alone in being disappointed by this:
In the 2025 Staff Survey, only 18% of staff agreed that they “have confidence in the University’s senior leaders” (in the School of Mathematics, it was only 5%!)
In May 2025, the University Senate passed a historic Vote of No Confidence in Senior Management’s financial proposals
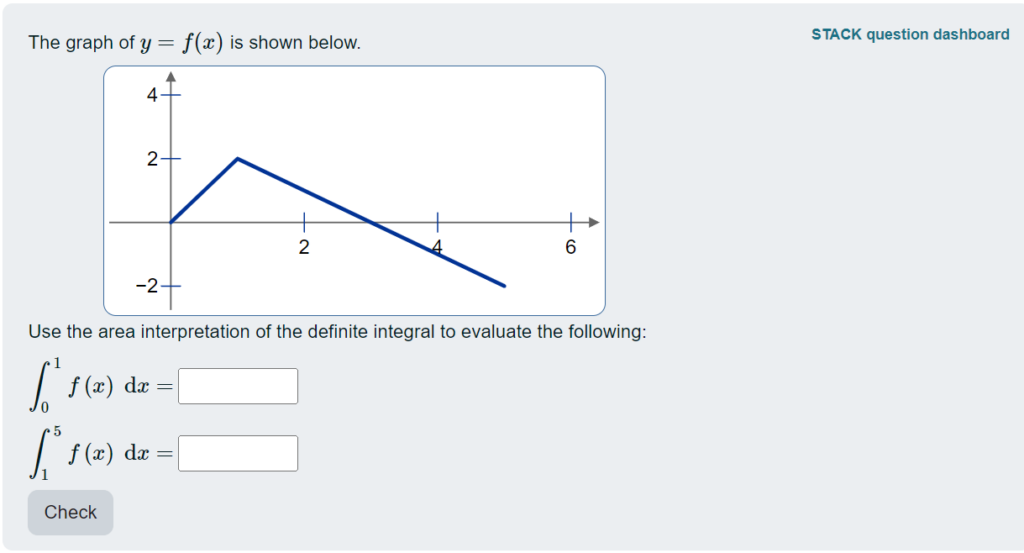
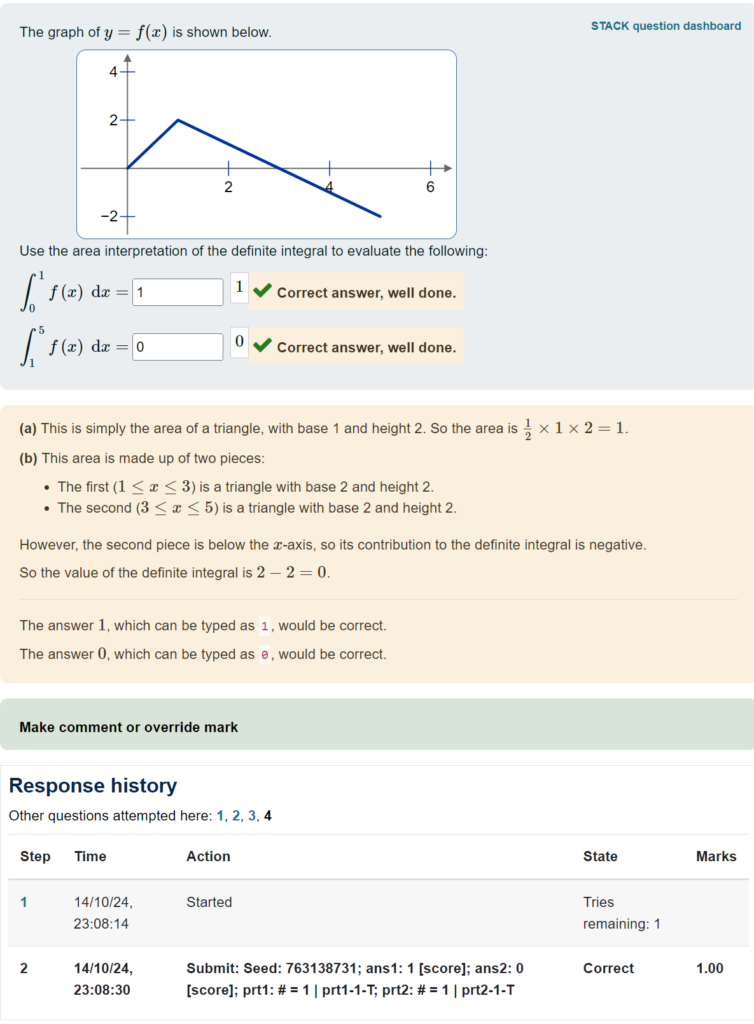
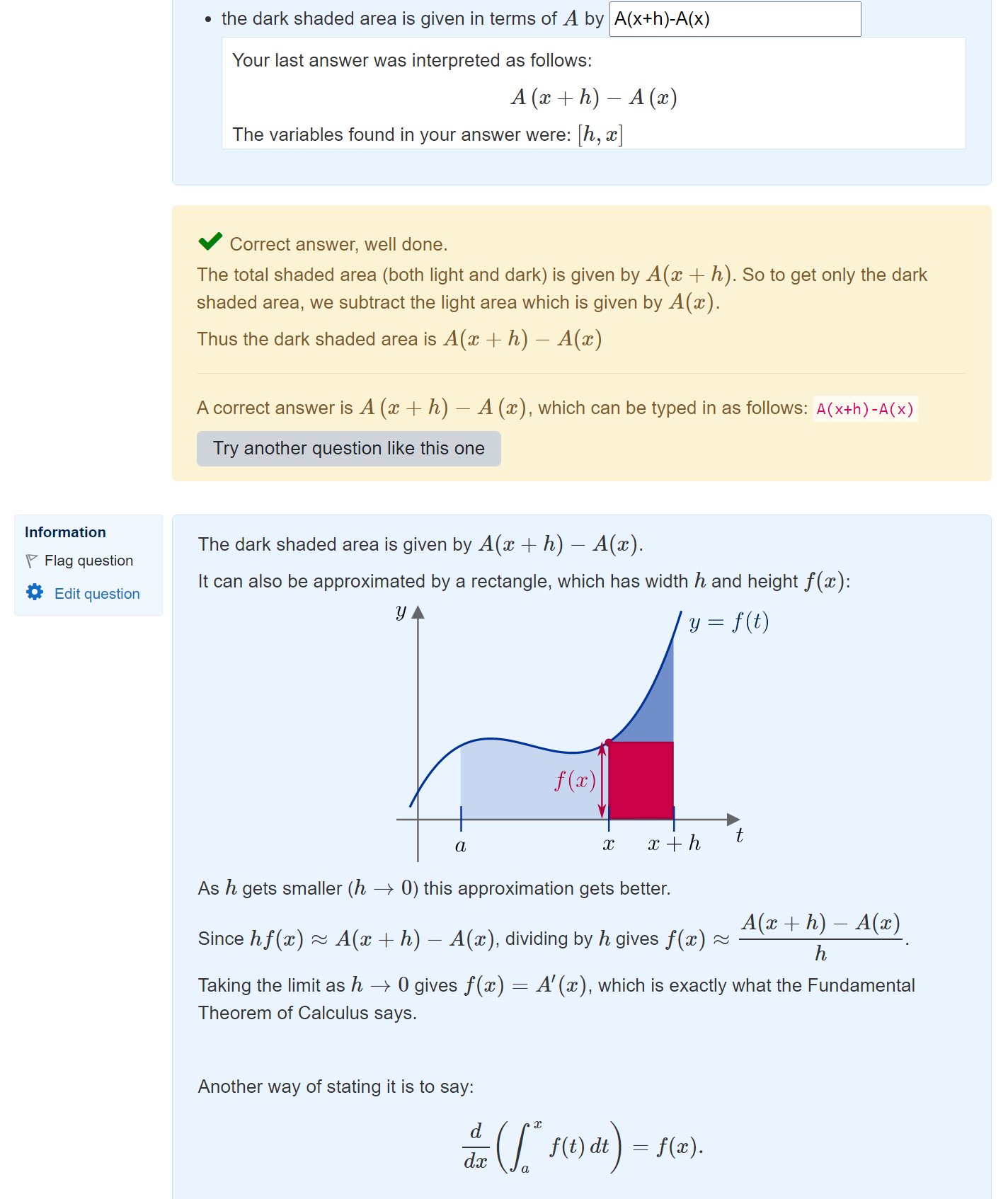
When students answer STACK questions, the Moodle quiz system stores lots of information about their work. How can we get access to the data to learn from it?
The STACK plugin provides an overview of how students responded to the question. In particular, this shows
To get access to this report, as a teacher, click on the “STACK question dashboard” link at the top-right of the question:
Then select the “Analyze responses” option from the top menu bar:
I find the first section of the response analysis page quite helpful to get an overview of how frequently students ended up at different parts of the potential response tree:
For instance, this shows that in prt2, 78 responses (which was 15% of the total) ended up at prt2-2-T, which was a node that I included to check for a specific error and to give feedback accordingly.
You can also see the raw data at the end of the page:
This packs in quite a lot of information! This example shows that variant number 2 was answered 75 times, and then we see the different responses ordered from most to least common – in particular, 31 of the responses were the correct answer (3/2 for ans1 and 4 for ans2 for this variant of the question).
I find it useful to use the browser’s “find text in page” search function, to look for instances of a particular PRT node that I’m interested in. If you want to do a more methodical analysis, you might want to copy/paste this data into a text file and do some processing offline.
