The general idea of machine learning is you take a set of data, train a model on it, and use this model to annotate new data. This could be to classify whether an image is of a cat or a dog, or to estimate the effect of changing a parameter in an experiment. In an abstracted version, you want to estimate the function values  at new locations
at new locations  , given knowledge of what the function has done at other locations
, given knowledge of what the function has done at other locations  . But what if you also know what the derivative of the function is at ?
. But what if you also know what the derivative of the function is at ?
When working with physical systems we often know something about the derivatives: running watches come with accelerometers, and their readings can be combined with GPS data to improve the accuracy of location estimates. Combining several sources of data in this way is particularly helpful when there are few data points, and one method which allows you to include samples of the derivatives is Gaussian processes. Their additional advantage is that they provide uncertainty estimates. A standard neural network will tell you what its best guess is; a Gaussian process will give you an estimated mean and standard deviation. Due to their computational complexity they are best suited to small data sets – the ones which have most to gain from adding derivative information.
Last year, I found myself needing to work with derivative samples when using Gaussian Processes. I found references to the theory in several places, and this helpful discussion on Stackexchange, but I missed a step-by-step introduction. This blog post is meant to be what I wish I had found. I hope it might also be useful to someone else.
What are Gaussian Processes?
Gaussian Processes are a machine learning method used for regression, i.e. to determine the value at a new location given a set of known values. It works by assuming that all of the values come from a joint Gaussian distribution. Using this assumption, a specification of the expected mean and an assumption on the covariance between points, we can estimate values for a new set of points. The figure below gives two examples of this – one slowly-varying and one faster. The orange line shows the true function which the blue dots have been sampled from. The blue line shows the mean of the Gaussian Process prediction, and the shaded area shows points within one standard deviation of that mean.
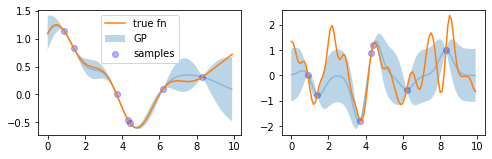
Two examples of Gaussian processes.
More technically, the blue areas and lines in the figure above have been calculated using equations 1. The first line states that the true function is assumed to come from a multivariate Gaussian distribution with mean  and covariance matrix
and covariance matrix  . The next two lines give expressions for calculating these.
. The next two lines give expressions for calculating these.  is the matrix of feature vectors for the sampled points, and
is the matrix of feature vectors for the sampled points, and  the same for the new points.
the same for the new points.  ,
,  and
and  are covariance matrices, calculated using a chosen covariance function
are covariance matrices, calculated using a chosen covariance function  [1]. is the covariance of the sampled points, the covariance of the new points and the covariance between these groups of points.
[1]. is the covariance of the sampled points, the covariance of the new points and the covariance between these groups of points.  is the standard deviation of the sampling noise,
is the standard deviation of the sampling noise,  the identity matrix and
the identity matrix and  the sampled values. For a thorough introduction to Gaussian Processes, see [1].
the sampled values. For a thorough introduction to Gaussian Processes, see [1].
(1) 
An example
As an example, let’s consider the case of Harvey who is spending a day hiking. He doesn’t carry technology with him while hiking, but likes to estimate his altitude profile to put in his journal. To do so, he stops a couple of times during his trip and uses his map and his surroundings to estimate his altitude at that point. The rest of the time he is too busy avoiding falling off cliffs and enjoying the landscape to pay attention to his altitude.
Hiker Harvey preparing for his trip.
In a Gaussian Process context we can consider this a regression problem where we are trying to estimate the altitude throughout the day based on point estimates or samples. Let’s assume we have samples of the altitude at the start and end of the day, and also after two and four hours of walking, as shown in the plot below. Let’s order these points chronologically and call them  ,
,  ,
,  and
and  .
.
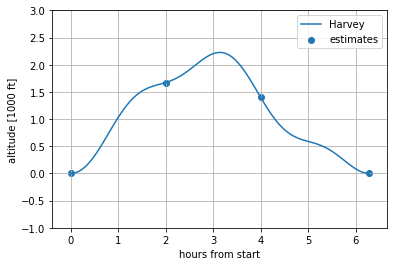
Plot of hiker Harvey’s altitude throughout the day, with samples indicated.
To model this with a Gaussian Process we need to specify a mean function and a covariance function. To keep this simple we will set the former to zero and use the version of the squared exponential kernel in equation 2 for the latter.
(2) 
Then, we need to compute the covariance matrices. This is done using the the covariance function, e.g.  .
.

