Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
In our project, the first part (Prologue) and the second part (Blur) are presented as videos. To ensure a smooth experience for the audience, we decided to make the soundtrack directly for videos.
The sound design focuses on glitch sounds to reflect the distortion in memories of Alzheimer’s patients and the visually distorted elements. No music was added to the video’s sound design, only sound effects were used, with tonal sound effects tuned to the same key as the music to ensure harmony. To make some difference to the first part where the voice is tightly synced with visuals[1], the second part includes a poem read freely, generated by ChatGPT[2] and voiced via a TTS model, creating a complementary blend with the edgy glitch sounds as well.
In this project, music serves as an element for shaping the atmosphere of the scene. I designed a continuously played generative music, primarily using Ableton Live, along with plugins from Max for Live, and used Max/MSP to control transitions between musical sections.
Initial Idea
During the initial background research for the project, I discovered that stories of Alzheimer’s disease evoked a persistent, underlying pain in me. Like the gradual distortion of a patient’s memory, it is a slowly worsening process that affects the patients and also causes deep-seated pain in their loved ones. Therefore, I wanted to create an ambient music piece that is slow, steady, and subtly sad, conveying the feeling of slowly telling a story. In seeking inspiration, I found that the slightly detuned piano was perfect for conveying this mood. When one hears this sound, it evokes the image of an aged person, sitting in front of an old piano at home, gently recounting memories through playing piano. Based on this, I composed a four-bar chord progression as the foundation of the piece and created the following demo to establish the overall mood of the music.
Further Arrangement
Initially, we planned to create separate musical pieces for each of the four sections of the project, each advancing progressively. However, for better coherence and to enhance production efficiency, we decided to develop a single piece of music throughout.
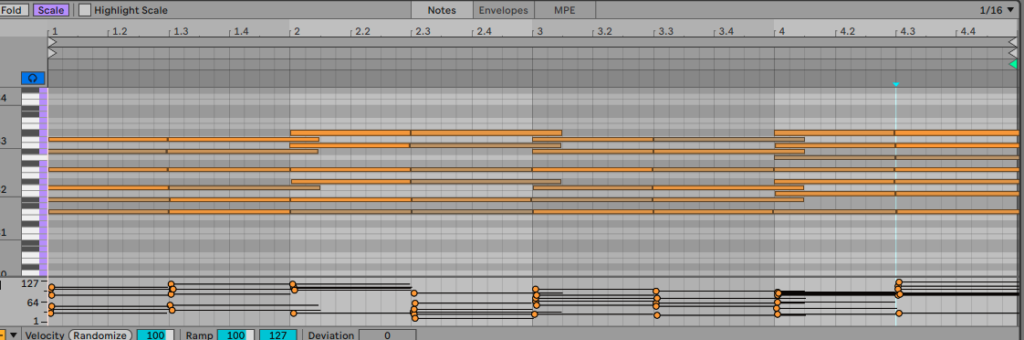
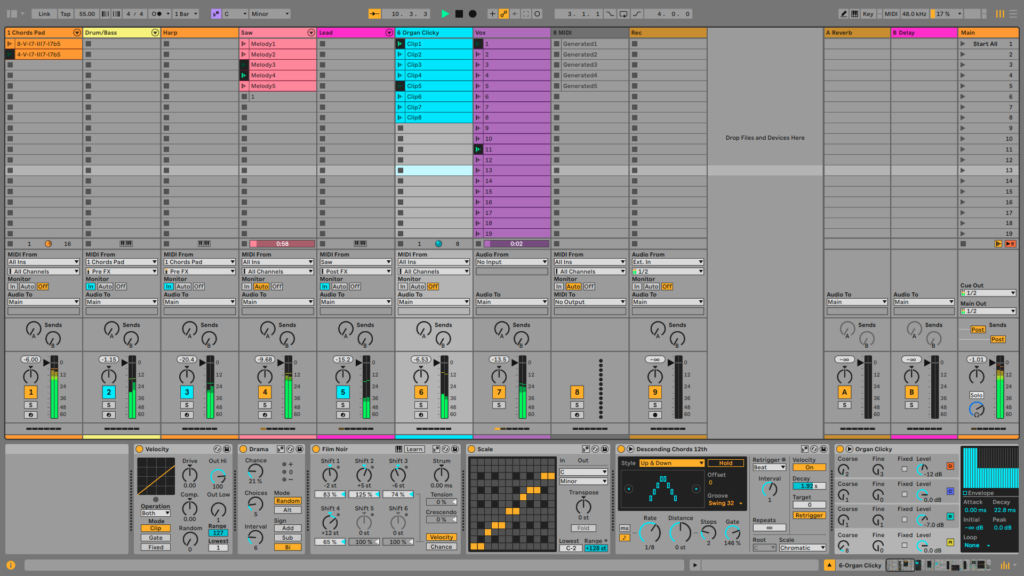
Creating a track that plays continuously for at least eight minutes requires continuous development and variation. Therefore, I expanded on the initial demo by adding more instruments and extensively using Max for Live MIDI Effects on each part. Thus the music, based on a stable chord progression loop, randomly presents some melodies, rhythms, and effects.
