After roughly two months and a half, what first became a set of ideas, discussions and various points of view, questions have turned into answers and a “Place” was created to be presented on the 7th of April 2022 in the Atrium Room of Allison House. On this day, Echoes&Absences was finally showcased to everyone, and with it came a lot of reflections, room for improvement and concluding thoughts.
The large attendance achieved was initially desired, as the space was set out to be shared by a minor to reasonably large group, and the exhibition layout was designed to be discovered collectively. However, the celebratory mood among us developers and the audience may have hurt the sonic domain of the project since its soundscape was often easily masked by the expected sound of visitors chatting. Two thoughts arise from this: on the technical side, this could be perhaps resolved in a space with some second room layout that physically provided a more clear distinction between the exhibition/welcome hub and the actual immersive experience, and perhaps some acoustic isolation; However, when thinking on the exhibition as a “Place” of its own, these sonic interactions between people are an essential aspect to the soundscape, as the place becomes itself furthermore once people are also part of it.
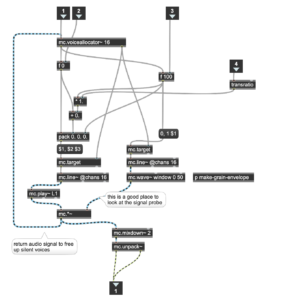
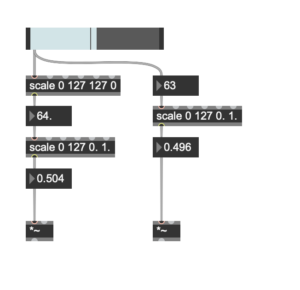
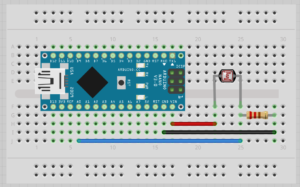
The exhibition’s interactive aspect also seemed desirable since this “on at a time” control surface appeared busy at all times and wildly explored by the individual. While observing the users’ behavioural patterns, some interesting improvement points came up. A wooden plank was given to users when interacting with the interface, with the sole purpose of better ultrasonic detection from the distance sensor; however, users would very commonly tilt, flip and explore the position of this plank instead exclusively of their own. Such a natural reaction led to re-thing a solution for future exhibitions, where instead of placing the Arduino system in a fixed position facing the user, put it on this plank. This solution would allow us to explore accelerometer and gyroscopic data on the Arduino, and if given walls for projection instead of screens, more surface and distance range values to explore.
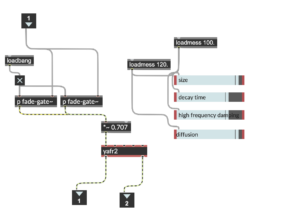
One last aspect seemed worthy of significant improvements. The sonic sculpture of this soundscape initially starts from recording the soundscape of the “News Steps” and then re-synthesised through the sonification of relevant data recorded on this sight. Until this point, the project had achieved a vital full circle of re-synthesis: all sonic outcomes were products of re-shaping the natural foundations of the New Steps. When it came to the nature of the interactive audio, even though spectrally fitting, this did not follow the same principle, which on the conceptual level breaks some of the re-synthesis value and the overall project. One easy way to improve this is to use sonic instances recorded on the sight where it all begins, such as stepping sounds, conversations and other relevant interactions. Another would be using the sensor’s data to trigger abrupt parameter changes on the Max/MSP project, re-synthesising the soundscape.
Overall, this project has allowed me to learn and explore the relationship between a location, its relation with time, and its points of contact with human perception, through methods of deconstruction and reconstruction. Breaking down and questioning the meaning of such intricate concepts of day-to-day life has allowed me to expand the notions of where reality starts and how we intend to perceive it to what my current notion seems limitless and never-ending.
I now acknowledge the tremendous efforts of my colleagues and my immense fortune of having had the opportunity to work and learn from such an incredible bunch. It has been my biggest of pleasures.
Until the next project,
David Ivo Galego