It’s also worth checking in case there are particularly common incorrect responses that you hadn’t anticipated. Of course, it can be tricky to figure out from the final answers alone what error the students might have made! But if you can, then you may want to add a node to your PRT that gives feedback on this error. This paper gives a nice example of the process of updating a PRT based on the response data:
Alarfaj, M., & Sangwin, C. (2022). Updating STACK Potential Response Trees Based on Separated Concerns. International Journal of Emerging Technologies in Learning (iJET), 17(23), Article 23. https://doi.org/10.3991/ijet.v17i23.35929
Quiz results report
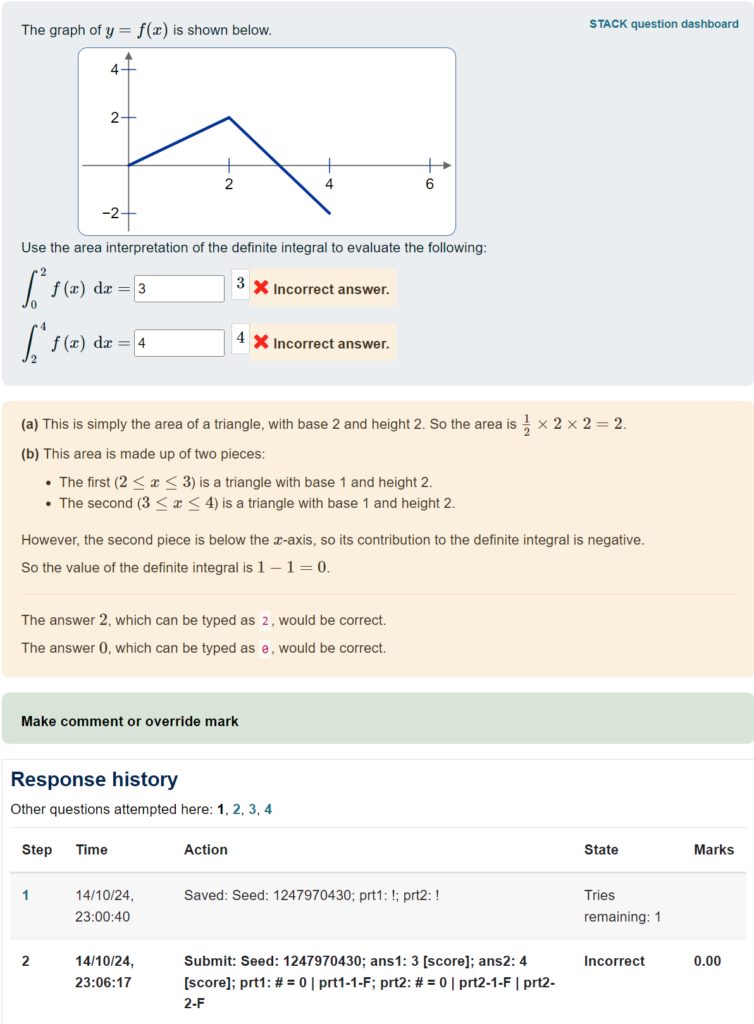
If the question attempts took place in a quiz, you can also see data about them from the quiz results report.
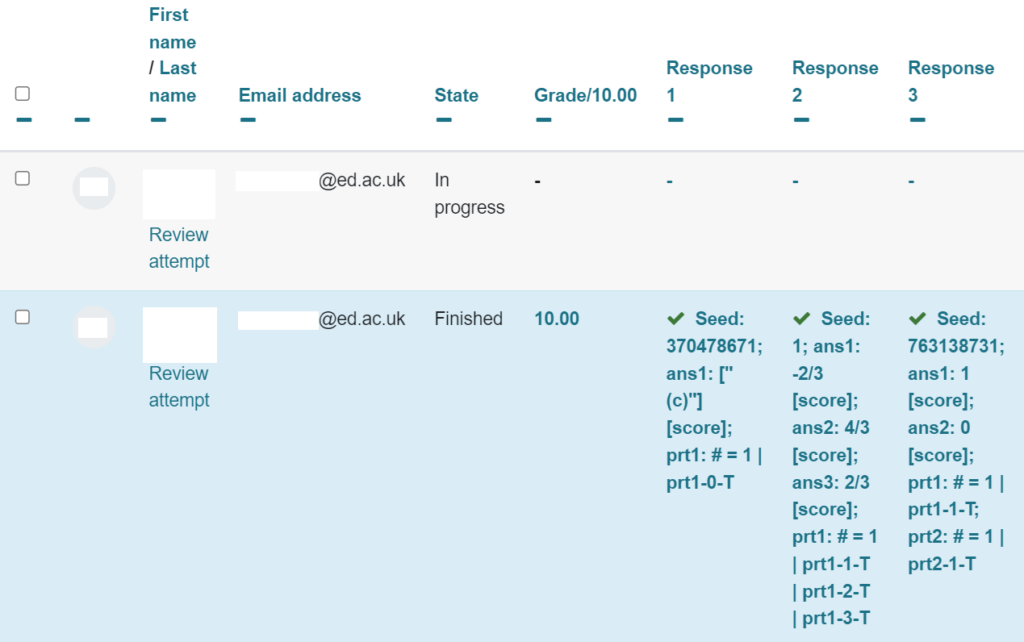
To see this, go to the quiz, then choose the Results tab. You’ll see a table with a row for each student, and a column for each question on the quiz. In the default “Grades” report, the entries in the table are the grades. You can also switch to the “Results” report (using the dropdown list just below the “Quiz / Settings / Questions / Results” tabs), and the entries in the table will show you the same sort of text as in the “raw data” shown above.
Here’s an example of what it looks like, where “Response 3” shows the same question as above:
You can download a spreadsheet of all this data for offline work. However, it’s important to note that this table only shows the student’s last attempt at the question.
You can also click on an individual entry, to see a preview of the question.
You can see at the bottom of the preview the same response summary, along with the time when the student submitted the answer.
Importantly, this quiz used “interactive mode”, so students were able to “try another question like this”. You can see at the bottom there are links “1, 2, 3, 4” to the different attempts. Here is what the student’s first attempt looked like:
This lets you drill down to see how individual students worked through the questions. But it’s a very manual process…
Database query
It’s helpful to be able to be able to get access to all of the response data at once – particularly for research purposes. I first did this in a study involving hundreds of students, so it was important to be able to get all the data in an efficient way!
Since I had Moodle Administrator access, I was able to use the “Ad-hoc database queries” plugin. (If you want to use the plugin, you’ll either need Administrator access, or ask your administrator to install it and give you access to it.)
