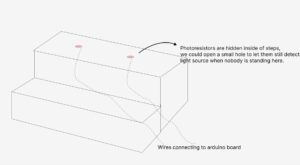
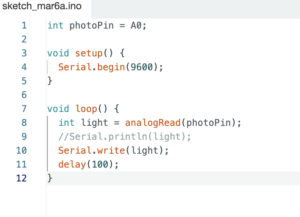
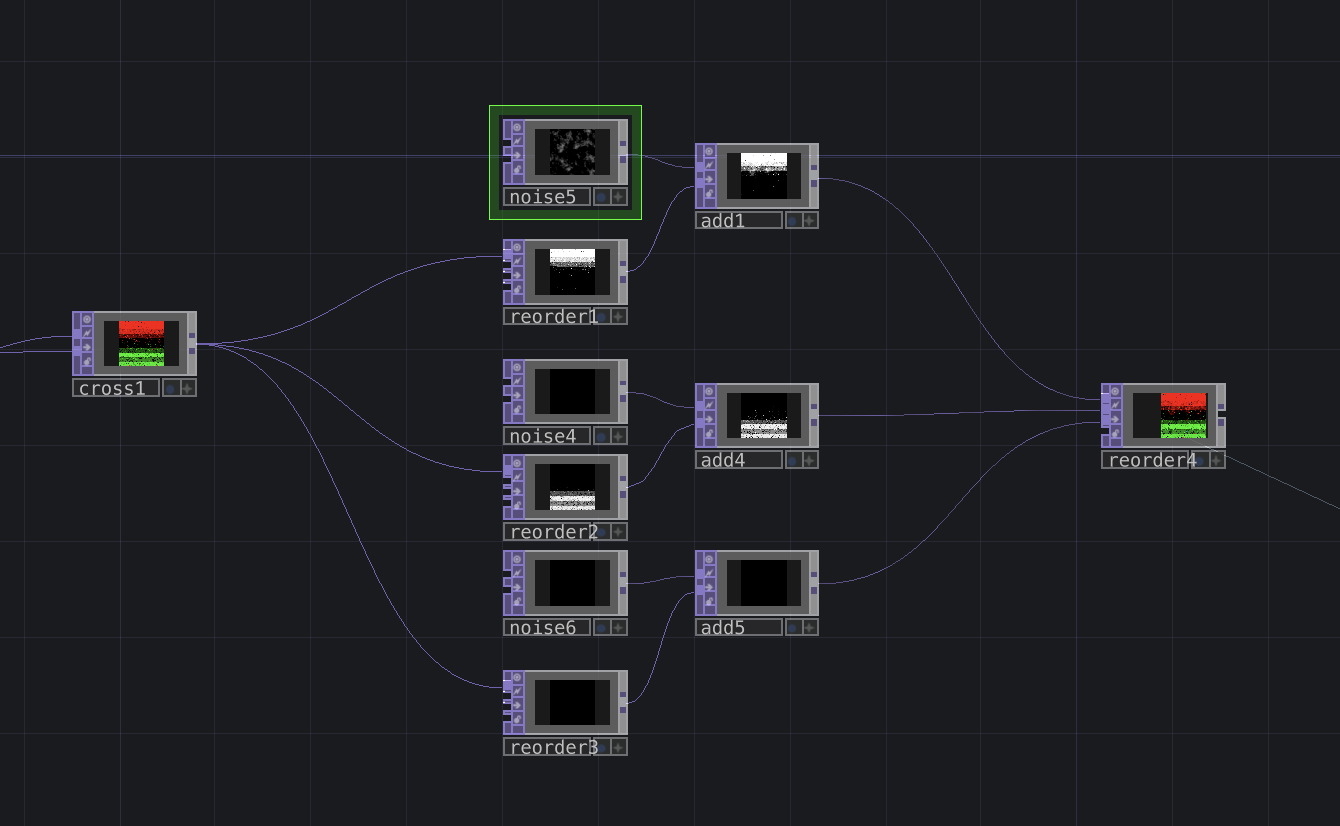
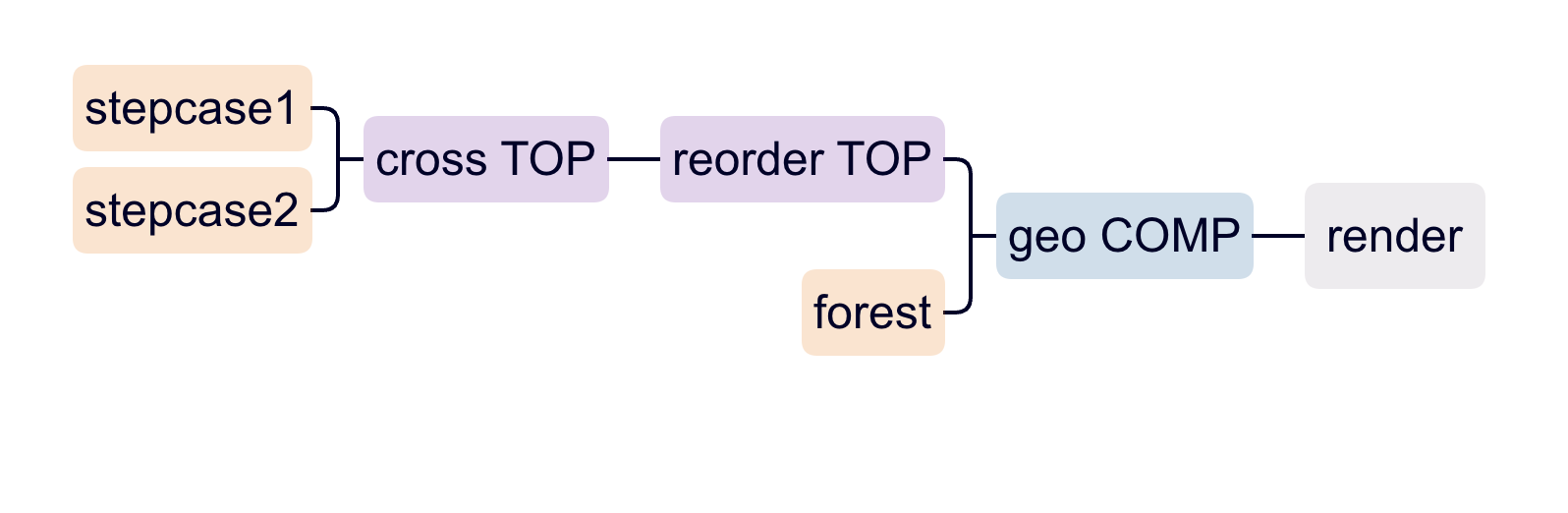
Day 1 – The Morning and Halfway up
Friday 3rd March from 6am – 10:30am

Waking up bright and early at 5am for a 6am field recording at the steps – the city was quiet, dark, and peaceful… if you don’t count listening to all the delivery trucks and bin lorries.
We arrived at The New Steps with an ok-ish attitude, a considerable amount of caffeine, and a plan, to record the scans for the first section of the steps. Deciding to start from the bottom of the steps, we set up everything, took out our companion and biggest ally for the day our buddy Liam the LiDAR (yes we named him, it was a long day), and hit record.

The initial plan was to take one scan on every landing of the steps, just changing the scanner to the right or to the left after each one. But after the first couple of tries, we discovered that we were missing quite a lot of information from the middle of the steps, making the scans look quite empty.
So very carefully we adjusted one of the legs of the tripod and placed the scanner in the middle space between the landings. Because we know how expensive the scanner is, and we were really afraid of someone walking down the steps in a rush and accidentally kicking it, Molly took the role of bodyguard, sitting down right under the scanner to make sure it will stay in its place. And in some scans you can see a bit of blue flashing right next to where the scan was placed, this was the top of Molly’s hat peeking thru.
