

The reward sharing scheme used in the current deployment of Cardano has some favourable properties that were analysed theoretically in an academic paper and through simulation experiments in our previous blog post. Specifically, we examined the reward scheme in terms of the level of decentralisation it induces and concluded that – when parametrised appropriately — the mechanism can yield satisfactory results in our simulation engine. However, it is possible that similar or completely different schemes could bring about equally good or even better outcomes. In this blog post, we examine some alternative reward schemes that have been proposed by members of the Cardano community (CIP-7, CIP-50). For each of these two schemes, we introduce its motivation and main differences from the one deployed, and then we run experiments to compare their performance.
We compare all three schemes given the same input distribution, namely a specially crafted synthetic initial stakeholder distribution which captures essential features of the currently live Cardano stakeholder distribution that we used in the final experiment of our previous blog post. Notably, the distribution involves 10,000 agents and hard codes specific stake values for several exceptionally large stakeholders (exchanges, etc.) with values drawn from the actual Cardano stakeholder distribution. Finally, we also mark almost a quarter of the total stake as inactive, to account for all stakeholders who do not use their stake to engage with the protocol. Given this distribution, we compare the results of the different experiments in terms of Nakamoto coefficient, i.e. the minimum number of independent stakeholders that collectively control the majority of the system’s active stake through their pools.
As a sidenote, we observe that the reduction or elimination of the min cost parameter is often mentioned as part of proposals to improve the reward sharing scheme in Cardano. We note that the min cost parameter is not part of the original reward sharing scheme (but was included in its implementation in Cardano apparently as an add-on security feature). We should emphasize that our results are for the original reward scheme without the min cost parameter.
Cardano reward scheme
As a reminder, in the reward scheme of Cardano, a pool with relative pledged stake 𝑠 and relative total stake 𝜎 earns rewards according to the following formula, as described in the Cardano documentation:
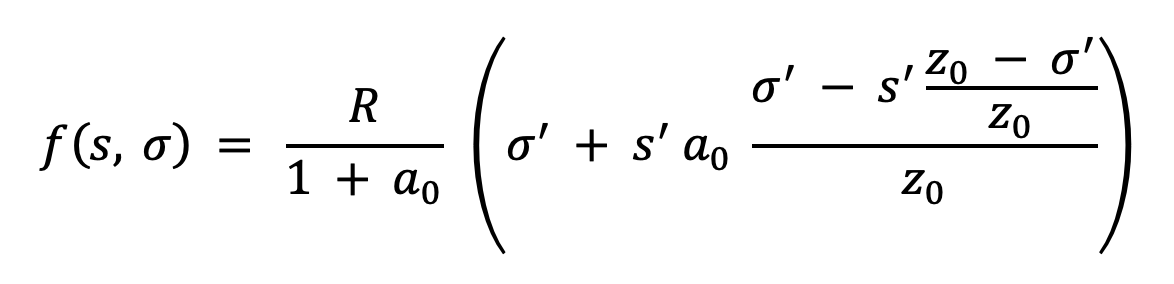
where R are the total available rewards for this epoch, 𝑎₀ is the pledge influence factor (currently at 0.3), 𝑧₀ = 1/𝑘 the relative pool saturation size (currently at 0.2%) and 𝑠′=min(𝑠, 𝑧₀) and 𝜎′=min(𝜎, 𝑧₀) are the relative pledge and total stake of the pool, but capped at 𝑧₀.
The purpose of the saturation factor 𝑧₀ is to prevent the formation of very large pools, while the pledge influence factor 𝛼₀ acts as a discouragement to large stake operators from splitting their stake across multiple pools. It is worth noting that pool splitting can hurt the Nakamoto coefficient as potentially fewer entities will be needed to control the majority of the stake. As we have described in our previous blog post, the reward scheme behaves well in our simulation engine, yielding a high Nakamoto coefficient even when the stake distribution is far from uniform.