I put together an SQL query to extract all student attempts at questions in a given quiz:
When you run the query using the ad-hoc database queries plugin, you are prompted to enter the quiz id. The plugin then produces a report that you can download as a spreadsheet. Here is an excerpt of a few of the relevant columns, showing all four attempts by the student from the example above:
Many conferences provide a Word template that must be used for papers (e.g., FAME), and these templates use Word’s styles features to provide consistent formatting. I use Zotero to maintain my reference database, and Zotero’s Word plugin to insert references and automatically generate the reference list. However the reference list formatting ends up being incorrect!
Zotero inserts the reference list and styles it with the “Bibliography” style (which has double-line spacing), while the template uses the “References” style (which is more compact). If you manually apply the “References” style, it will get undone when Zotero refreshes the reference list.
Here is how I’ve fixed the reference list formatting, by modifying the styles.
Put the cursor on the first item in the reference list, and select the “References” style. That will apply the proper style to the first item.
Now click on the dropdown next to the “Bibliography” style, and select “Update Biblography to Match Selection”:
That will change Zotero’s “Bibliography” style to match the correct style in the template. Importantly, that will make the reference list take up the correct amount of space, so you know how close you are to the page limit!
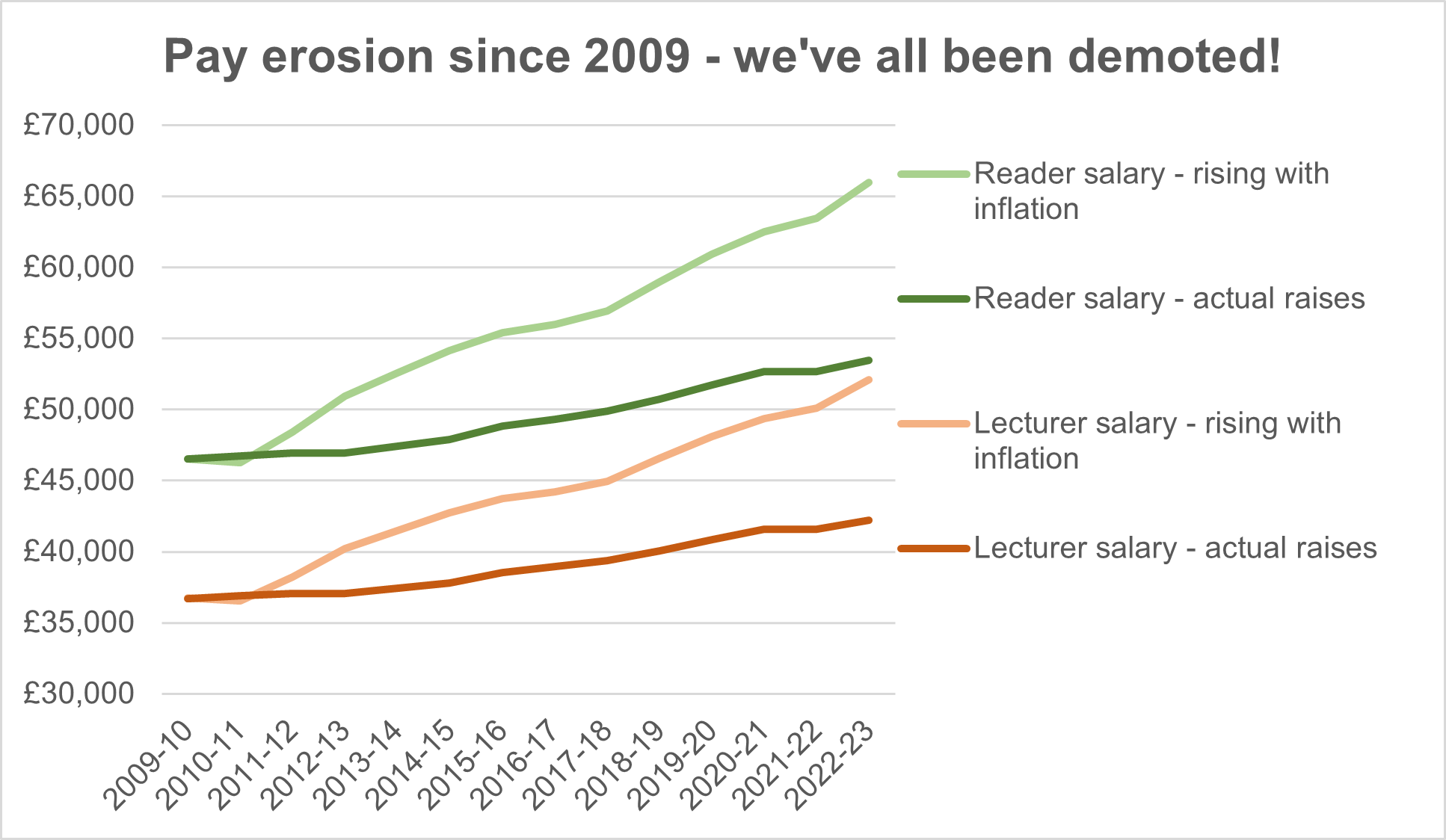
For me, one of the main reasons is the way that pay has been eroded since 2009 (which happens to be around the time I started working for the University of Edinburgh).
This chart will be familiar to colleagues in the School of Mathematics, since I stuck it up in our common room above the sink! It shows the starting salary for a Lecturer, and for a Reader (the next grade up), and how these have been increased each year by employers since 2009. I picked these job titles as examples, but the same pattern is true for other types of roles too.
