Technical difficulties encountered during development & Review
The limited computing power becomes a boundary to render our concept images and draw a large number of frames to create animation between mutated plants.
In fact, there are many solutions for running the program in a remote environment, such as Google Colab. I followed some tutorials to set up the Stable Diffusion on a remote computer, but the online unit’s storage had an error installing models from my Google Drive. I made it run the Stable Diffusion on a rented machine that has a powerful graphic card and successfully used it to upscale the sequence of one completed version of the video. It takes very much computing power to render 1800 frames from 512px resolution to 1024 px and draw extra details on each frame because the process of these images is to redraw every frame and make everything more intricate.
We have been enlightened by these practices in many ways.
Using reinforcement learning (RL) for Procedural Content Generation is a very recent proposition which is just beginning to be explored. The generation task is transformed into a Markov decision process (MDP), where a model is trained to iteratively select the action that would maximize expected future content quality.
Most style transfer methods and generative models for image, music and sound [6] can be applied to generate game content… Liapis et al. (2013) generated game maps based on the terrain sketches, and Serpa and Rodrigues (2019) generated art sprites from sketches drawn by human.
A range of engagement with AI tools and applications enables us to obtain some inspirations and key references to serve us in the development of our concept. They also help us in seeking visual elements to develop the design when we have little knowledge of the basic science of plants. Even if we know nothing about the nature of plants, we can quickly generate hundreds of images (and variants) of cacti, vines and underwater plants.
We can just use our imagination to blend together variants of plants that do not exist, given the established common sense of biology told by AI. For example, by adopting the basic attributes of an aquatic plant, fusing the characteristics of a coral colony with those of a tropical water plant, and adding some characteristics that receive the effects of environmental changes, a new plant is created.
By using functions from generators including Perlin noise, style transfer algorithms (NST) and feature pyramid transformer (FPT), we can quickly appropriate elements from different images and fabricate them together, for example, by imagining a giant tree-like plant, even though I am not a botanist. I can transform the organisation of the leaves, trunk and root parts of the tree. For example:
Change the leafy parts into twisting veins and vines like mycorrhizae.
Recreate the woody texture of the trunk into parts of another plant, making this plant into a mixture of multiple creations.
Then, place it in a body of contaminated land.














































After subjective selection and order, the plants’ images were matched to a certain context, and we created a process of variation between the plants’ different stages.
Ai models are engaged in the processes of generating ideas, forming concepts and drawing design prototypes with different degrees of input and output. I used a variety of tools in the design process, and the selection of materials was a time-consuming and active process that required human involvement and modulation. I also had to control many parameters in the process of generating the material to achieve the desired effect.
Prospect
In the future, if a set of interactive media were able to allow audiences to input their ideas to ai and generate animations in real-time through a reactive interface, a complete set of interactive systems would need to be built, and such a generative video-based program would require a great level of computing power.
Many problems that can be encountered in the process of txt2img and img2img generation in which the outcomes vary dramatically and lack proper correlation suggest that more detailed adjustments to the image model are needed to improve.
Because when an audience is in front of an AI model and tells it: “I want a mutant plant in a particular environment”, the AI model may not be able to understand the vague description. To be able to generate and continuously animate our conceptual mutant plants in real time would probably require not only a computer that powerful enough to draw hundreds of frames in seconds but also a model that trained for plants’ morphology accurately and was able to originate new forms itself.
Among the many contents in online forums and communities of Stable Diffusion, LoRA is a series of models with extensive training in generating characters and human models, which have been adapted and trained for many generations in different categories. In the future, there may be models trained on a variety of subjects and objects that may have important applications in the design and art fields.
reference:
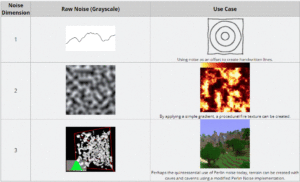
Adrian’s soapbox (no date) Understanding Perlin Noise. Available at: https://adrianb.io/2014/08/09/perlinnoise.html (Accessed: April 27, 2023).
Liu, J. et al. (2020) Deep Learning for Procedural Content Generation, arXiv.org. Available at: https://arxiv.org/abs/2010.04548 (Accessed: April 27, 2023).
Liu, J. et al. (2020) “Deep Learning for Procedural Content Generation,” Neural Computing and Applications, 33(1), pp. 19–37. Available at: https://doi.org/10.1007/s00521-020-05383-8.
Yan, X. (2023) “Multidimensional graphic art design method based on visual analysis technology in intelligent environment,” Journal of Electronic Imaging, 32(06). Available at: https://doi.org/10.1117/1.jei.32.6.062507.