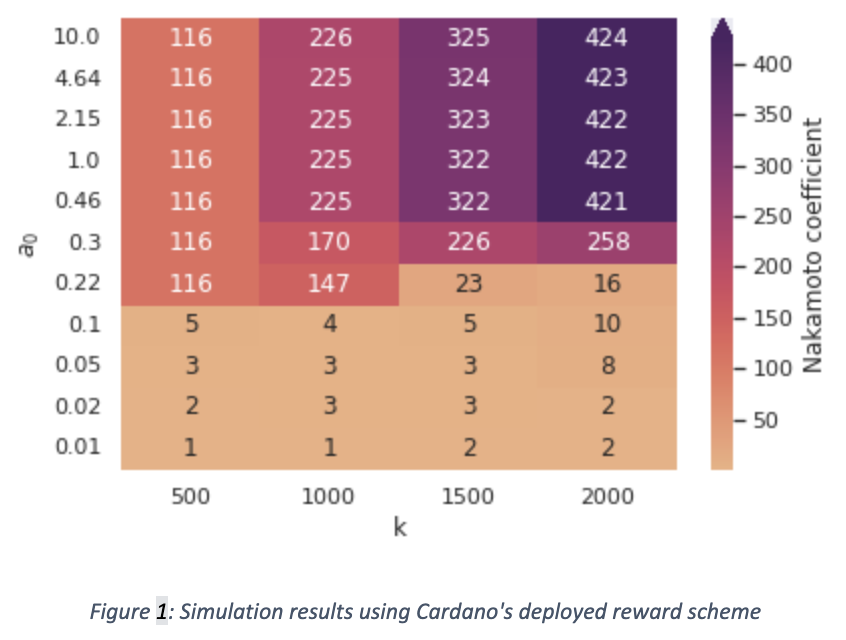
The heatmap above extends our results from the previous blog post, incorporating executions with additional values of 𝑘 and 𝑎₀, using the synthetic stake distribution. We observe once again the importance of the 𝑎₀ parameter.
CIP-7
A proposal that gained a lot of traction within the Cardano community is CIP-7, which aimed to boost the significance of small increases in a pool’s pledge with respect to the rewards it receives, while at the same time diminishing the incentives for operating private pools. The proposal introduced two new parameters: the curve root, which we denote as 𝜌, and the crossover factor, which we denote as 𝛾.
Under this proposed scheme, the rewards of a pool with relative pledged stake 𝑠 and relative total stake 𝜎 are given by the following formula:
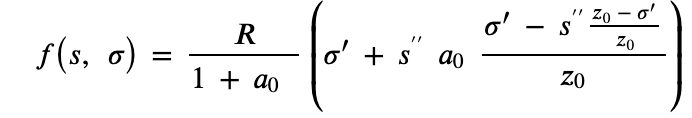
where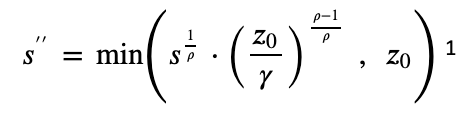
[1] Note that the proposal does not explicitly cap the pledge benefit at z₀, but we interpreted it as an omission and not another adjustment.
The difference from the deployed scheme is that the pledge benefit factor of the rewards is not linear to a pool’s pledge but instead follows a ρ-curve. To examine the effects of this reward scheme on the decentralisation of the system, we run a set of experiments for different values of 𝑘 and 𝛼 using the synthetic initial stake distribution that we described above.
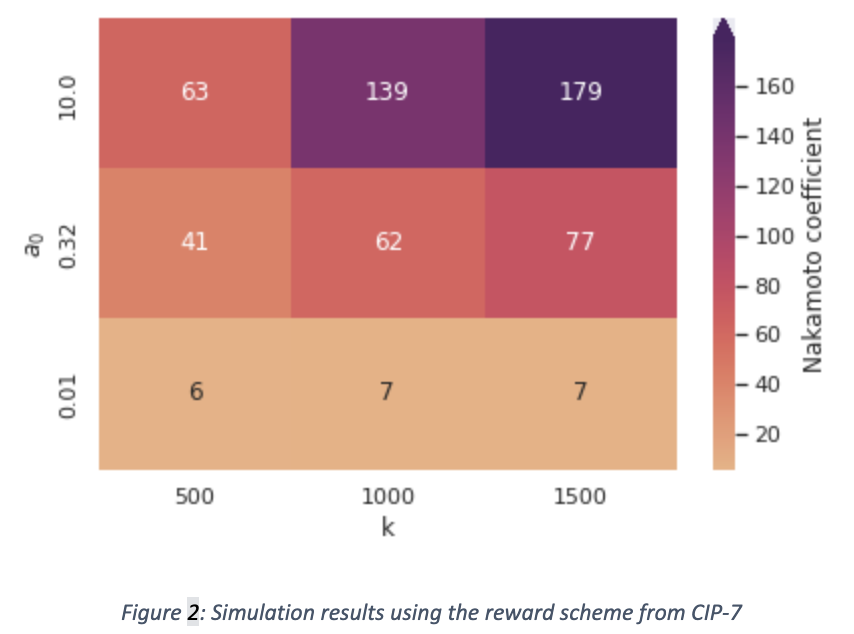 We observe the same trends as before (low 𝛼 not being a sufficient deterrent of pool splitting and decentralisation growing with 𝑘 for sufficiently high values of 𝛼), but this time the Nakamoto coefficient does not reach values as high as the ones we saw in the previous heatmap (for example, for 𝑘=1500) the highest value reached is 179, while before it was 325). We can interpret this increase in pool splitting as a direct consequence of the weakened incentive for richer stakeholders to concentrate pledge into a single pool which stems from the pledge benefit function being concave.