The chart also shows what would have happened if employers increased the salaries each year to keep track with inflation (the RPI version of it):
The key things I take from this chart are:
actual pay rises have not kept track with inflation, so
the Reader is now being paid what the Lecturer would have been paid if employers had raised pay in line with inflation.
So – pay has been gradually eroded over the past decade or so, to such an extent that university staff are now effectively demoted by one grade on the salary scale.
If all university staff were demoted by one grade overnight, I’m pretty sure there would be outrage! That’s what I feel looking at this data, showing that we’ve been demoted gradually over many years.
The current dispute is about the pay increase for 2022/23. UCU has asked for an increase of RPI+2% for that year, which would go only a little way to closing the gap. Employers have imposed an increase of 5% and refuse to discuss it any further.
A second reason for me taking part in the strike is to show my disappointment with senior management. I know I’m not alone in this – in the recent Staff Engagement Survey, just 23% of staff agreed with the statement “I have confidence in the university leadership”. In the College of Science and Engineering (where I work), it was just 12% of staff.
The dispute about pay is a national one, and our Principal, Peter Mathieson, has pointed to the affordability of pay increases across the university sector as a reason for not supporting inflation-matching pay rises for his staff.
I reached out personally to the Principal on 30th May to ask:
You point to how some institutions may be unable to afford a larger pay increase than the sub-inflationary one that has been imposed. What are you doing as a leader in the sector to resolve this? Our sector should be strong enough to support pay rises in line with inflation!
I’ve not asked permission to share his reply, so I won’t – but in essence it was: “what do you propose?” I found this shocking. I thought he was supposed to be providing the strategic leadership, in return for his £400k+ salary! It’s not even like this is a one-off issue that could have caught management by surprise – as the chart shows, it’s a systemic issue. Why are management content to do nothing about this year after year?
Senior management have also turned down an opportunity to stop the strikes in week 2 of our semester. The local UCU branch offered to cancel the strikes in return for restoring pay that had been withheld from colleagues taking part in the marking and assessment boycott (and who are now being asked to complete the marking since the boycott has ended). The offer from UCU was refused by management. Meanwhile management are painting a different picture for students (emphasis mine):
“we hope to minimise disruption to our students in the future as much as possible” (Peter Mathieson, Principal and Vice-Chancellor, in an email of 18 September)
“For those of you who are awaiting awards and/or marks, we’re doing all we can to make sure that your assessments are marked as soon as possible and returned” (Colm Harmon, Vice-Principal Students and Lucy Evans, Deputy Secretary Students, in an email of 7 September)
Those words sound hollow to me, in light of management’s decision to refuse UCU’s offer on 18 September – which has the effect of knocking out 5 working days when colleagues could be getting on with teaching semester 1 courses and dealing with the backlog of marking.
