
SETI @ Home ends
I have been feeling curiously nostalgic about the internet these past few days. First, during an online tutorial I was reminded of Dick Hardt’s presentation of Identity 2.0 a few years ago. (https://youtu.be/RrpajcAgR1E) At the time, it seemed almost a no brainer that online authentication and controlling one’s own data would come to the fore.
Unfortunately, and possibly inevitably, corporate interest, and paranoia and sensitivities around security issues put an end to such giddy thinking.
Now, this morning, I hear that the SETI @ Home project is coming to an end – at least in its public facing capacity.
SETI @ Home – was perhaps the most successful citizen science project of all time. Over 2.6 million people in 226 countries offered up their personal PCs to assist in the search for extra terrestrial intelligence.
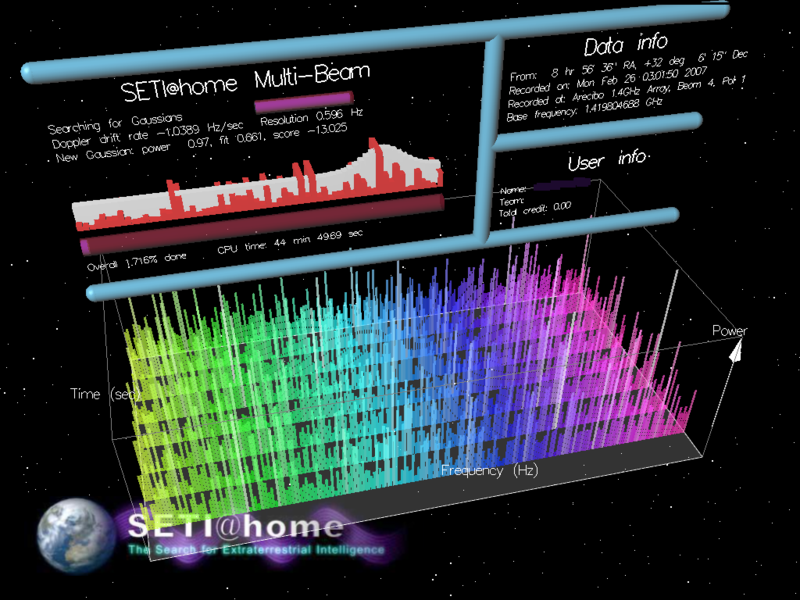
Berkeley University – where the system was developed – would send subscribers blocks of data grabbed from a radio telescope in Puerto Rico which were then analysed by end users via a screensaver program that came into action when the computer was idle.
The interface, at the time, was in itself a thing of beauty – and there was a genuine thrill about being connected live, in real time, receiving and pushing data packets with a west coast American university in the common search for E.T.
It seems curiously ironic to read in this Wired article that the project was developed in order to assist researchers with handling the huge amounts of data generated by the telescopes. And now the project is having to close because of the huge amount of data generated by the SETI @ Home project itself.
In trying to analyse, manage and organise data – we create yet more data. Are we doing something wrong, do you think? What wild, left field ideas can you bring to the issue of data saturation?
(Free Software Foundation. accessed via Wikimedia Commons)
(Free Software Foundation. accessed via Wikimedia Commons)


Recent Comments