
Martin, a fourth year Computer Science student, is the Learn Foundations Applications Developer within the Digital Learning Applications and Media (DLAM) team this year. His role revolves around developing software solutions to help with the Learn Foundations Project as well as other projects within ISG and particularly enjoys working on projects that have real impacts and make a difference. Outside of work, he appreciates his time off from and a break from studying too, taking time to relax and see friends.
Any student who works in the Learn Foundations Project when asked about the work will probably say it’s not the most exciting. This is just due to the vast scale of the university meaning that any work done on a school’s courses will be done on several hundred courses. That is the bread and butter work of the Learn Foundations Project: building/migrating, mapping and accessibility checking school’s courses – all essential for a consistent VLE (Virtual Learning Environment) user experience.
This means that there can be plenty of repetition for the interns, which is not very exciting but it can also lead to mistakes and inconsistencies between interns. This then means that another intern needs to review the work before it can be signed off.
Last summer that was my world. The key is to get into a rhythm; get some music, a podcast, or some TV show on in the background and then you can plough through the stuff.
However, help is at hand for the interns this summer and in the coming years as automation moves in…
That is where I come in: my title being “Learn Foundations Applications Developer Intern” (bit of a mouthful) means I build software to help with this kind of stuff. Therefore, the major thing I’ve been working on is automating the mapping process.
So, what is mapping then?
Mapping is the process of laying out the structure of a Learn course into an excel file so that each item of the course is easily visible and then adding information to it. This information, such as if the item is hidden, what type it is (link, tool, item) and the most interesting is learning type (more on that later). Below you can see an example course laid out in the correct format.
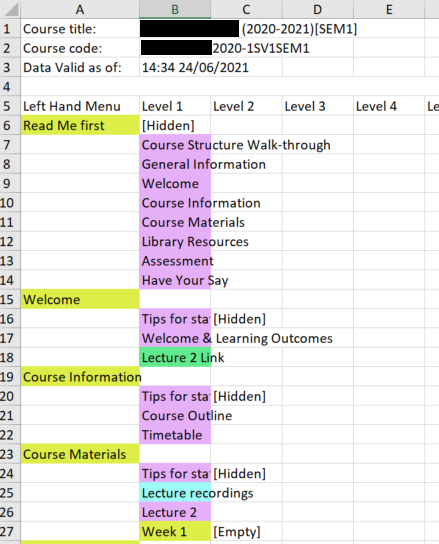
This data is collected and analysed to form reports that are then sent back to the schools and used by ISG and the schools for learning design and curriculum insights. This is done with help of large amounts of excel formulas and macros that produce stats, such as what proportion items are at level 1 or how many unique names are in the left hand menu items.
So how are the excel sheets built?
Well, the short answer is my code pulls data out of learn, faffs around with it and then throws it in the excel file. The long answer is below (feel free to skip to the end!).
<Technical details>
The first job is to get the data out of Learn. For this, I use Learn’s API. API stands for Application Programming Interface, which is essentially a list of commands I can send to Learn to get it to do things for me. I can command it to delete an item, add a student, make an announcement or tell me about an assignment.
The beauty of this is I can make many of these commands very quickly and automatically without needing a human. APIs are an essential tool for developers like myself to get other systems to do stuff for us.
In this exact case I use a command called “courses/{courseId}/contents” where I replace the {courseId} with the course code. It will then return to me details about all the items in that course.
Next I build a tree, yes that is build, not grow. In the world of programming, trees are very interesting structures that are quite similar to real trees; they have a root, branches, and leaves. However, as programmers never go outside (and therefore have never seen a real tree), computer trees are upside down with the root at the top and leaves at the bottom!