If you’re a student, please let University management know what you think by emailing the Principal, Peter Mathieson (principal@ed.ac.uk) and/or Vice-Principal Students, Colm Harmon (Colm.Harmon@ed.ac.uk).
If you’re a colleague who’s not already in UCU, it’s never too late to join the union!
The Moodle quiz offers a huge range of settings for the timing, number of attempts, and feedback that is offered to students. Deciding how best to use these options is a tricky question – and actually forms the basis for some of the questions in the research agenda that I recently developed in collaboration with several colleagues:
Q27. How can formative e-assessments improve students’ performance in later assessments?
Q28. How can regular summative e-assessments support learning?
Q29. What are suitable roles for e-assessment in formative and summative assessment?
Q30. To what extent does the timing and frequency of e-assessments during a course affect student learning?
Q31. What are the relations between the mode of course instruction and students’ performance and activity in e-assessment?
I’m sure that I’ve not explored the full potential of all the Moodle quiz options, but here are some examples of settings that I use in my Fundamentals of Algebra and Calculus course.
Course materials
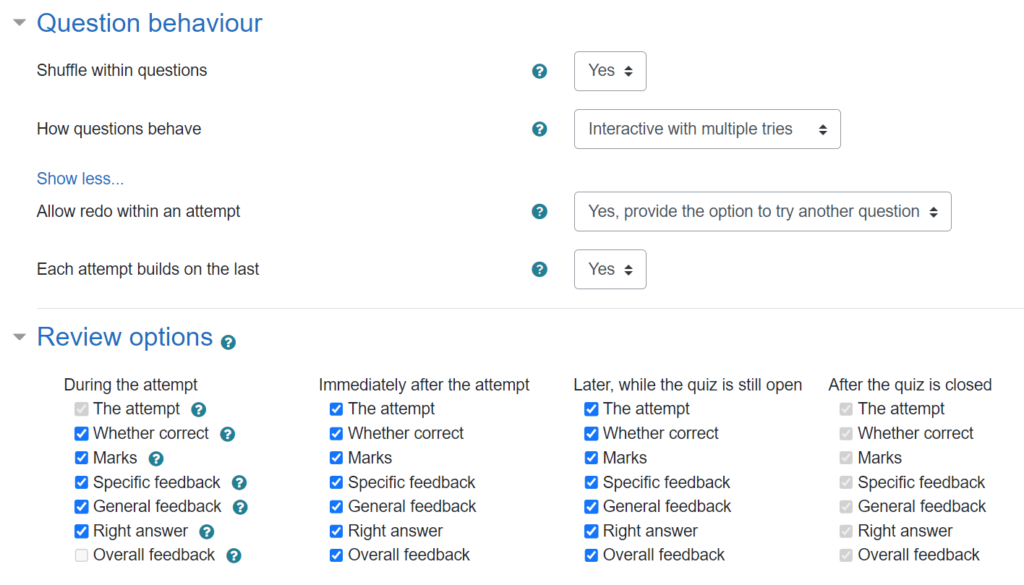
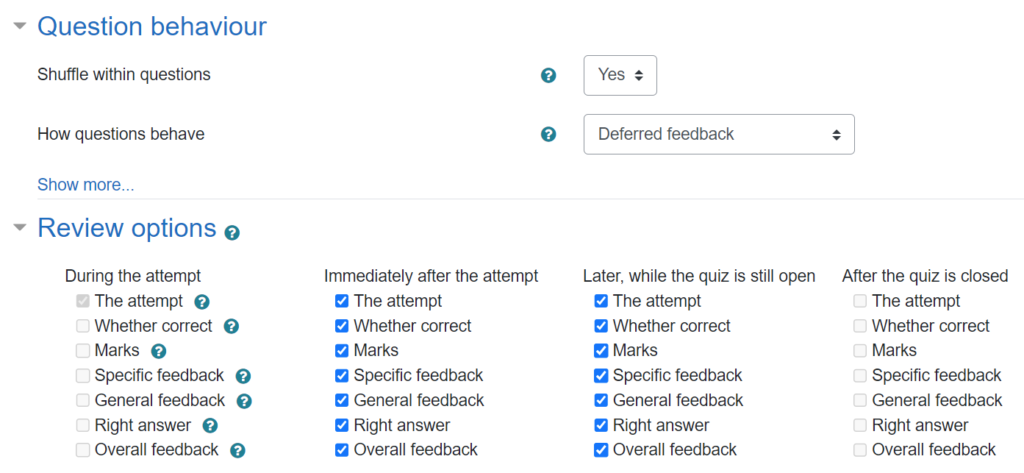
For the course materials within FAC, I have put all the feedback settings to the max, including the option to redo individual questions:
The “scores” on those quizzes really don’t matter for anything, and actually most students never even submit the whole quiz to be graded, since they can see the results question-by-question as they go through.
Practice quizzes
Each week there is an assessed quiz that contributes to the students’ grades (see below) – but before they can take that quiz, they need to score at least 80% on the week’s Practice Quiz.
For the Practice Quiz, students can have an unlimited number of attempts – but there is no way to replace individual questions. Instead, students need to complete the whole quiz and submit it to get their score at the end (as preparation for the way it will work in the assessed quiz).
Assessed quizzes
Each week there is a “Final Test” quiz that contributes to the students’ grades. Scores of over 80% are a “Mastery” result, and students need to get at least 7 Mastery results across the 10 weeks to pass the course. The grading scheme is a bit more complicated than that; you can see the full details in my paper about the course design and my post about how to set it up in the Moodle gradebook.
Having the requirement to score at least 80% on the Practice Quiz (which typically has very similar tasks to the Final Test) means that students should be well-prepared to succeed.
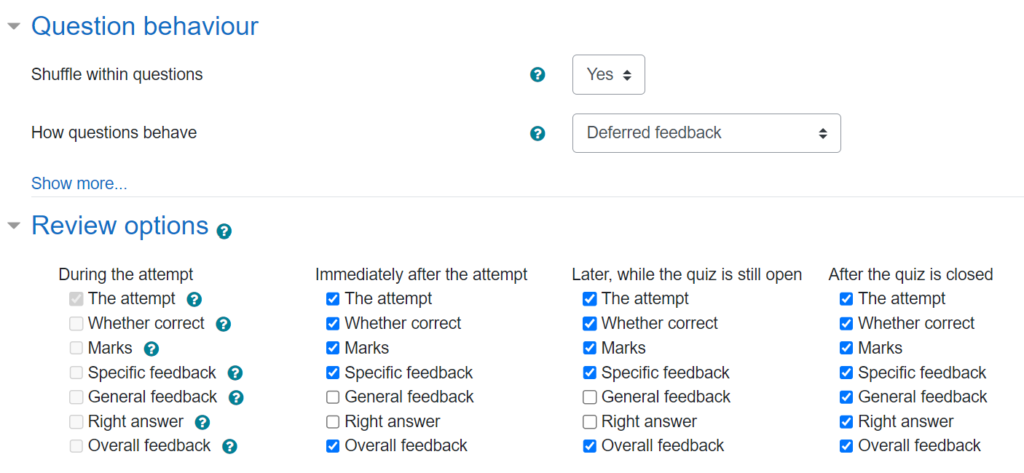
The Final Test itself uses more restrictive settings to control when feedback is available, since I wanted to avoid having worked solutions circulating while other students have yet to complete the quiz. In particular, the “general feedback” (i.e., worked solution) and “right answer” are only available after the quiz is closed:
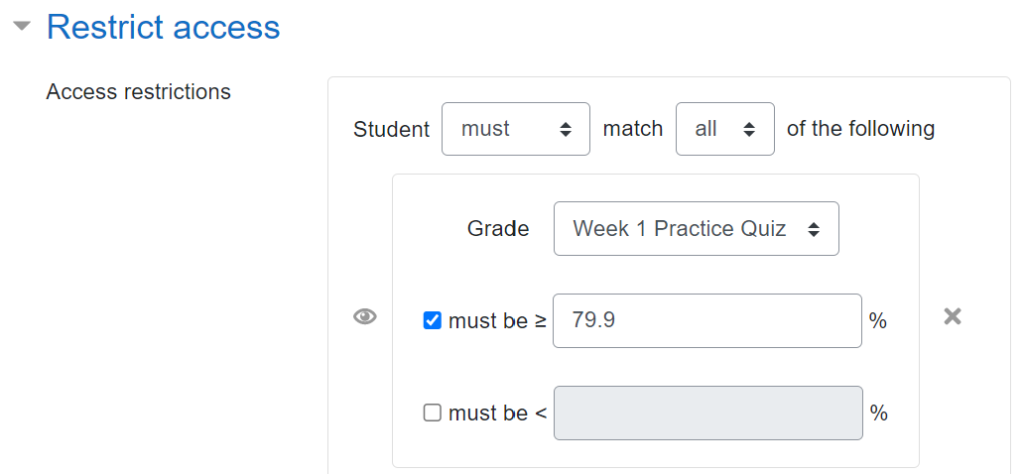
There is only 1 attempt allowed at this quiz, with a time limit of 90 minutes from when the quiz is opened. Students need to complete each week’s quiz by a regular deadline. However, if students don’t meet the Mastery threshold, there is a resit version that becomes available the next day (again, set up using the “restrict access” feature so that it only appears for students who need it).