Chord Progression
For the random melodies, I used an AI text-to-music model to generate some musical fragments[1], selected those that fit our project’s atmosphere, and converted these audio files into MIDI Files to further generate melodies using these plugins.
Device Rack for Melody TrackOriginal Melody Clips
Utilize AI-Generated Voice
This project aims to evoke the emotions of its audience, and in the creation of the audio, I found that the human voice is particularly effective in conveying emotions. Additionally, voice is a crucial element in topics related to memory[2]. Therefore, I decided to incorporate this element into the music. The process of generating the voice is described in more detail in this blog[3].
During production, I first arranged these audio clips in the Session view of Live.
Voice Clips
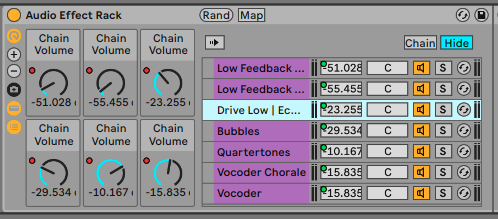
Afterwards, I created several effect chains and controlled the volume of each chain using the Macro knobs in Live.
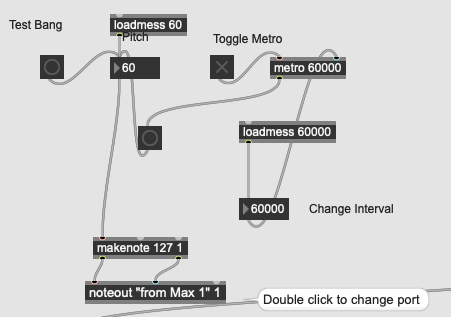
Audio Effect Rack with Rand ButtonMax Patcher for Sending MIDI to Trigger Randomize
In Live, there is a “Randomize” button that randomly changes the values of each knob within a rack, effectively altering the volume of each effect chain. These chains combine to add rich variations to the voice. To maintain ongoing variation in this section, I set up a Max Patcher using metro and noteout to send timed MIDI signals from Max. This triggers the “Randomize” button in Live at regular intervals.
After completing all the musical content, I noticed an issue: while every part of the music was continuously changing, the overall piece was too uniform with all parts playing simultaneously. Therefore, I restructured the music to vary the sections as follows, allowing each instrument to alternate in taking prominence.
I controlled the faders in Live for each part via MIDI CC signals linked to fader movements in Max. I also set up Max to change the fader values every 8 bars, allowing the music to transition smoothly into the next section.
Voice is an important part of memory, especially including the emotions of the speaker. It helps people recall memories of their loved ones. When using TTS models, we find that at the current level of development, AI-generated audio can already capture the emotions contained in the voice very well. This is also why we decided to use AI-generated voice. Below are some research topics about AI, voice, and memory.
The relationship between human voice and memory is profound, serving as a crucial element in both preserving personal histories and evoking emotional responses. Studies and projects, such as those explored by the Oral History Society and in digital archives like Voice Gems, illustrate the emotional and historical significance of recorded voices. They underline how voices not only act as a personal echo from the past but also as an emotional trigger that can bring memories vividly back to life.
Scientific research supports this emotional connection. Studies on recognition memory for voices highlight that the human voice can act as a powerful memory cue, influencing how memories are encoded and recalled. These findings are crucial for understanding how auditory elements of memories affect our recall and emotional responses. This interplay between voice and memory is not only significant for personal reminiscence but also plays a vital role in creative expressions, where voice recordings are used to create impactful art and preserve cultural heritage.
