

What Counts as Culture? Part I Sentiment Analysis of The Times Music Reviews, 1950-2009
What Counts as Culture? Part I
Sentiment Analysis of The Times Music Reviews, 1950-2009
This blog post has been written by Lucy Havens, a CDCS PhD Affiliate and Training Fellow. It is cross posted from Lucy’s blog, where you’ll find more examples of her work.
Introduction
Alongside my PhD, I’ve been working part-time for the Centre for Data, Culture & Society, collaborating with Dave O’Brien, Orian Brook, and Mark Taylor on a project called “What counts as culture?” The technical side of the project began by selecting articles from The Times Digital Archive using defoe, a tool built to analyze historical books and newspapers using Apache Spark. After reviews from The Times were selected that contained a list of music-related terms (for example: song, band, opera, blues), the dataset was handed over to me for text analysis. The initial questions guiding the project were:
- How differently are music genres portrayed in The Times reviews?
- How does the portrayal of each music genre change over time?
Note: we chose to focus on the genres of opera, jazz, rap, and rock.
The data analysis I have completed so far on this project falls into two steps: corpus summarization and sentiment analysis. Corpus summarization provides a sense of the size and diversity of the corpus. This is a helpful first step when beginning a text analysis project because it helps wrap your head around the data you have to work with. Sentiment analysis provides a sense of how positively, negatively, and neutrally The Times’ critics write about different genres.
Corpus Summarization
To summarize the corpus, I created data visualizations of the total reviews published each year, the length of the reviews, and the top-contributing authors. I also created data visualizations for the specific genres of interest on this project: opera, jazz, rap, and rock. (The Corpus Visualization Jupyter Notebook contains all the code used to create these visualizations with the Python library seaborn.)
The number of reviews published per year in the entire corpus increases on average from the beginning of the corpus in 1950 through the last year of the corpus in 2009. The late 90s and 2000s see the greatest number of articles, though there were also spikes in 1957, 1960, and 1983. While the total number of The Times’ reviews in our corpus increases in the 2000s, the length of these reviews decreases in comparison to the length of reviews from the late 1900s.
Visualizing the length of articles by word count and sentence count estimates shows that most articles are less than 150 sentences and less than 2,000 words. Looking at yearly averages, the reviews’ lengths tend to fall between 15 and 33 sentences, and between 400 and 800 words. The music reviews seem to get longer in the late 1900s and 2000s, with more articles surpassing 200 sentences and nearly reaching 4,000 words. When we read a selection of The Times reviews in our corpus, we found that some reviews had been grouped together; a single file intended to contain a single review actually contained two or three reviews. The word count and sentence count visualizations show clear outliers that may help us identify files that need to be broken up into multiple reviews, improving the quality of our corpus.
