
Status in January
The project is advancing very well and we have our first exciting results that we’d like to share. The results are very preliminary and any feedback is of course highly appreciated. Mirjam has worked very hard on these results and done an incredible job.
We are digitising birth records using scanned parish books from Austria. These scans are available to the general public on ‘Matricula Online’ (http://data.matricula-online.eu/en/), a platform that allows browsing collections from Austria and other European countries, such as Germany and Poland. For our pilot we asked our partners at Matricula for a set of scans of books covering baptisms from 7 parishes in the province of Lower Austria roughly spanning the period from 1870-1910. Some of these are located in urban areas, some are more rural, giving us a diverse sample of the births in these places. In total, our data delivery consists of 29 books with about 9,000 pages. Since it takes some time to process the scans in Transkribus (https://transkribus.eu/Transkribus/) we chose to focus on an initial small subsample of pages for a preliminary analysis. From each book, we randomly selected two pages to form our initial study sample of 58 pages.
Processing Steps for Text Recognition
Most of the actual work takes place on Transkribus, a software resulting from the H2020 e-Infrastructure Project READ (Recognition and Enrichment of Archival Documents). The scans are uploaded to a dedicated server, which then processes the pages. The process is controlled via the same tool used to upload the scans. Since the parish books record life events in table form, the first step is to apply a table template outlining the general structure of rows and columns. Transkribus then applies this template to a specified set of pages and extracts text from the cells outlined by the table. A sample of what the output looks like after this first step is shown in Figure 1 for a page from the parish Krems-St. Veit. Black lines indicate the table structure overlay and cyan-colored lines surround areas recognised by Transkribus as containing text.
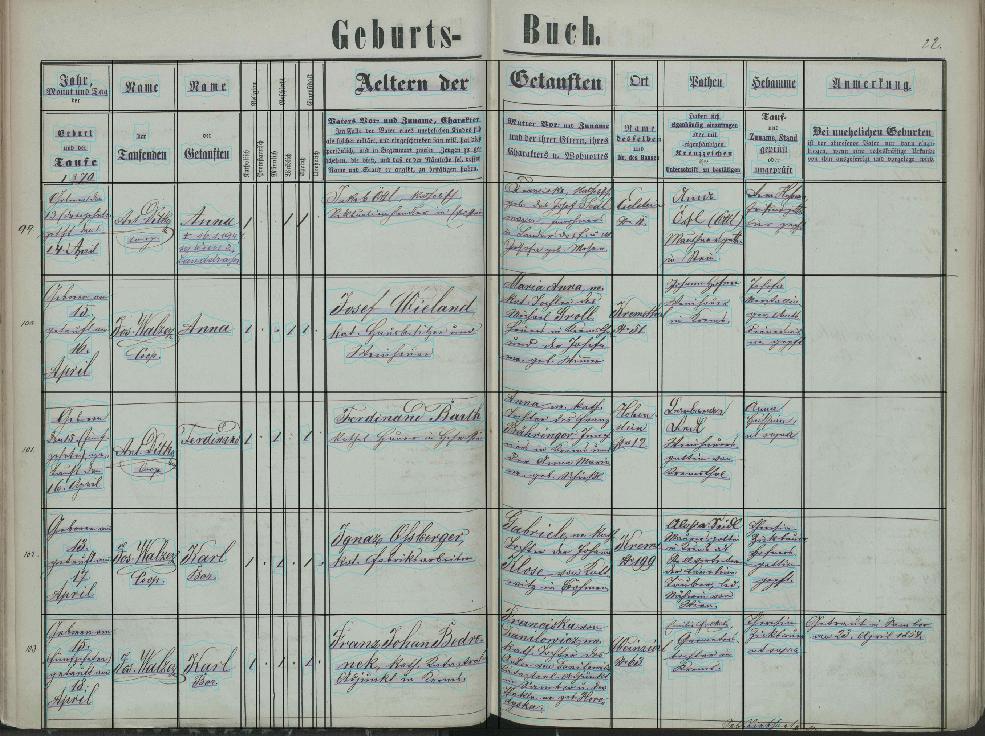
Figure 1: Sample page with text outline
The handwriting used by the priests is ‘Kurrent’ (German Script), which was in wide use at the time. One row corresponds to one baptism. The columns capture the date of the baptism and the birth, the name of the acting priest, the name of the child, several small columns with demographic information (gender, religion, in/out of wedlock), characteristics of the mother and father, place, name of the godparents and midwife, and other notes.
After Transkribus applies the table template and selects the areas containing text we can start its text recognition process. This takes around one minute per page using the ‘Kurrent M1’ model kindly provided to us by Dr Günter Mühlberger (University of Innsbruck). Once the recognition went through the result is exported to a spreadsheet containing rows and columns according to the table template with recognised text in the spreadsheet cells.