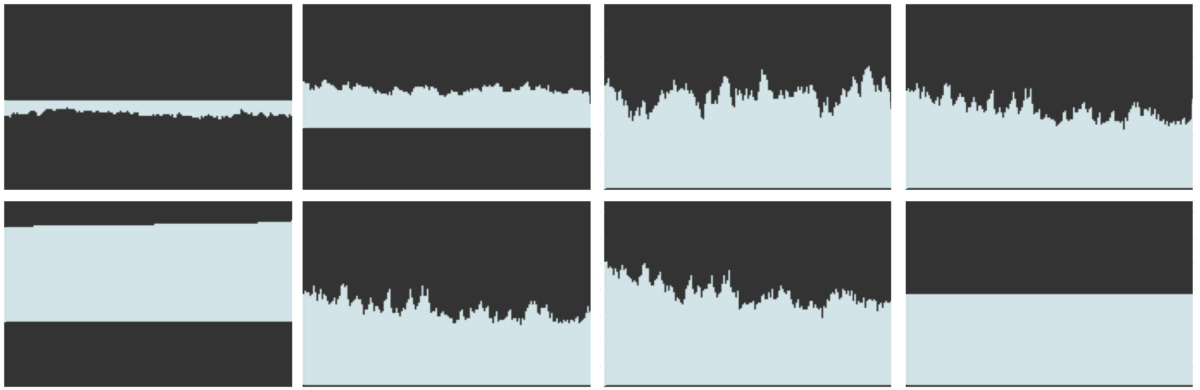


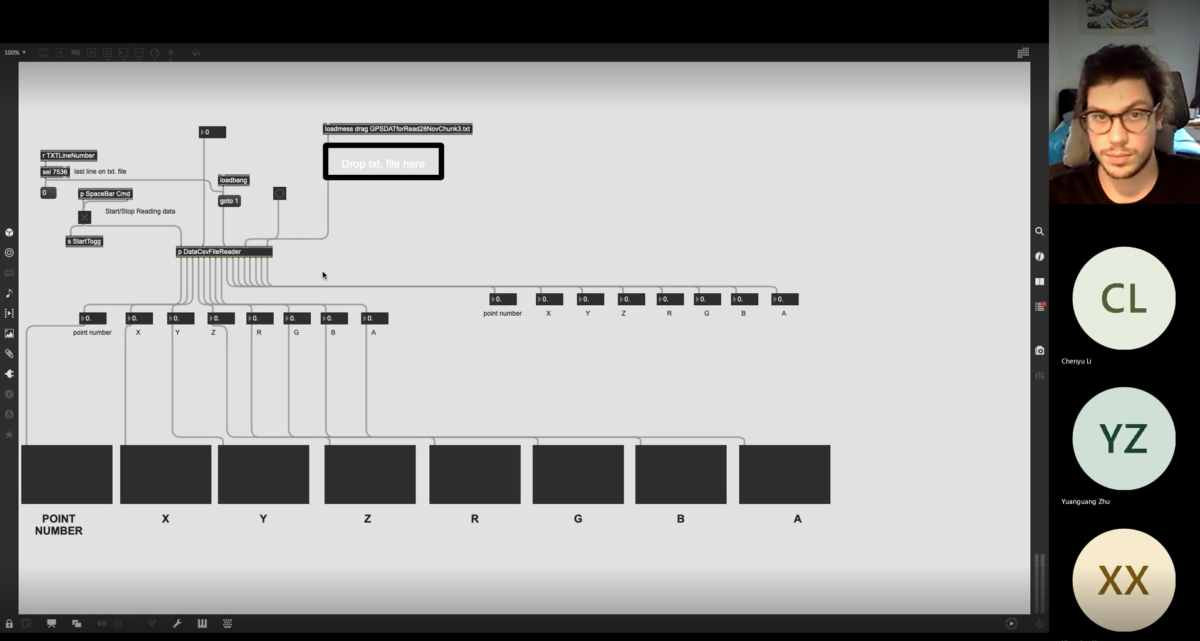


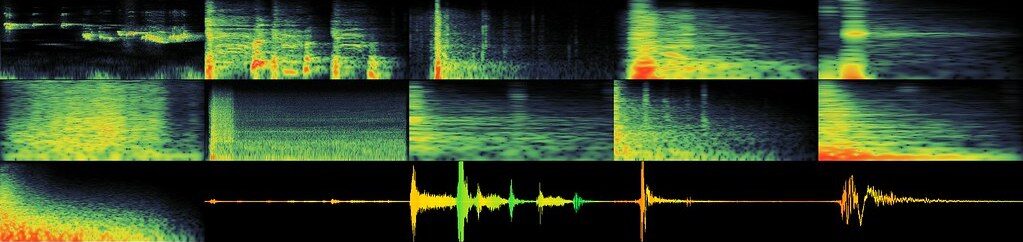




 Across this experimentation four scans were performed, each by a different member of the group. The first, positioned in the center of the room, the
Across this experimentation four scans were performed, each by a different member of the group. The first, positioned in the center of the room, the