Around our sixth scan, the iPad showed 10% of the battery left, and the storage was completely full, making us unable to keep scanning. So we went looking for somewhere to charge the electronics, and to warm up for a bit as well. We ended up in the New College where The School of Divinity is located. Asking at the main entrance where we could sit and work for a bit, we headed to Rainy Hall, and settled down there, to export the scans from the iPad into our external hard drive, and then import them to Cyclone.
Here was when we realized just how much data we had gathered so far, as we could not export the bundle from the iPad because we had no storage in it, so we had to export each file individually, then delete it, over and over. Once we had all the files, we put them into Cyclone, and manually aligned each and every single scan, and when we were ready to export them so we could move to CloudCompare, we could not. Why? because the laptop also had no memory left (just our luck).
So back to the steps we went to finish scanning the four places we were missing. And once we were done with it, we waited for the sound team to finish their recordings, and we all headed to Alison House to finish processing the data. Once in the Atrium, we exported the rest of the scans and added them to the bundle in Cyclone. After a bit of trial and error, we were finally able to connect our external hard drive to Cyclone and export our first bundle of scans, yey!
The overall experience for this first day of fieldwork was quite nice, as once we had the scans all together and were able to see just how much amazing data we gathered during some hours in the morning, it made us excited to keep working and looking forward to experimenting with it.
Day 2 – The Afternoon/Evening and the Second Half
Tuesday 7th March from 1:30pm – 7pm
One would have thought that going out at 5am in the morning would be way harder than doing the same thing during the middle of the day, but boy we were wrong. It was much colder this day, making it extremely hard for us to feel comfortable standing on the steps while doing the scans.
We did the first batch of scans from 1pm to around 3pm as we wanted to record the mid-day rush, we quickly notices just how much more movement the was on the steps, as there were quite a good amount of tourists going up and down. We knew that they were tourists because once they hit the middle of the steps, they all looked lost and tried to go thru the gates that lead somewhere else, thinking it was the exit because that is what google maps tells you to go. So we kindly acted as guides telling them that they still had to go up another big stretch of stairs.
We went to charge the iPad and then came back around 4pm to do a couple of scans for the evening part. Then we needed to wait until the sun was setting, so we went to find refuge from the cold in a coffee shop. This day felt like it was neverending, we were sitting down drinking our coffees looking at the window waiting for the sun to go down and it would just not do it. It wants until about 6:30 pm that we could see the sky changing, so we ran back to the stairs and did the final part of it. And just like that, we were done with all our scans. We still had to go and process the data and join the two bundles together, but this was way easier than the first time we did it.

We knew we had gathered a huge amount of data, but I don’t think we were ready when we did the math and found out we had more than one billion points. So it really makes sense why our computers sounded like they were dying while we were processing the data. After some subsampling of our cloud point, we created different versions of it, some to use in blender, unity, or touch designer, and some for our sound teammates to process using MaxMSP.
Timetable
|
Scan |
Location |
Time |
|
1 |
Bottom gate |
7 AM |
|
2 |
Bottom stairs base |
7:13 |
|
3 |
Flight 1 mid |
7:30 |
|
4 |
Landing 1 |
7:42 |
|
5 |
Flight 2 mid |
8am |
|
6 |
Landing 2 |
8:10 |
|
7 |
Flight 3 mid |
10am |
|
8 |
Landing 3 |
10:11 |
|
9 |
Flight 4 mid |
10:22 |
|
10 |
Landing 5 |
10:30 |
|
11 |
Flight 4 mid |
1:30 PM |
|
12 |
Landing 5 |
2 |
|
13 |
Flight 5 mid |
2:10 |
|
14 |
Landing 6 |
2:20 |
|
15 |
Flight 6 mid |
2:25 |
|
16 |
Landing 7 |
2:43 |
|
17 |
Flight 7 mid |
2:48 |
|
18 |
Landing 8 top |
4:40 |
|
19 |
Top tip top outside |
4:45 |
|
20 |
Flight 7 mid |
6:30 |
|
21 |
Landing 8top 2 |
6:40 |
If you’re reading this in order, please proceed to the next post: ‘Field Recording Report’.