Manual Correction and a First Benchmark
Books from different parishes vary in how exactly the table is laid out and, for example, how large the middle section is. We have experimented with different methods to improve how Transkribus deals with tables. For example, instead of just applying one table template to all pages, one could specify a different template for each book, since some have more rows than others. To establish a benchmark against which we can compare different approaches we proceeded to manually correct the table layouts and text recognition for our set of 58 pages. This is a laborious process. Some priests write more legibly than others. Anyone who has ever tried to decipher a doctor’s handwritten note can relate. ‘Kurrent’ is also not taught in schools anymore and Mirjam had to undergo an online training course to be able to read the script.
This benchmark serves two purposes:
- It allows us to evaluate how much information is in theory available in the books. There are several reasons why we could never hope to recover some of the information, e.g. parents’ characteristics. For example, it happens occasionally that priests wrote information across column boundaries. With the current set of algorithms this information is lost since the table structure is strict. We respected this when doing the manual correction and did not include anything written across table boundaries. In some parishes there was also simply no information recorded on some dimensions.
- It allows us to compare different methods of automatic transcription against each other. For example, the table layout could be kept fixed throughout or allowed to vary by book. Since manually adjusting table layouts for each book is time intensive we would want to know how much there is to gain from it.
The first goal of this project is exploring the feasibility of using the parish books to count the number of births. This is straightforward manually since it is clearly visible from the scanned images how many rows are corresponding to a birth and how many rows are empty. Doing this automatically requires recognition of the table structure and not assigning any text to ‘empty’ rows. This could go wrong, for example, if priests always wrote across row boundaries.
Although it may seem unimportant at first to simply count the number of births there is already significant information in a simple count. Together with knowledge of which time period is covered by a parish book, the count allows the researcher to compare the geographical frequency of births in a selected time period. Combining this with census data on the number of residents in an area one could then estimate crude birth rates, which are economically interesting since they can reveal trends and changes in fertility behaviour.
Figure 2 shows how many rows we count in our sample for each of the parishes. Each row in the book corresponds to a baptism, which is following a live birth in most instances, but could also be a stillbirth. Despite some difficulties with recognition of the table structure, the fully automated count (discarding empty rows) matches the manual benchmark very well. This is encouraging as it means that Transkribus is very well able to match the specified table templates to the scanned book pages and text is mostly assigned to the correct rows. We also experimented with manually adjusting the table layout for each book but this didn’t achieve significant improvements. This is not surprising given how well the fully automatic process already works.
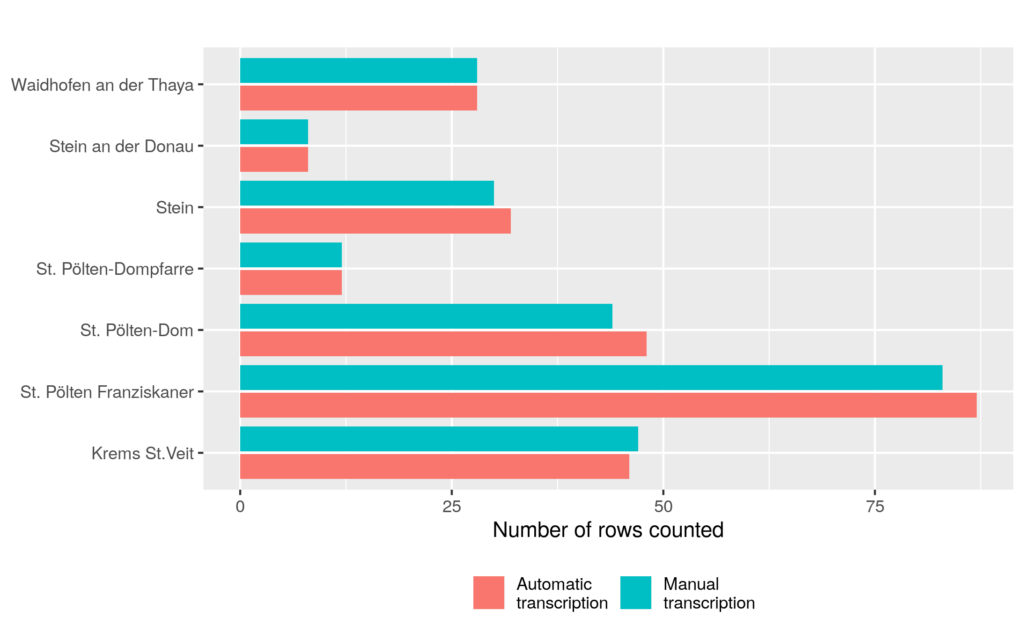
Figure 2: Number of recognised rows
Extracting Socio-Demographic Information
Encouraged by the success of how well the basic table structure was recognised we proceeded to the next step—extracting information on the baptised person from what the priests wrote down. The basic structure of the table theoretically allows to extract the following information if it was recorded by the priest:
- Date of birth and date of baptism
- Name of the priest
- Name of the child
- Gender, religion, and whether the birth was in or out of wedlock (narrow columns with ticks)
- Name, religion, occupation of the mother and father (one column for each parent)
- Place of baptism
- Name, occupation, and origin of godparents
- Name of midwife
We quickly realised that the three narrow columns indicating gender, religion and legitimacy were not reliably recognised by Transkribus. Minor offsets in table rotation meant that these columns were often shifted and overlapping. Our focus then turned to the name of the child, which we could easily match to a register of names and thus get the child’s gender. Secondly, given the importance of socio-economic class of the parents in the economic study of fertility, we wanted to explore the feasibility of extracting occupation of the father and mother (often the mother’s father’s occupation).