We observe the same trends as before (low 𝛼 not being a sufficient deterrent of pool splitting and decentralisation growing with 𝑘 for sufficiently high values of 𝛼), but this time the Nakamoto coefficient does not reach values as high as the ones we saw in the previous heatmap (for example, for 𝑘=1500) the highest value reached is 179, while before it was 325). We can interpret this increase in pool splitting as a direct consequence of the weakened incentive for richer stakeholders to concentrate pledge into a single pool which stems from the pledge benefit function being concave.
CIP-50
In a more recent proposal, the rewards formula was modified by removing the pledge influence factor 𝛼₀ and adding another parameter termed “pledge leverage 𝐿”, which takes values between 1 and 10,000. Specifically, this time the rewards of a pool with relative pledged stake 𝑠 and relative total stake 𝜎 are given by the following formula:
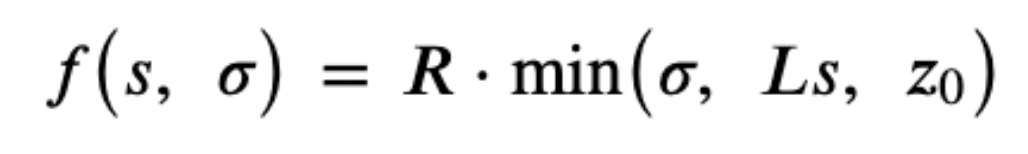
This way, each pool can have its own saturation point, which depends on its pledge, so pools with low pledge cannot grow as much as pools with high pledge, but they are given the same rewards per unit of stake. An important consideration behind this reward scheme seems to have been the improvement of the system’s egalitarianism, i.e. to give the opportunity to smaller stakeholders to earn as much value for their money as the biggest stakeholders. The proposal also makes claims about improving decentralisation, which we put to test through simulations.
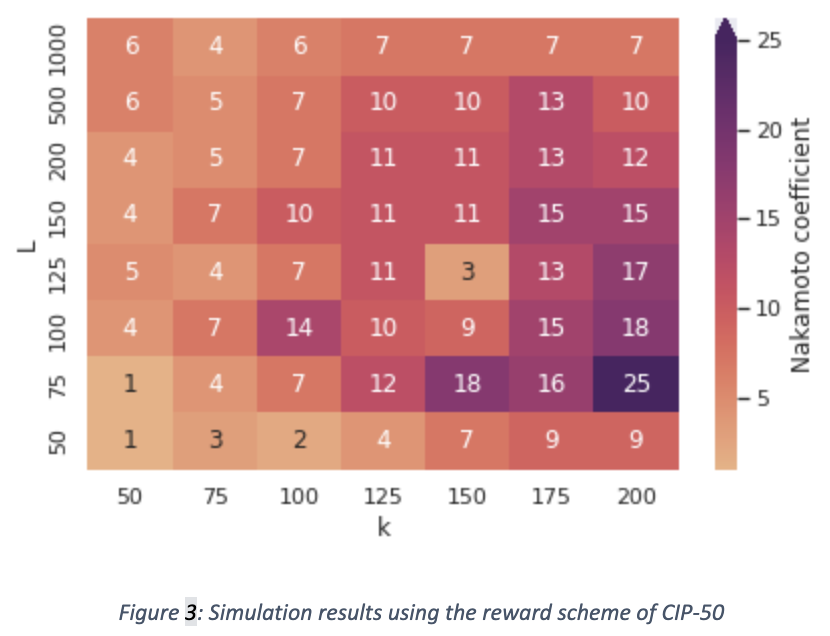
In the heatmap above, we can see the Nakamoto coefficient of the system at equilibrium for simulations that use the synthetic stake distribution and different values of 𝑘 and 𝐿. Note that we used lower values for 𝑘 this time because the author of the proposal suggests lowering the value of 𝑘, but we ran additional experiments with higher 𝑘 values, which yielded similar results (for example for 𝑘=1000 the highest Nakamoto coefficient we got in the simulations was 44, much lower than the corresponding ones from the previous two reward schemes).