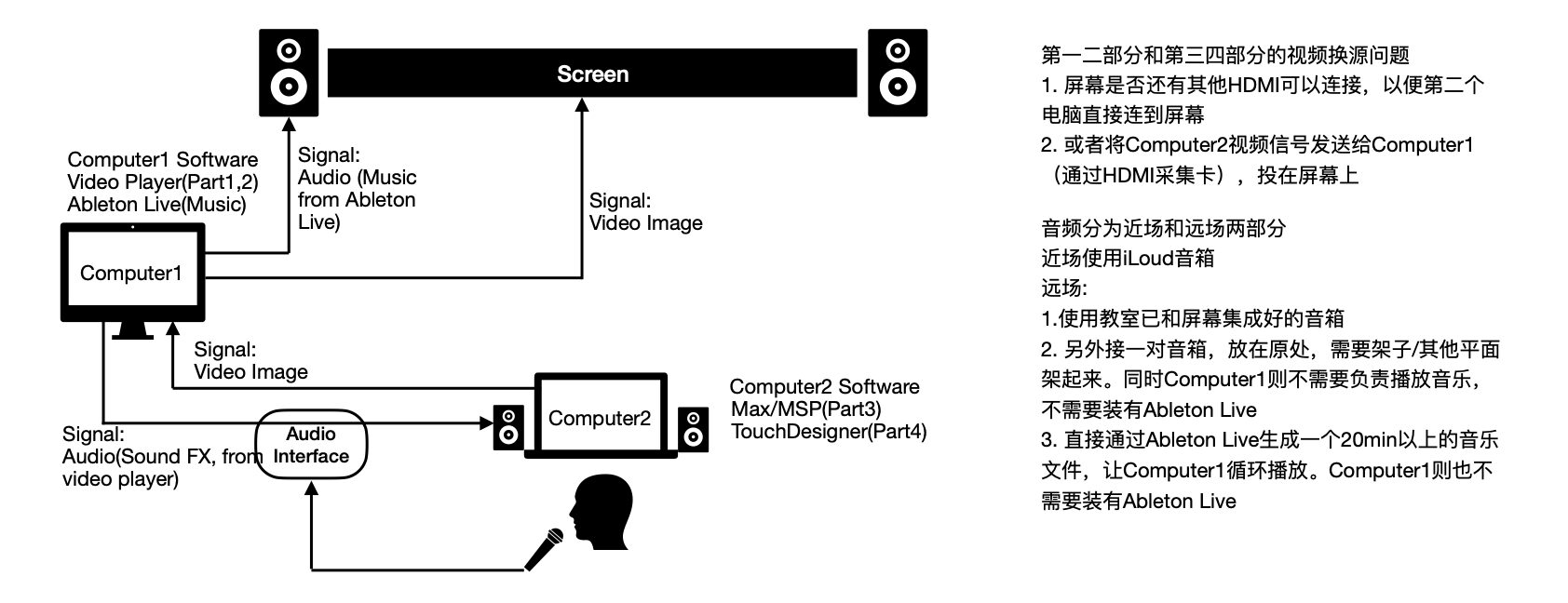
In the formal exhibition, there will be two computers to present different materials and the details of them are as follows.
Computer 1:
Play the video and music to help viewers experience the theme.
Display Video:
Prologue (introduction) + Blur (including memory of faces and object scenes).
Continuously Background Music:
Play real-time in Ableton Live.
Computer 2:
Focus on Viewers’ real-time Interaction
Fade:
Viewers should click a button on the laptop to take a photo first, then speak randomly to the microphone. The sound data and image are transmitted to the Max Patcher. The participant’s portrait will show on the screen, and some visual effects will appear on the screen when the participant is speaking.
Visual changes depend on the level of sound. When the visitor calls loudly, the image becomes relatively clear, while when the sound diminishes, the image becomes blurred. If the call disappears, the screen will gradually become blank.
We provide a poem as reading material to help participants get involved as follows:
By the boundless shores of Lethe, I seek your trace,Faces once clear, now blur in memory's breeze.Like dew in the morning sun, vanishing without a trace,Your smile, your gaze, with time, quietly flee from me.I reach out, trying to touch that fading shadow,But grasp only air, and a faint scent of melancholy.Alzheimer's, this silent thief,Steals our shared memories, bit by bit, from our world.There was a time, side by side, through seasons we trod,Now, I walk alone in this memory's barren land.Your name, I softly call, through thickening fogs,Your face, I struggle to recall, only to blur more with each attempt.Even if memories fade, love remains,In every dawn, every dusk.Alzheimer's may take away your memory,But it can never take away, our undying love within.
In twilight's gentle sway, amidst memories gray,Lie forgotten relics of a bygone day.A radio whispers melodies of yore,Its staticky voice echoing forevermore.Beside it, a television set, silent and still,Once a portal to dreams, now void of thrill.Images flicker, then fade into mist,Lost in the labyrinth of time's twist.A fan hums softly in the corner's embrace,Its blades spinning tales of a forgotten grace.Once a companion in sweltering heat,Now a silent sentinel in memory's retreat.A jar sits empty, its purpose unclear,Once filled with treasures now lost, my dear.Its glass walls hold echoes of laughter and tears,A vessel of stories from forgotten years.In the recesses of a mind now adrift,These objects linger, their memories swift.In their silent presence, a tale unfolds,Of lives once lived, now in shadows enfold.Oh, how time's cruel hand steals memories away,Leaving behind mere relics to sway.Yet in the heart's recesses, they shall forever gleam,Echoes of a life, like a forgotten dream.