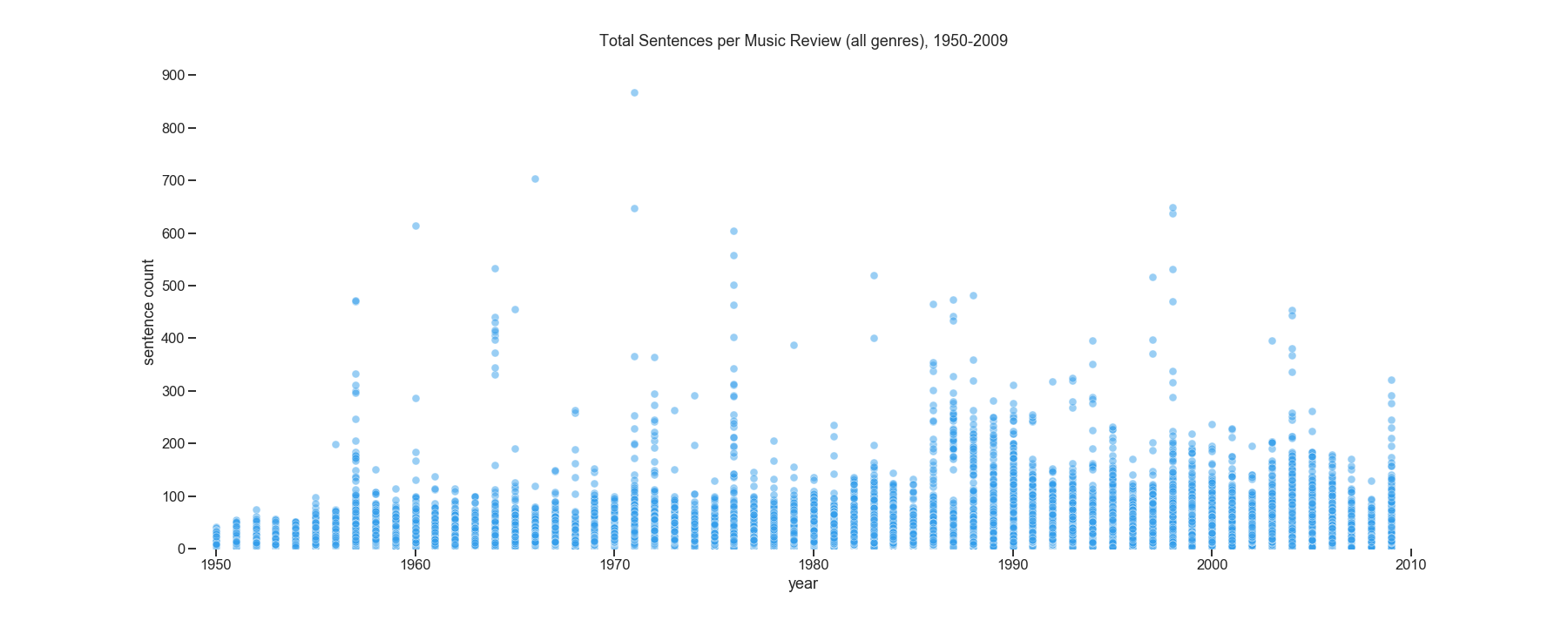
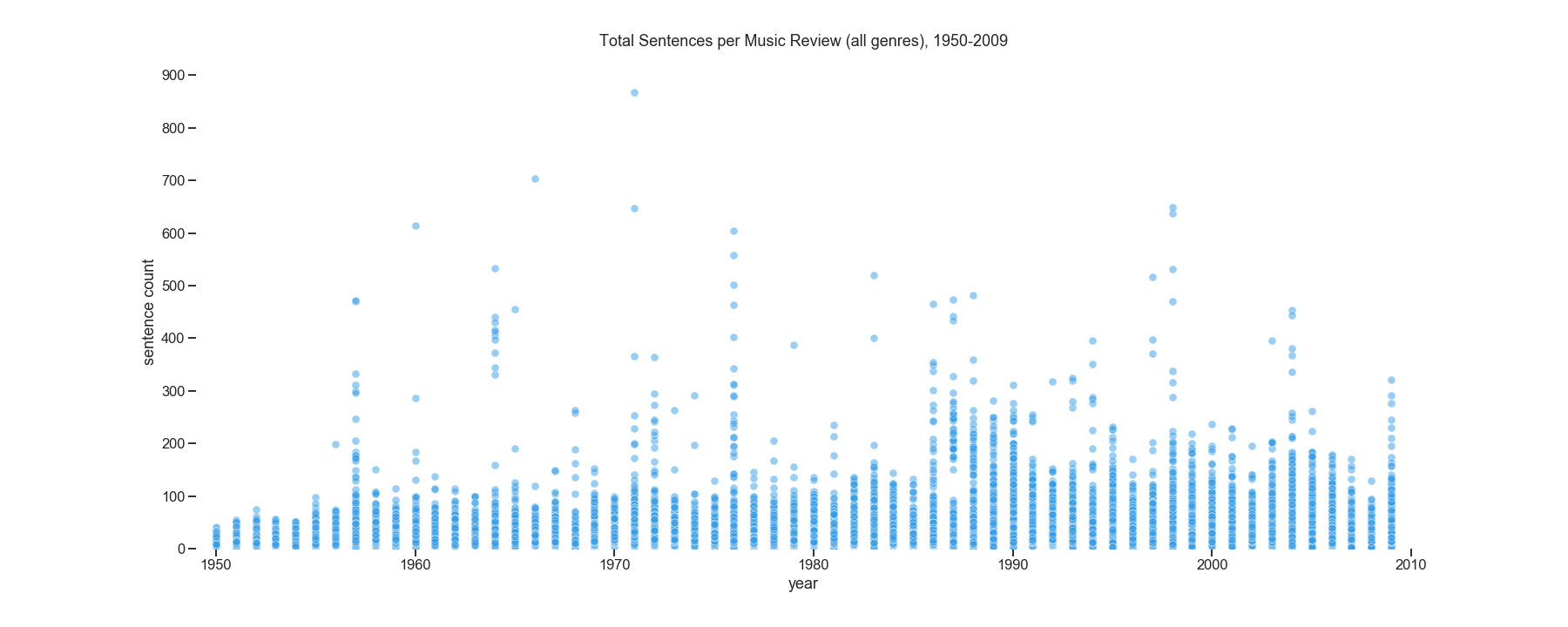
Figure 1: Scatter plot of the sentences per music review, with each circle representing one review, in articles from the ‘Review’ section of The Times written from 1950 through 2009. Reviews deemed ‘music’ reviews are reviews that include music-related terms from a manually-generated list.
For top-contributing authors to the entire corpus, I calculated the ten authors that contributed the greatest number of articles, the greatest number of total words across all their articles, and the greatest number of total sentences across all their articles. Hilary Finch, David Sinclair, and Richard Morrison are consistently among the top five contributing authors. While these authors do re-appear in the top-contributing authors for the sub-corpora of opera, jazz, rock, and rap reviews, the top contributing jazz reviewer is by far Clive Davis. The top contributing opera reviewers are Hilary Finch and Richard Morrison, and the top contributing rock and rap reviewer is by far David Sinclair.