Browsing the spreadsheets generated by Transkribus we realised that full text recognition is not possible. The table structure with frequent line breaks and partially overlapping text means that the raw output is an assembly of word segments and individual letters. Even manual correction of the transcription does not completely solve this problem if information is contained in the wrong column since the priest ran out of space and thus wrote over table boundaries. We did not fix these types of mistakes manually to give us a benchmark for the best possible outcome we could hope for respecting the table structure.
Child’s Name
The easiest information to extract is probably the name of the child. We can compare the spreadsheet column containing names against a list of common names of the time. Doing this for both the manually corrected transcription and the automatic output gives us a first performance measure relevant for our main goal. Recognising the name also means obtaining the gender of the child, important information we couldn’t get automatically from the columns in the middle of the page.
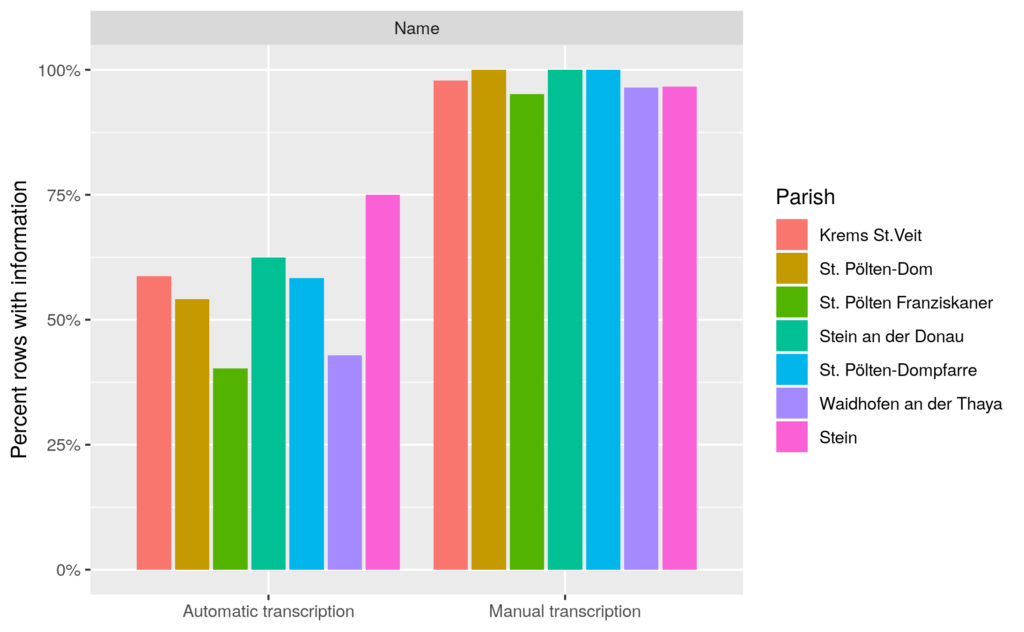
Figure 3: Percent of rows with names
Figure 3 shows a comparison of the percentage of rows containing names by parish using the manual and automatic transcription. The main difference between the two panels is that the manual version fixes the many variations of names encountered in the automatic version. For example, the most common name for a boy in Austria at the time was ‘Josef’. The corresponding column in the automatic version of the spreadsheet contains many variations of this name (‘Josepk’, ‘Jodef’, ‘Sosef’, ‘Joset’), which are not (yet) recognised as names when our script goes over cells looking for names.