Vanish:
First, the participant’s movement path was captured using the same real-time camera and overlaid with the part of the video, allowing the participant’s face to blend in among the different faces generated by the AI, creating the illusion of being lost. Finally, the participant in the frame drifts away with particles and the frame goes black.
Instead of the original plan of making different music for each part, we now plan to make a generative music that requires no control and also randomly plays some melody fragments. I plan to do it in Ableton Live, which will play independently of the video with a separate computer during the exhibition. The screen recording video below shows the current progress of music creation. You can see that Melody Clip is played randomly.
In that track, I set up the Random Midi Effect as well so that each Clip can shift to different notes every time. Later I will add more instruments and implement more variations to the music.
Full Version Music Update in Week9
This version added many voice samples generated by Text To Speech tools and the text materials are as follows.
This version added many voice samples generated by TTS tools, and their corresponding text is shown below.
1. Why do you keep asking the same questions? I've explained it many times
2. Mom, your memory is really getting worse.
3. Where did you put the key? This is already the third time
4. Can you stay by yourself for a while
5. I am your daughter
6. Why don't you remember me again?
7. Dad, why did you put the medicine in the refrigerator again?
8. Didn't we make an agreement?
9. I really can't understand why you are always so stubborn
10. I've told you many times
11. I really don't have time to help you find things every day
12. Why do you always forget to turn off the lights? I have to come here every time
13. Why you can’t do simple things well?
14. I can't stand your chaos anymore and I need to leave this room
15. Don't bother me, I don't have time for you
16. 妈,你能自己回房间待一会吗
17. Maman, tu peux aller seule dans ta chambre pendant un moment ?
18. 何度も言いましたから、何度も聞かないでください
19. Realmente no puedo entender por qué siempre eres tan terco.
20. आपका ऐसा करना वाकई बेवकूफी है
21. Папа, это действительно глупо с твоей стороны.
22. 당신은 나에게 이것을 여러 번 말했습니다!
23. Das hast du mir schon oft gesagt!
I’m working on developing a system for dynamically playing MIDI clips to provide a constantly evolving musical backdrop throughout our project. To build up a diverse library of MIDI clips, I’ve employed Mubert’s Text To Music tool. This tool allows me to generate numerous loop clips that may be thematically relevant to my project. From this pool, I carefully choose clips below that align with the atmosphere and tone of the existing parts of our project.
This week I completed the production of the first part of the video where the AI imitates family members’ daily conversations.
The first part of the text: Based on previous literature research and video review, combined with the suggestions given by AI, I wrote 13 sentences about the daily dialogue between family members and Alzheimer’s patients.
Why do you keep asking the same questions? I’ve explained it many times
Mom, your memory is really getting worse.
Where did you put the key? This is already the third time
Can you stay by yourself for a while
I am your daughter
Why don’t you remember me again?
Dad, why did you put the medicine in the refrigerator again?
Didn’t we make an agreement?
I really can’t understand why you are always so stubborn
I’ve told you many times
I really don’t have time to help you find things every day
Why you can’t do simple things well?
Why do you always forget to turn off the lights? I have to come here every time.
I tried four different ways to get AI to generate speech, and finally I chose to use Elevenlabs AI. There are various timbres, and the generated sounds are real after all. They are emotional sounds, not robot sounds.
Below are all the generated AI sounds.
I made the first part of the video using Adobe After Effects
I will make detailed adjustments next week, and then match the audio with the animation and put them together.
Neutone is an AI audio plugin that brings deep learning DSP models to real-time music production. It allows artists to integrate AI-powered tools into their creative process easily. The plugin supports VST3 and AU formats. Various timbre transfer models and deep learning-powered effects are available for download on this plugin, including transforming sounds into drum kits, voices, violins, and more. Developers can also contribute their own models to the Neutone platform using the NeutoneSDK.
Regarding our Process project, a frequently discussed issue is that, since the theme revolves around memory, the content should be presented more abstractly. This approach helps to avoid touching upon sensitive personal information while still providing a unique style. Nuetone seems to be an excellent tool for achieving this effect. It is a timbre-transform plugin capable of reshaping sound with different timbres. For instance, it can transfer instrumental timbres to voices and vice versa. Because such transformations are based on audio, the resulting outcomes are more abstract compared to having different virtual instruments play the same MIDI clips.
In the project, for voice elements that need to narrate the story, one can first generate some normal talking materials using Text to Speech tools and then process them with Neutone to obtain instrument-like timbre with speaking rhythm or transform them into other voice models for more ambiguous speech materials.
For the musical part of the project, the thematic motives of the music can be transformed into different timbres appearing in different sections. This implementation results in audio with a blurry, even low-definition feel, which aligns with the project’s need for ambiguity while allowing each section to have differences while maintaining overall coherence.