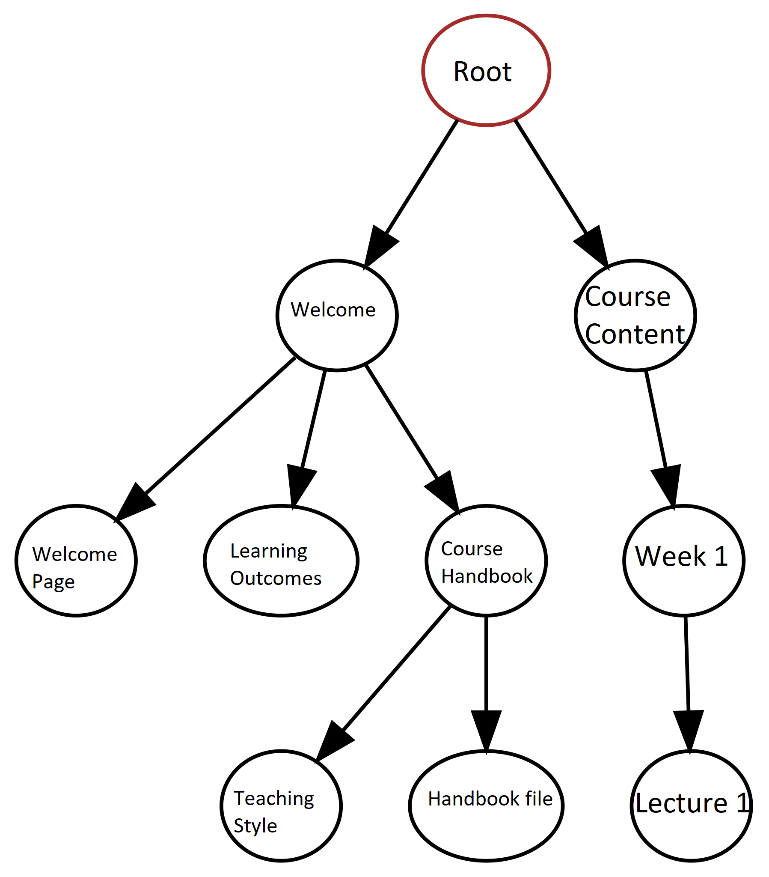
This basically means taking all the data that Learn sends me back and building this tree up one node at a time adding to the root. It also means that later, on when I want to build my excel file, I can get the data back out of the tree. It also has some very useful features like being able to tell quickly what items are within a folder or find the parent of an item.
The final step is adding the information into the excel file. For this, I use a library – not a large building with books – but a bunch of code someone else has already written. Don’t worry, I’ve not stolen it from someone else’s computer, plenty of libraries are made by companies and individuals and released for free onto the internet. Now it’s not that I’m too lazy to write my own code, it’s just that the library has already been built and it’s probably been built much better than any code I could write (the authors have had much more time and are likely experts in that area). The use of a library saves me time and libraries are usually much better and more polished than code that I could write quickly.
The library in question is PhpSpreadsheet and gives me an easy way to place the text and colour the cells of the excel file. The code simply starts at the root (top) of the tree and work its way down adding the name and colour coding the cells.
</Technical Details>
Alright, that’s enough of that.
Earlier I mentioned I would talk about learning types – the big part of this mapping exercise. There are six of these: Acquisition, Inquiry, Practice, Production, Discussion and Collaboration. The people who do learning design are really keen to understand how courses are built and what proportion of each type is in use.
This is somewhat automated as my code makes a guess at the learning type based on a series of assumptions. Some target common elements like the welcome page (and label it acquisition) or make assumptions such as if an item has ‘lecture’ in the title it’s probably of the acquisition type.
However, the issue is that my code is not 100% correct when doing this guessing as learning types are fairly subjective, so the interns don’t get away with doing no work. Their job is to go in and check the work my code has done and correct any mistakes. It’s also good to have a human in the loop to ensure my code hasn’t messed up majorly!
I hope that gives you an idea of the kind of work that I’ve been doing. The final version of this mapping software is in the works at the moment and should be ready for release before the end of the summer.
To conclude, rejoice Learn Foundation interns for you have less boring work to do! Schools should also be happy that their reports will be completed with less mistakes and with more consistency. The Learn Foundations Project can also be happy as its interns can complete more work over the summer as the mapping is now much quicker.
If you have any questions or are interested in using the software when it is released please get in touch with me martin.lewis@ed.ac.uk or if you are curious about how Learn Foundations uses this software to make its reports to the schools you can get in touch with them learnfoundations@ed.ac.uk .
(Photo by Goran Ivos on Unsplash)
(Original Image by Paddy3118 at https://en.wikipedia.org/wiki/File:Tree_(computer_science).svg edited by Martin Lewis and hereby released under the same CC BY-SA 4.0 license https://creativecommons.org/licenses/by-sa/4.0/deed.en) )
(Photo by Goran Ivos on Unsplash)