Other approaches?
As I mentioned, I’ve only scratched the surface of what’s possible with the Moodle quiz settings. I know other colleagues have set up quizzes where students can make multiple attempts, and the grade is based on the average of the attempts (so as to incentivise trying hard on the first attempt, but allowing for students to improve if they’re not happy with a bad first attempt). It’s also possible to set penalties within questions, so that you can use the interactive quiz mode (like the course materials example above): that allows students to redo an individual question if they’re not happy with the score, but possibly with a penalty (again, to encourage students to take the first attempt seriously).
I often work with student data for research purposes, and one of the first steps I take before doing any analyses is to remove identifying details.
Our students have a “University User Name” (UUN) which is an S followed by a 7-digit number (e.g. “S1234567”), which can be used to link different datasets together. I need to replace these identifiers with new IDs, so that the resulting datasets have no personal identifiers in them.
I’ve written a simple R script that can read in multiple .csv files, and replace the identifiers in a consistent way. It also produces a lookup table so that I can de-anonymise the data if needed. But the main thing is that it produces new versions of all the .csv files with all personal identifiers removed!
In my online course Fundamentals of Algebra and Calculus, there were several places where I wanted to encourage students to engage with a key proof while reading the text.
One approach to this is to ask proof comprehension questions after giving the proof, but I’ve also tried writing some sequences of questions that lead the students through the proof in a scaffolded/structured way.
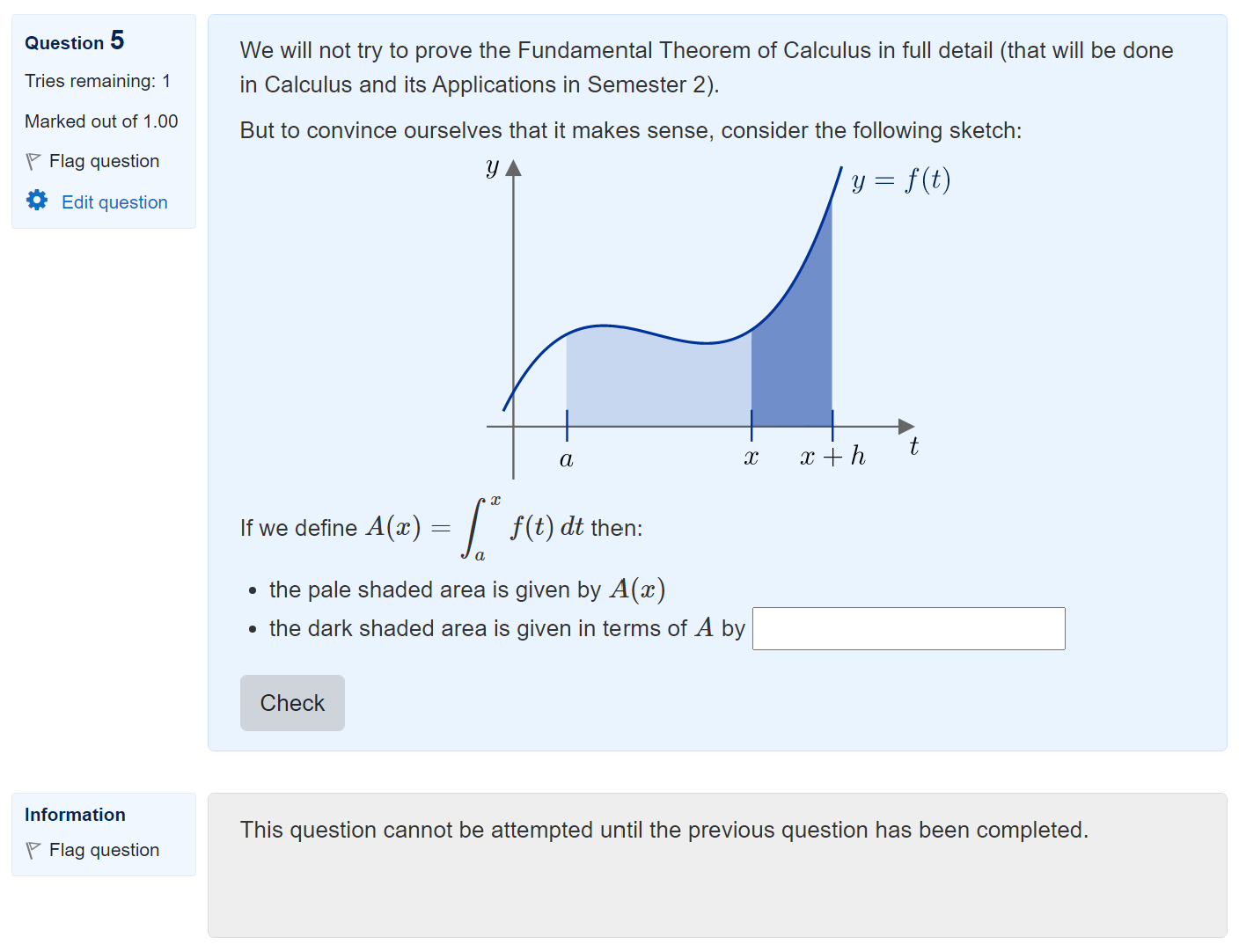
Here’s a simple example, of a sketch proof of the Fundamental Theorem of Calculus:
Students can’t see the next part of the proof until they give an answer. Once they have submitted their answer, the next part is revealed:
I’ve used this approach in other places in the course, sometimes with more than one step.