The manual version does not always reach 100% since stillbirths are recorded without names (in 3 cases) and sometimes the name bled across columns (in 4 cases). One promising way forward for the automatic transcription is to improve the procedure looking for names, e.g. by allowing for one letter to be wrong. Of course this procedure could also be much more sophisticated and incorporate machine learning tools.
Parental Background
To extract information on parental background we proceeded in the same way as for names. We compiled a list of common occupations and place names of the time and wrote a script that goes over the relevant columns in the spreadsheet looking for matches. We adapted the list as we manually corrected the transcription to include some common variations of spelling (which we haven’t yet done for names). The result of this exercise is shown in Figure 4.
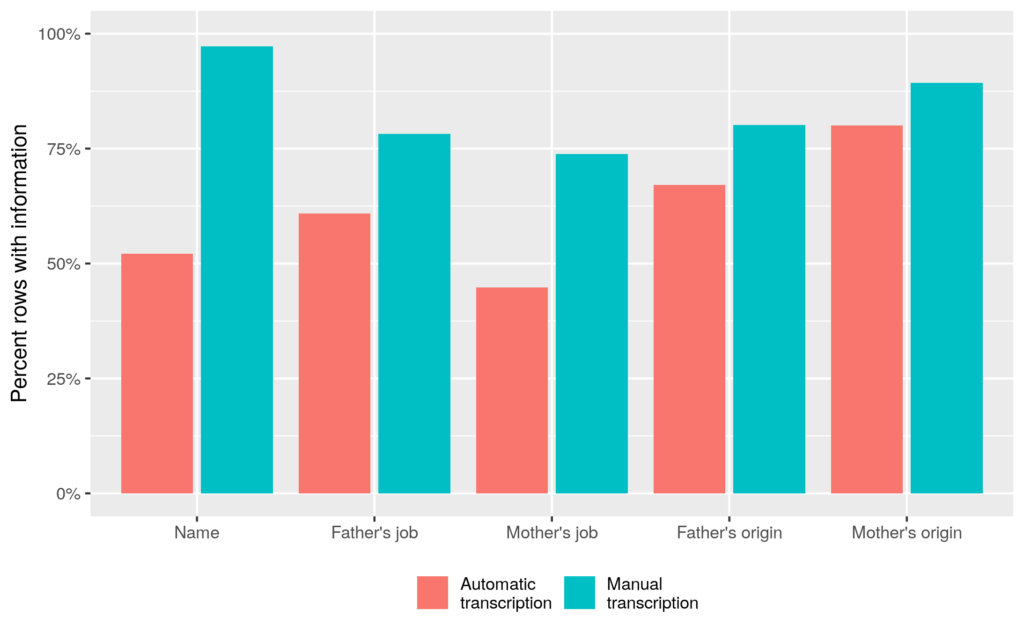
Figure 4: Information on parents
The first two bars summarise the information we can currently extract on the name of the child comparing automatic and manual transcription. The overall success rate for names using automatic transcription (which does not currently recognise misspelt names), is about 50%.
We were surprised how well we can extract occupations and places. Using our manually adjusted lists we can assign a job to about 75% of fathers in the manual transcription. Using the same list, we find an occupation for about 60% of rows in the automatic transcription. So about 80% of the manual transcription can be recovered automatically. The manual transcription does not reach 100% since priests did not record occupations in some parishes or wrote across table boundaries (which we always respected).
The success rate is slightly lower for mother’s job, which is actually often her father’s job. One reason for this could be that we have fewer of those jobs on our list.
As the last two sets of bars indicate we are also very well able to extract information on where the parents are from, again using a customised place list based on our manual transcription.
Summary and Outlook
At this stage it looks like the project is progressing very well. We have the first evidence that we can recover the number of baptisms by parish almost completely, using only automatic transcription of scanned images in Transkribus. Having manually corrected the transcription we have established a benchmark in which we were able to recover the child’s name in almost all cases and information on parent’s occupations and origins in about 75% of cases. The success of fully automatic transcription also seems reasonably high, 60% of jobs recognised simply by letting Transkribus do its work and using our lists.
One of our findings so far is that the lists are crucial. For every attribute we want to extract we need a list of which values it could take. This results from the fact that the full text of the books cannot be transcribed at this stage. We don’t yet know how to teach an algorithm to intelligently locate text in a table structure where some priests ran over the table boundaries on the page, unfortunately.
Compiling these lists, e.g. a list with names, places, and occupations, is still magnitudes less work than trying to do any manual transcription as soon as the number of pages is large. Our next steps are using lists for all the attributes we are looking at in our small sample of pages, improving the algorithm that compares text fragments against the lists, and then looking at the share of recoverable information in a larger set of pages.
(Base image is owned by Diözesenarchiv St. Pölten)


Recent comments