The covariance function is similarly evaluated to obtain and . Plugging the numbers into equations 1 we obtain the estimate in the below figure.
Harvey’s altitude throughout the day together with the estimate based on the four indicated samples.
Now add derivatives
The above examples only use samples of the function. However, it is also possible to incorporate knowledge through samples of the derivatives[2]. Gaussian Processes work through specifications of the covariance between all points of interest. In particular, we need to know the covariance between all of our sample feature vectors, as well as between these and the location we’re interested in. If we want to include samples of the underlying process’ derivatives, we need a way of specifying the covariance between these derivative samples and the function samples. These covariances are the ones specified in equations 3 [1, p 191]. The first gives the covariance between two such samples of the derivative, and the second the covariance between a sample of the function and a sample of the derivative.
(3) 
 and
and  are two sample values and
are two sample values and  and
and  are the corresponding feature vectors. is the specified covariance function.
are the corresponding feature vectors. is the specified covariance function.  and
and  denote the value of the -th and
denote the value of the -th and  -th dimensions of the feature vectors.
-th dimensions of the feature vectors.
Continuing our example
So how does this work in practice? To illustrate, let’s imagine that Harvey not only estimated his altitude during his stops, but at the first one also estimated his vertical speed and acceleration. Accompanying code is available at https://github.com/sighellan/GP_derivatives_example.
Hiker Harvey on his way to the summit.
Our feature is the time  [3], and the function we’re estimating is hiker Harvey’s altitude. Then the derivative is his vertical speed and the second derivative his vertical acceleration. We continue to use the squared exponential kernel as earlier, see equation 2.
[3], and the function we’re estimating is hiker Harvey’s altitude. Then the derivative is his vertical speed and the second derivative his vertical acceleration. We continue to use the squared exponential kernel as earlier, see equation 2.
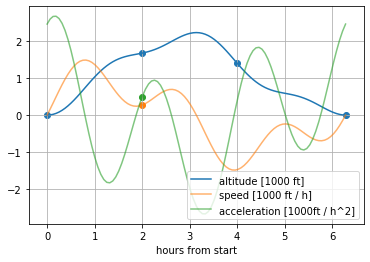
The altitude, vertical speed and vertical acceleration of hiker Harvey in our example, with samples indicated.
Since we are only using one feature dimension, we can drop some of the notation from equations 3, as given in equations 4.
(4) 
To show how to use these samples, let’s continue to denote the altitude samples , , , , in chronological order. In addition, we’ll denote the speed sample and the acceleration sample  . Then, what we need to do in order to calculate the covariance matrix
. Then, what we need to do in order to calculate the covariance matrix  is written out explicitly in the matrix below.
is written out explicitly in the matrix below.

We see that some of these, namely the ones that only involve pairs of , , , , are calculated directly using the covariance function, and that we’ve already used them in our previous version of the problem. Below, I’ve filled in the covariance matrix with these values.

Next, the covariances between , , , and can be filled in, e.g.  . Note that the jump between the second and third expression is only valid for our choice of covariance function. Filling in these yields
. Note that the jump between the second and third expression is only valid for our choice of covariance function. Filling in these yields

The above values could also be found in the Jacobian of the covariance function, and the covariances between , , , and as well as  can be found in the Hessian. The expressions are
can be found in the Hessian. The expressions are  and
and  . Using this, the matrix is now at
. Using this, the matrix is now at

The final three covariances needed are  ,
,  and
and  . Below, I’ve filled in those as well.
. Below, I’ve filled in those as well.

Similar methods can be used to compute  and . Having calculated these, the standard Gaussian Process equations 1 can be used to infer function values at new locations. I’ve plotted the result of this below.
and . Having calculated these, the standard Gaussian Process equations 1 can be used to infer function values at new locations. I’ve plotted the result of this below.
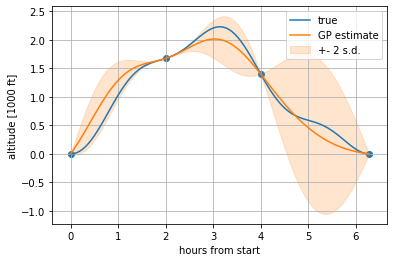
Estimated altitudes over the day.
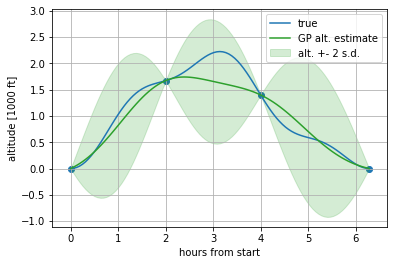
Now, the obvious question is whether the samples of the derivatives are helping. To evaluate this, we can compare this result to our earlier one, as shown in the plot below. The alternative estimate when only using samples , , and is given in green.
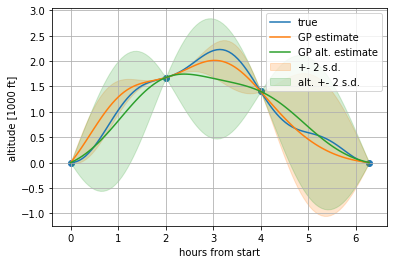
Comparison of estimated altitudes with samples of the derivatives (GP estimate in orange) and without samples of the derivatives (GP alt. estimate in green).
We can see that the orange line follows the blue line more closely than the green. Additionally, we can see the impact of the samples of the derivatives in the uncertainty of each estimate. The shaded areas give the estimate ± two standard deviations. This uncertainty of the estimate stays low around the two-hour mark, because the method not only knows the value at that time, but how Harvey was moving at the time as well. Further away from the derivative samples the effect disappears, as can be seen in the region between the four-hour and six-hour marks where the two estimates are similar.
In other cases, adding samples of the derivative can be used to force a point to be modelled a local maximum, and this is how I first encountered the concept. But as the example shows, the idea is much more general than that.
Footnotes
1. The covariance function expresses our assumptions on the form of the function. For instance, the squared exponential covariance function drops off radially with distance. Other choices could e.g. introduce a periodic structure. Several covariance functions are visualised here.
2. Assuming that the covariance function is differentiable.
3. By limiting ourselves to a single feature dimension we simplify the notation, but the concepts extend to multi-dimensional features.
References
[1] Rasmussen, C. E. and Williams, C. K. I. (2006) Gaussian Processes for Machine Learning. MIT Press.


Having read section 9.4 from Rasmussen and Williams, I really needed an example to see this in action and understand how it all worked, and this article gave precisely that. Thanks a bunch, a pretty useful article!
Hi Aniruddh, thank you, I’m so glad it was useful to you!