We observe that this reward scheme does not perform as well as the other two in our experimental setup. The main issue we identify in this approach is that it sets an upper bound on the stake that a pool operator is incentivised to pledge to their pool, or at least lowers that bound, potentially by a lot, if we consider the bound set by the deployed reward scheme to be 𝑧₀. This means that more stakeholders potentially have an incentive to operate multiple pools.
Specifically, for the stakeholders that have some stake 𝑠 so that their saturation point is still determined by 𝑧₀ (𝐿⋅𝑠 > 𝑧₀), they have no incentive to pledge their stake to one pool. They only have incentive to pledge up to 𝑠′ < 𝑠 for which it holds 𝐿𝑠′ = 𝑧₀, so that their pool can gain the maximum delegations and rewards, but the remaining 𝑠 − 𝑠′ would gain no additional rewards in the first pool, so they could utilise it by opening more pools (note that this does not apply only to whales but to many more stakeholders, the specific number of which depends on the value of 𝐿). Decreasing 𝑘 so that 𝑧₀ is increased and there are fewer stakeholders for whom it holds that 𝐿⋅𝑠 > 𝑧₀ might be seen as a solution to this problem (and is partly why we examined cases with lower values of 𝑘), but this would exacerbate the disparity of growth potential between pools of smaller and larger stakeholders that is caused by the 𝐿 parameter (this issue has also been discussed in an older blog post in the section Delegative bimodal with pledge-based capped rewards).
To give an example of the problem we described above, let us examine a hypothetical scenario for the case where 𝑘=100 (hence 𝑧₀=1/100) and 𝐿 = 100.
A stakeholder who owns 1/1000 of the total stake could use their stake to either operate one pool with a pledge of 1/1000 which would get saturated at 1/100 (because of 𝑧₀) or they could operate 10 pools, each having a pledge of 1/10,000 which would also get saturated at 1/100. Even if we assume that there is no cost benefit from economies of scale, the additional rewards that the operator would receive because of the profit margin are enough to incentivise them to operate multiple pools in this scenario. Our simulations illustrate this point experimentally.
Furthermore, this scheme mandates an upper bound for the total pledge of the system, since from a point on no additional pledge is rewarded. For example, if 𝐿 = 100, then the total pledge of the system could never be more than 1% of the total stake and for a higher 𝐿 the bound gets lowered even more. In contrast, in the current reward scheme of Cardano there is no such upper bound for the total pledge; the more the total pledge of the system the more the rewards are issued.
One might say that these issues can be avoided if the 𝐿 parameter has a low value; however, this would mean that the pools of smaller stakeholders have a lot less growth potential compared to the larger ones, which effectively increases the barriers to entry for pooling (note that having 𝐿=1 is equivalent to not having on-chain pooling at all). We also observe this in the simulation, where for 𝐿=50 the Nakamoto coefficient is always lower than for 𝐿=100 because richer stakeholders end up accumulating more power.
Key takeaway
The proposals we examined focused on changing the impact that a pool’s pledge has on the rewards it receives. These reward schemes may achieve some valuable results (e.g. providing higher rewards per unit of stake to small pools) but when viewed under the lens of decentralisation none of them appears to perform as well as the deployed reward scheme of Cardano in terms of the resulting equilibria. Specifically, given the exact same initial stakeholder distribution in our simulation engine, the reward scheme of Cardano yielded significantly higher Nakamoto coefficient than the two proposals, when suitably parametrised.
However, it should still be noted, that real world play in such systems is still appreciably more complex compared to what our simulation engine assumes. We will be releasing the source code of our simulation engine with an upcoming blog post so all interested parties can experiment with it individually and/or extend it to cover richer strategy spaces which, without doubt, will continue to improve our understanding of these mechanisms.
by Christina Ovezik & Aggelos Kiayias Posted 21 July, 2022


Thanks for evaluating CIP7 and CIP50.
I appreciate the thoroughness and the time taken to evaluate these alternative reward schemes.
I look forward to the release of the simulation engine as it will hopefully lead to improved community proposals in the future.
Your evaluation of the CIP7 and CIP50 rewarding systems is impeccable.
I really appreciate the pain you took to explain these two rewarding systems. You explained these both concepts in a very detailed manner which is awesome. I hope these reward systems will be implemented.
My question is ” Only these two reward systems exist? or there are more to come?”