
Getting Data from the Web using Python
If you do any data analysis on a computer, the first step is loading that data into the computer program you want to use to analyse it.
This is frequently a frustrating business that is harder than it should be…
Below I show two ways of getting data into Python using Pandas DataFrames.
- The first is broadly how to read in a text file.
- Then I give a brief intro about how to scrape html from websites.
- Finally, I suggest how this can scale and really save you time.
You can download a working Jupyter notebook of the examples below, and more, from my GitLab repository .
1. Reading data-files into Pandas from from the web
Normally, we would do this by having a text file laid out a bit like a table where the entries are separated by commas, spaces or tabs. To load this into Python, it is easy if we use Pandas DataFrames. A DataFrame object is basically a bit like a table in that it has rows and columns and that each column holds similar datatypes such as Strings, integers…
import Pandas as pd file = "myDataFile.csv" df = pd.read_csv(file, delim=",")
The simplest example of getting data from the web is where we load a csv file straight from the web instead of downloading it to our computer first. This is really easy because Pandas can take urls directly as well as local files.
Have a look at an example for 1932 from the Southern California earthquake catalogue and how we can read it in using Pandas to skip the initial comment lines and use whitespace as the delimiter (i.e. what separates the data):
url = "http://service.scedc.caltech.edu/ftp/catalogs/SCEC_DC/1932.catalog" df = pd.read_csv(url , delim_whitespace=True, skiprows=9)
Pandas can also read excel files. Have a look at the Human-Induced Earthquake Database. This website documents many human induced earthquakes and has various graphs presenting different summaries. On the front page, they link to an excel file – the url is copied into the code below which loads the data straight to a Pandas DataFrame.
url = "http://inducedearthquakes.org/wp-content/uploads/2018/08/The_Human_Induced_Earthquake_Database.xlsx" df = pd.read_excel( url ) df.head()
Let’s do a quick summary plot of the causes of induced earthquakes.
df['Earthquake cause (main class)'].value_counts().plot(kind='bar')
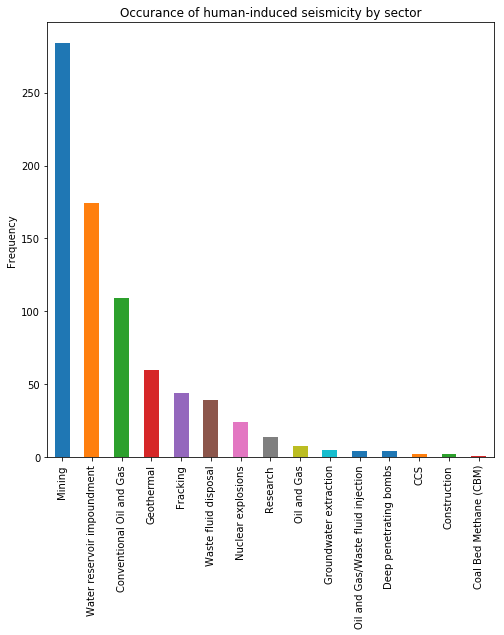
2. Scraping data from HTML pages
It is not that surprising that you can load files directly from the web.
However, what about content that is embedded within a webpage? Maybe there is a table of data presented on a website that you would like to work with?
Have a look at this page on the Our World in Data site: https://ourworldindata.org/natural-catastrophes
Some of the underlying data is available here: https://ourworldindata.org/ofdacred-international-disaster-data
This page has two tables of data in it. How can we access it?
The code below extracts all of the html tables in the webpage to a list of DataFrames called df_list.
df_list = pd.read_html( "https://ourworldindata.org/ofdacred-international-disaster-data" )
We can then extract the first table, index it by the date and plot some of the results:
df_table1 = df_list[0] df1.index = df1[ 'Yearly average global annual deaths from natural disasters, by decade' ] df1 = df1.drop( 'Yearly average global annual deaths from natural disasters, by decade', 1 )
For a stacked area plot
df1.plot( kind="area" )
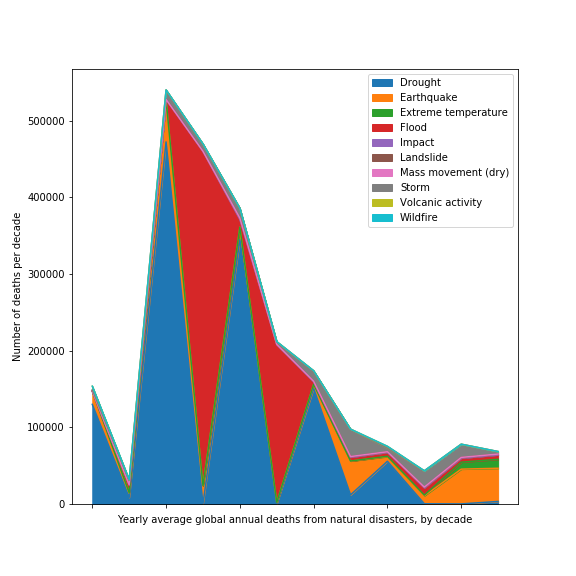
Whilst this graph clearly needs the x-axis labels sorting out – it is not far off a publishable figure.
3. Scaling Up: Automate Data Collection
In the first section we saw how to load a single year of data from the Southern California earthquake catalogue.
url = "http://service.scedc.caltech.edu/ftp/catalogs/SCEC_DC/1932.catalog" df = pd.read_csv(url , delim_whitespace=True, skiprows=9)
This was helpful, but the example below shows how Python can be really useful in automating the loading of datasets.
The Southern California catalogue is broken down into annual catalogues here.
Notice the regular structure for each file. Below we load each years catalogue in turn into a DataFrame and then append it to a master copy so that we end up with a full catalogue from 1932-2018. This was really timesaving.
df_full = pd.DataFrame()
for i in range(1932,2019):
url = "http://service.scedc.caltech.edu/ftp/catalogs/SCEC_DC/"+str(i)+".catalog"
print( "Processing year:" + str(i), end='\r')
df_tmp = pd.read_csv(url , delim_whitespace=True, skiprows=9)
df_full = df_full.append( df_tmp )


This has been such an interesting lesson and getting exposed to such great datasets has helped my cause.
One question: How was the data embedded in the https://ourworldindata.org/natural-disasters website/page? Was Tableau used?
Many thanks.
Kind regards,
Sourav
Hi,
Thanks for the question!
The
pd.read_table(url)copies all of the html tables in a webpage to a list of tables in python. This is why I extract the table I want usingdf_table1 = df_list[0].If you view the source code for a halt page, you can get an idea if the data you want is held within a table.
A word of warning, is that this method does not necessarily work if you the webpage you want to extract information from is dynamically generated with JavaScript or similar. I am working on this one…
Best wishes,
Mark
Hey Mnaylor,
I’ve ploughed through multiple books and tutorials but your explanation helped me to finally understand what I was doing. Thanks for this article.