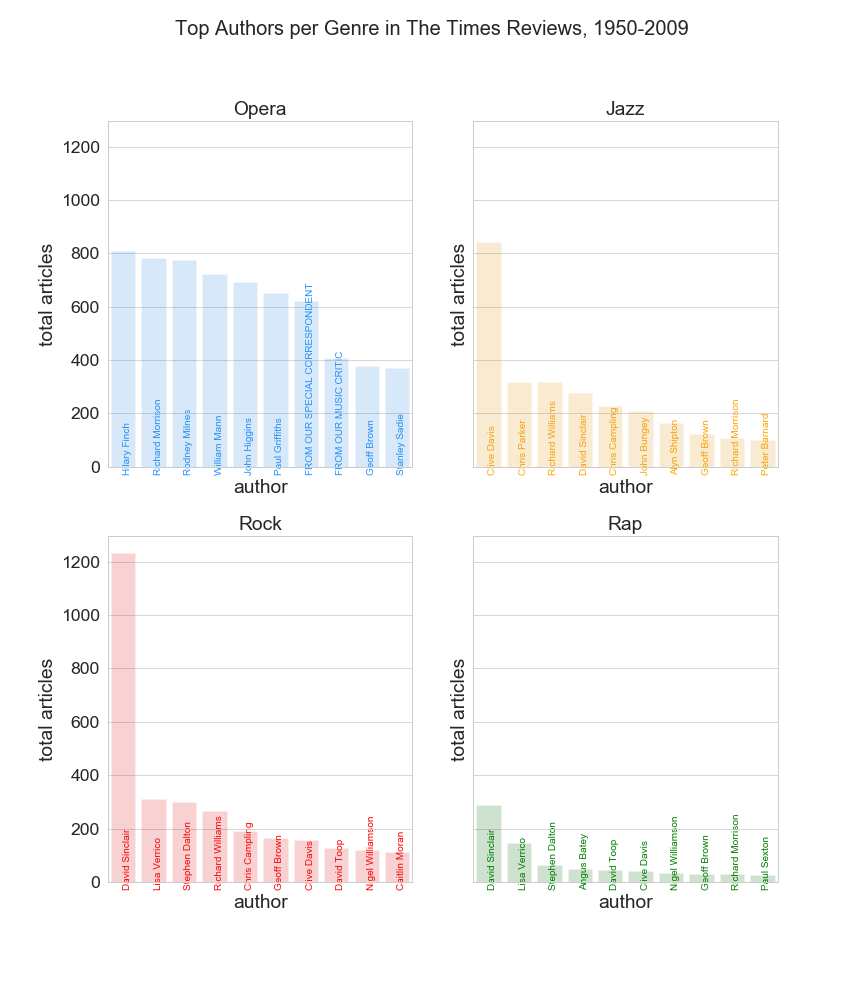
Figure 2: Bar charts of the total number of reviews written by the top-ten contributing authors, in terms of total music reviews written, for each genre (clockwise from top left: opera, jazz, rock, and rap)
Looking at reviews that include the four genres we’re focusing on, opera, jazz, rap, and rock; data analysis shows that opera reviews are by far greatest in number. The number of jazz and rock articles slowly gets closer to the number of opera articles as time passes from 1950 through 2009, with the number of rock articles just barely surpassing the number of opera articles one year. A quick observation of reviews’ lengths per genre indicates that the total word counts and sentence counts per review don’t differ greatly from one genre to another.
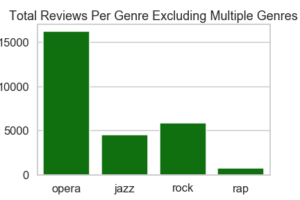
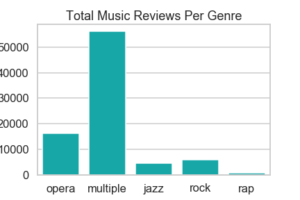
Figure 3: Bar charts of the total number of reviews in The Times from 1950 through 2009 that include the terms ‘opera,’ ‘jazz,’ ‘rock,’ and ‘rap.’ The left chart includes a ‘multiple’ bar for reviews that contain more than one of these terms in any combination. The right chart visualizes articles that contain only one genre term (either ‘opera,’ ‘jazz,’ ‘rock,’ or ‘rap’).
Sentiment Analysis
With 106,810 reviews in the entire corpus, I was asked to filter out reviews written prior to 1950, leaving 83,625 reviews written from 1950 through 2009. Next, I looked for reviews that contained one of four music genres: “opera” (18,628 reviews), “jazz” (7,681 reviews), “rap” (1,925 reviews), and “rock” (9,222 reviews), leaving 37,456 reviews in our corpus. (see the Data Preparation Jupyter Notebook). Using VADER, the Valence Aware Dictionary and sEntiment Reasoner, I analyzed the sentiment of each of these 37,356 reviews (see the Sentiment Analysis Jupyter Notebook).
