

The ability to notify effectively and expediently people that were in close contact with someone diagnosed with Covid-19 is an indispensable tool now that we gradually move towards easing the lockdown caused by the pandemic. As we have described in a previous post, technology can help and there are already a number of proposals that are under development, with some of them already deployed or in testing phase, including the NHS contact tracing app.
The issue of design and deployment of such apps has proven to be controversial due to the fact that contact tracing, by definition, shares personally identifiable information. And while no-one objects to sharing information to combat the disease (which is in fact a legal obligation), concerns have been raised regarding the potential privacy risks due to hacking, or even the repurposing of the data that people share via the app due to “mission-creep.”
So what are the data that are relevant to contact tracing? As we go about our daily lives, you can think of all the people that you come in contact with and record them in the form of a “contact graph.” A contact graph is a diagram such as the one below that illustrates over a period of time the individuals that a person, say Alice, has come in close proximity with, sufficient to expose them to the disease had she been a carrier at the moment of contact.
For the sake of an example consider two particular individuals, Alice and Charlie and their contact graphs for a particular time window.
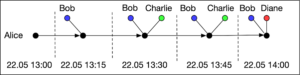
In Alice’s graph, we observe that in a period of time spanning 1 hour, she was in contact with three different people. Every person appears as a separate node in the graph labeled by their name. For the sake of exposition, time is divided in 15 minute windows.
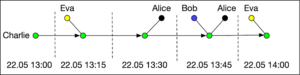
Charlie’s graph shows similarly his close contacts in the same period. What we observe is that the two graphs reveal a possibly significant interaction between Alice and Charlie. If, say, Alice is diagnosed with Covid-19, it would be important that Charlie is notified that he has been exposed to the disease and that he should self-isolate to avoid infecting others.
Contact-tracing attempts to perform the above notification by allowing in some way the reconstruction of the intersection between the contact graphs of different individuals. Moreover, contact-tracing via an app running on everyone’s phone has the potential to allow the reconstruction of the contact graph for contacts that someone does not even know by name, for instance, people that Charlie chatted at the park, or was seated next to in the bus.
From a privacy perspective it is clear that contact graphs can potentially reveal a lot about a person. Who are their main companions, what is their daily routine, who are the people that they regularly meet. Even from the small segments of the two contact graphs shown above, one can form plausible hypotheses about what Alice and Charlie were doing.
To address this consideration, two distinct approaches have emerged in the design of contact tracing apps. The first one is the so-called centralised, a good example of which is the NHS app. The app encrypts the identity of the device’s owner and broadcasts it to phones in close proximity. Every phone listens and records these encryptions. When someone is diagnosed, the log of all these ciphertexts is shared with the health authorities together with other suitable cryptographic information which makes it possible to decrypt the information stored. Going back to our running example, for Alice, her log takes the following form.
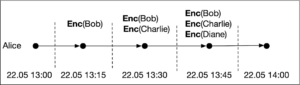
Note that Enc(.) would denote the encryption functions used by Alice’s contacts to encrypt their details. When Alice is diagnosed she uploads the log to the authorities’ servers and her contact graph can be recovered by decrypting all the stored information. Immediately after, it is possible for the central system to notify Alice’s contacts as necessary, including Charlie.
The decentralised approach, which is promoted by Apple and Google, has a different take in the manner that Alice’s contacts should be notified. In a nutshell it works as follows. Alice’s phone has a master key that enables it to create short lived identifiers (called also ephemeral identities, “EId”’s or beacons) and broadcast them to phones in close proximity. As a result every phone keeps a log that contains all such beacons received. In our running example, Charlie’s phone will contain the following log.
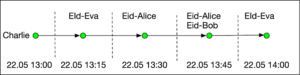
In case Alice is diagnosed with Covid-19, she can upload her master key (or suitable information derived from it) to the health authority’s server. Charlie’s phone, which regularly checks the server for updates, can download the cryptographic material that makes it possible to reconstruct Alice’s beacons. Charlie’s phone will run them locally against the log and discover a match, which will result in a notification.
What is fundamentally different between the two approaches is the role of the authority; in the centralised approach, the authority learns the contact graph and actively pursues the notification of Alice’s close contacts. In the decentralised approach, the authority is passive: it facilitates the provision of information that allows the notification to take place, but it may even be oblivious to whether anyone was actually notified by the app, at least up to the moment that those individuals call in for support and advice out of their own volition. Moreover, even if Alice consents to share as much information as possible, the identities of her contacts remain hidden to the authorities.
The main threat to privacy in the centralised approach is of course the fact that the authority’s database and decryption capability is a “single point of failure” and can become a prime target for cyber attacks aiming to obtain information about people’s whereabouts. Nevertheless, the decentralised approach is not spared from privacy problems either. For instance, depending on the deployment details, it may be possible to surreptitiously disperse multiple stationary devices which capture app transmissions and can reconstruct diagnosed individuals’ location data.
Dismissing the above issues and the perception of the public regarding the potential threat to privacy can be a serious disadvantage since the success of a contact tracing app fundamentally relies on its widespread adoption. It has been analysed that a minimum of around 60% of the population should use it, if it is to be effective as a way to control the spread of Covid-19. If people are afraid to use the app, (but also if the app does not work well), people will remove it and its advantage will be moot.
Correcting such privacy issues in the decentralised approach is possible; but it is technically involved. In the mean-time, the centralised approach is appealing as it empowers health authorities far more than the decentralised approach to provide care at the moment of notification and can be privacy preserving, but only under the assumption that the authority remains unhacked and true to purpose. It is to be expected that citizens of different countries will have different levels of trust to their public health systems and may opt for different approaches; this can complicate interoperability between national contact tracing systems which would be quite important if we are to allow international travel for business and holidays before a vaccine becomes widely available. Finally, companies like Google and Apple are understandably hesitant to facilitate personally identifiable information leak out of smartphone devices and this puts further hurdles in the available app deployment options and user uptake.
In the end, like in many other cases during this pandemic, there is no easy answer. But cyber contact tracing, decentralised or not, is technically feasible and can be eminently useful. Let us execute it well for the benefit of us all.
by Prof. Aggelos Kiayias Posted 26 May, 2020


A great piece that sheds much needed light on some of the great theoretical/ideological debates in the contemporary crypto space. At CleanApp Foundation, we appreciate the emphasis on pragmatism, and emphasis on Blockchain/DTL/Crypto projects that offer real social utility. Looking forward to engaging more with your crew!