The way to do this in Moodle is by having the quiz settings set to “Interactive with multiple tries”:Then using the little padlock symbols that appear at the right-hand side between questions on the “Edit questions” page:
After clicking the padlock, it changes to locked to indicate that students must answer the first question to see the second:
I’ve not done any serious evaluation of this approach, but my intuition is that it’s a good way to direct students’ attention to certain parts of a proof and encourage them to be more active in their reading.
In my course Fundamentals of Algebra and Calculus, students complete weekly Unit Tests. Their grade is determined by the number of Unit Tests passed at Mastery (80%+) or Distinction (95%+) levels. For instance, to pass the course, students need to get Mastery in at least 7 of the 10 units. You can find more details about the course in this paper:
Kinnear, G., Wood, A. K., Gratwick, R. (2021). Designing and evaluating an online course to support transition to university mathematics. International Journal of Mathematical Education in Science and Technology. https://doi.org/10.1080/0020739X.2021.1962554
All the Unit Tests are set up as Moodle quizzes, and I needed a way to compute the number of tests completed as Mastery level (and at Distinction level) for each student.
To make matters more complicated, there are 4 different versions of each Unit Test:
Unit Test – the first attempt
Unit Test Resit – a second attempt, available to students shortly after the first attempt if they did not reach Mastery
Unit Test (Extra Resit) – a third attempt, available at the end of semester
Unit Test (Resit Diet) – a fourth attempt, available during the resit diet in August
Each subsequent attempt replaces the result of previous ones – e.g. if a student with a Mastery result on the first attempt decides to take the Unit Test (Extra Resit) to try to get a Distinction, then they will lose the Mastery result if they do not reach the 80% threshold.
To set this up in the Moodle gradebook, I have given each of the variants an ID, with the pattern:
WnFT
WnFTR
WnFTR2
WnFTRD
(where n is the week number).
Then I have added a calculated grade item called “Number of Mastery results”, with a complicated formula to determine this. It is the sum of 10 terms like this:
where this snippet computes the number of Mastery results in week 1 (i.e. it will return 0 or 1).
Note that the 25.5 appears throughout this expression because that is the threshold for 80% on these tests.
ceil([[W1FTRD]]/32)*floor([[W1FTRD]]/25.5) means “if they took the Resit Diet version, then use their score on that to decide if they got a Mastery result”
(1-ceil([[W1FTRD]]/32))*(...) means “if they didn’t take the Resit Diet version, then use their other scores to decide”
There’s then a similar pattern with W1FTR2
And finally, if students didn’t take either W1FTRD or W1FTR2, we use the best of the W1FT and W1FTR results to decide (simple “best of” is OK here, since students can only take W1FTR if they did not get Mastery on W1FT).
This is all quite complicated, I know! It has grown up over time, as the FTR2 and FTRD versions were added after I first set up this approach.
Also, when I first implemented this, our version of Moodle did not support “if” statements – since the Moodle grade calculations can now make use of “if” statements, this calculation could be greatly simplified.
I’m now very used to the referencing style used in education journals (e.g. “according to Author (1999)”), to the point where the numbered style more commonly used in science (e.g. “according to [1]”) really annoys me!
This year I’m supervising three undergraduate projects, and I’ve asked them to use the APA style for referencing in their reports.
It took me a while to find a way of doing this in LaTeX that I was happy with, so to smooth the path for my students I shared this version of the project template, where I’d made all the necessary changes to implement APA style:
% formatting of hyperlinks
\usepackage{url}
\usepackage{hyperref}
\usepackage{xcolor}
\hypersetup{
colorlinks,
linkcolor={red!50!black},
citecolor={blue!50!black},
urlcolor={blue!80!black}
}
% Use biblatex for references - change style= as appropriate
\usepackage[natbib=true,backend=biber,sorting=nyt,style=apa]{biblatex}
\renewcommand*{\bibfont}{\fontsize{10}{12}\selectfont}
% add your references to this file
\addbibresource{references.bib}
At the end of the document:
\printbibliography{}
And make sure to add references.bib to your project, with all the bibtex references. I’ve found Mybib.com a really useful tool for this, though I mainly use Zotero as my reference manager (and this can import easily into Overleaf).