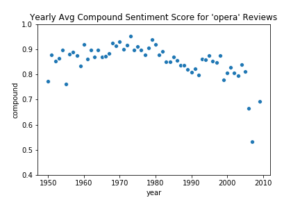
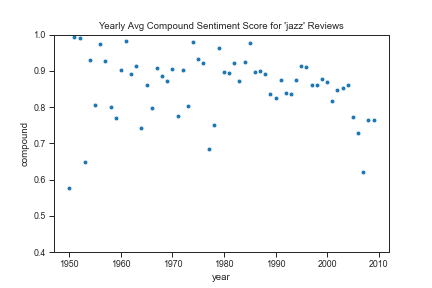
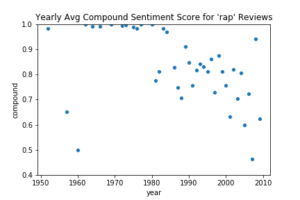
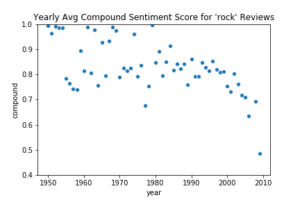
Figure 4: Scatterplots of the compound score VADER assigned reviews in the corpus of 37,356 reviews. Genres displayed clockwise from top left: opera, jazz, rock, and rap. According to VADER’s documentation, reviews scored 0.5 to 1 are considered to have an overall positive sentiment and reviews scored 0.4 to 0.5, to have an overall neutral sentiment. Comparison of VADER’s scores to manual scores indicates that the accuracy of the compound scores could be improved after data cleaning and customization of VADER’s lexicon.
To evaluate VADER’s performance, we manually scored the sentiment of 217 reviews. The 217 reviews include a randomly selected review from each genre for each year (note: reviews with the term “rap” weren’t published every year), as well as three reviews with the maximum VADER score for positive, neutral, and negative sentiment. While we need to do more analysis of our agreement scoring the sentiment of reviews, the differences in our scores look pretty small so far.
A comparison of our manual scores to VADER’s scores indicates that VADER picked up on the strong positive sentiments well. VADER considers scores between 0.5 and 1 to be positive, with 1 being maximally positive; reviews we manually scored as 5 (the most positive on our scale of 1-5) had VADER scores between 0.6956 and 0.999. However, VADER seems to miss many negative sentiments. VADER considers scores between -0.5 and -1 to be negative, with -1 being maximally negative; reviews we manually scored a 1 (most negative) had VADER scores between -0.7537 and 0.991. VADER scored the majority of the text of each review as having a neutral sentiment, which may be relatively accurate since many of the reviews we manually read were describing a musical work in addition to providing critique. (The code for this comparison of scores can be found in the Compare Scores Jupyter Notebook.)
Next Steps
Though this project will be taking a break for most of the summer, we’ve identified several steps we’ll take upon returning to the project. First, to try to improve the VADER sentiment analyzer’s performance on our corpus, we’ll improve the quality of the corpus itself. While manually reading reviews, I noted common digitization errors that I can fix using Regular Expressions (for those unfamiliar with the term, RegEx involves pattern matching and can be used in a similar way to the “Find and Replace” function in a Word document). As mentioned above, identifying reviews that are outliers in the corpus in regard to their length could help us locate files that need to be split into several reviews.
To further filter the corpus, I’ll also determine how many reviews we would have if we require each genre term (opera, jazz, rap, rock) to appear more than once in a review in order to be included in our corpus. Dave, Orian, and Mark will look at the top contributing authors to identify which people are known to write music reviews for the genres we’re focusing on in this project. If we have enough reviews from such authors, that would provide a way to create a corpus that we’re more confident contains the types of music reviews we’re aiming to analyze.
After making these improvements to the corpus, I’ll rerun the sentiment analyzer on the reviews and compare them once more to our manual scores. If there’s improvement, we can start analyzing how different genres are portrayed over time. If there’s not much improvement, we can tailor VADER to our corpus.
While manually scoring the sentiment of reviews, we recorded keywords and their sentiments that were influential in our scoring. I could add these words and their scores to the VADER lexicon, customizing its sentiment analyzer for our corpus (VADER was developed using Twitter as its main text source, so it’s not a perfect fit for historical language or for newspaper articles).
Of course, there are other sentiment analyzers we could try, as well as other text analysis approaches such as topic modeling! We’ll let you know how it goes in the upcoming academic year…