Molly and Daniela
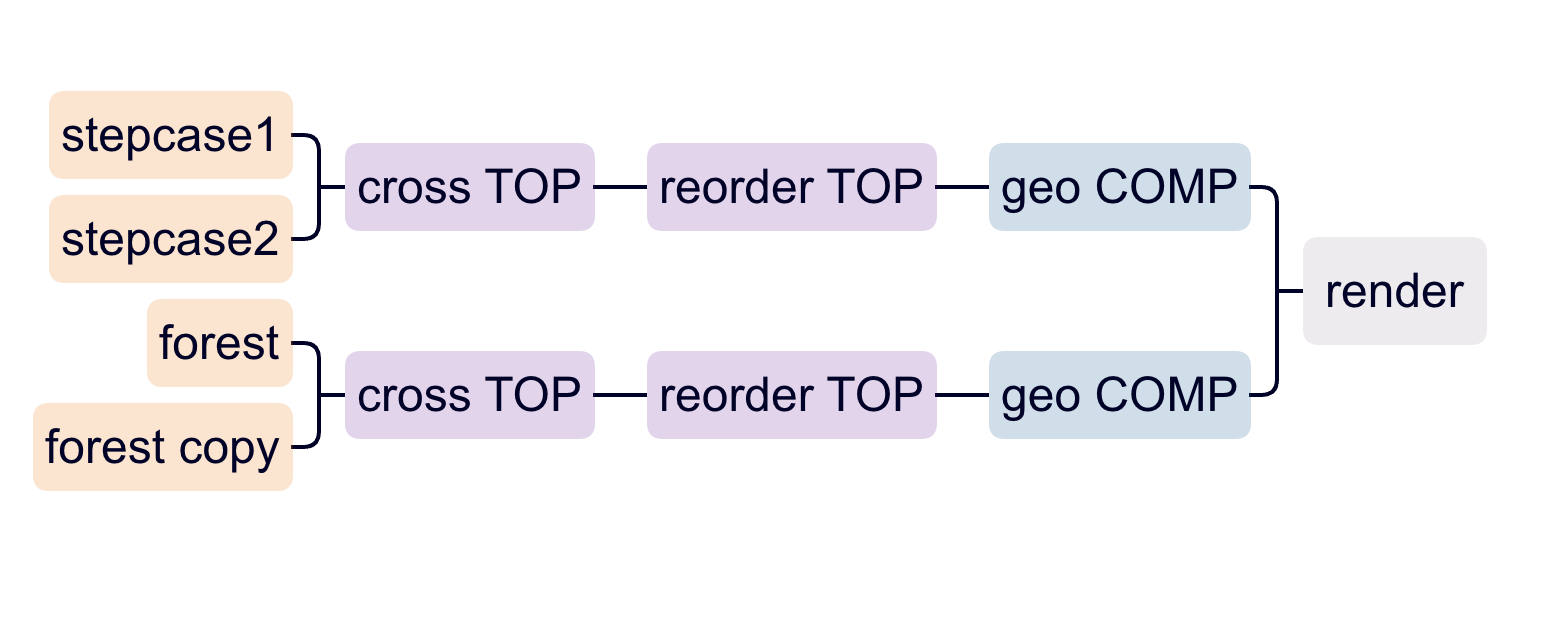
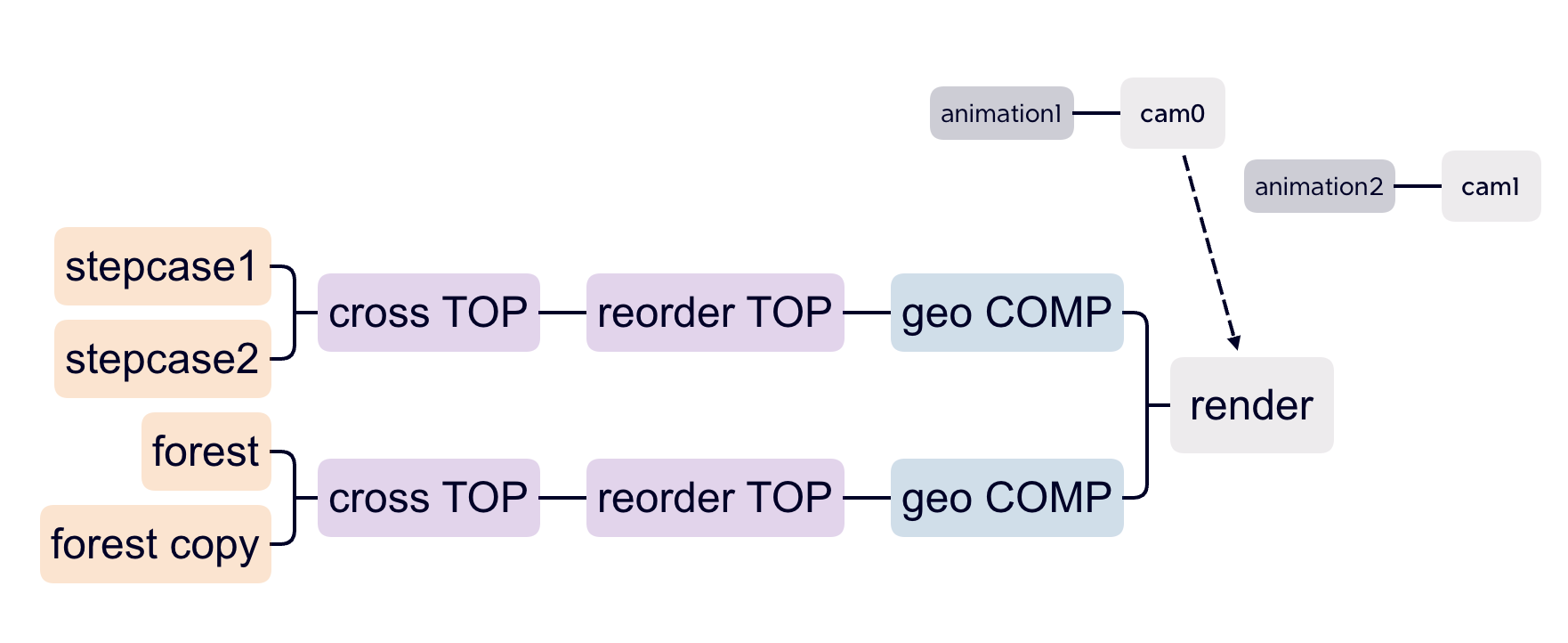
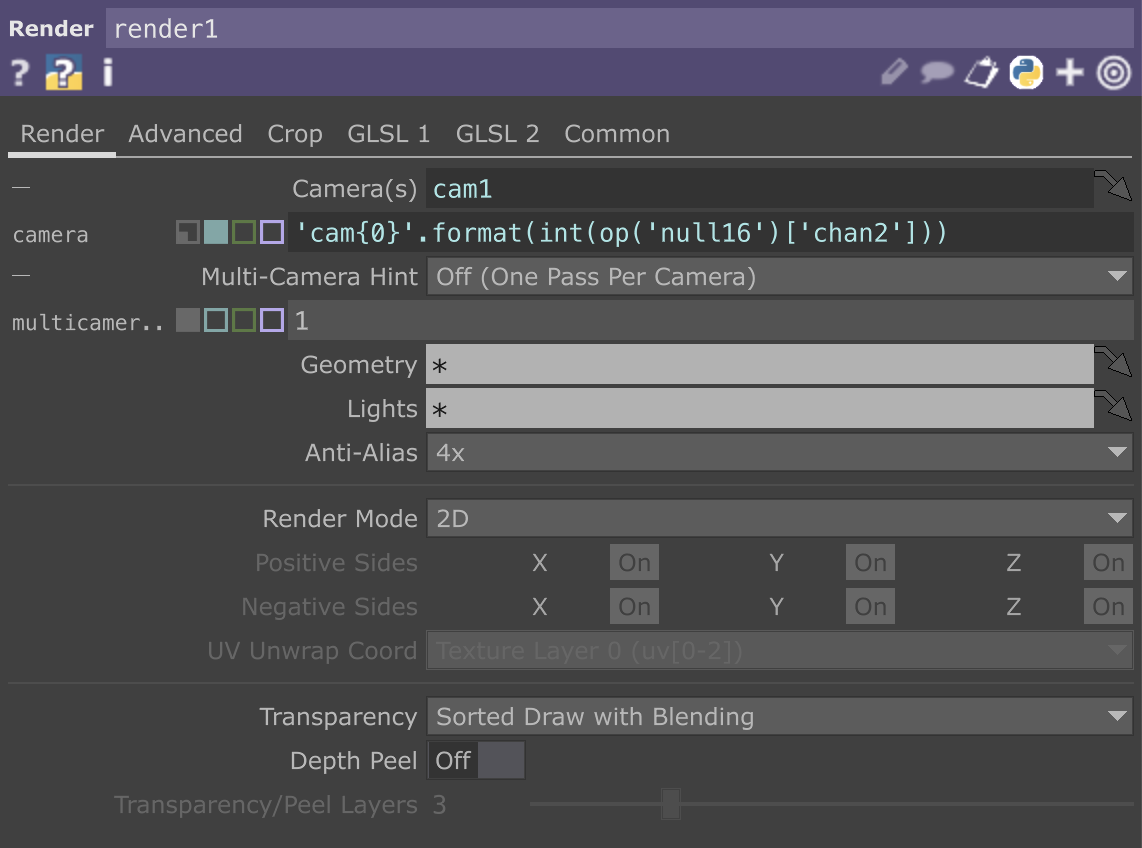


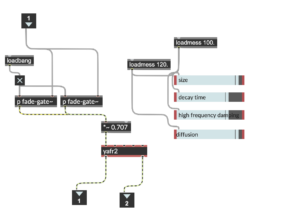
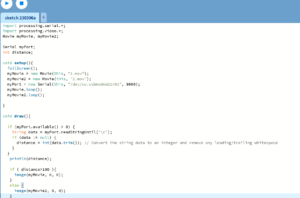
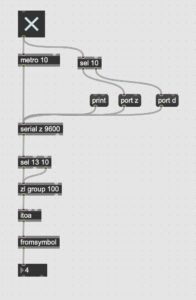
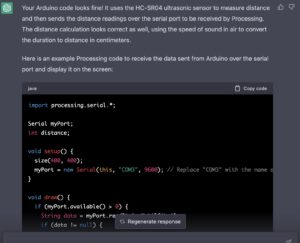
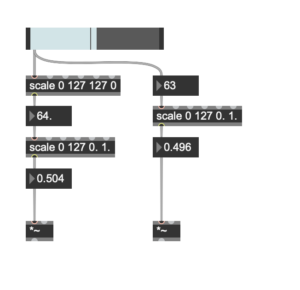
 After the test recording, I tested it again at home and exported the recording from the SD card to check. Because the mixpre6II’s advance working mode is used, the sound is recorded as poly-wave. Because two pairs of microphones are used, the file has six tracks, the first two tracks are a stereo mix of all microphones, and the last four tracks are separate signals from each of the four microphones. In this way, as long as I recorded the input channel number for each microphone, I could easily tell which microphone was recording the current signal in post-editing. After checking, since our two pairs of microphones were placed back-to-back, the recorded signal did not have phase problems and the mixed signal from the first two tracks could be used directly (provided that the balance of each track was adjusted during recording). There was another unexpected gain in the process: if the recorder was powered through the computer, it would last much longer than four AA batteries. But I couldn’t rule out at the time that it was because the room was warmer, so I still brought an extra H6 recorder as plan b when I was formal recording.
After the test recording, I tested it again at home and exported the recording from the SD card to check. Because the mixpre6II’s advance working mode is used, the sound is recorded as poly-wave. Because two pairs of microphones are used, the file has six tracks, the first two tracks are a stereo mix of all microphones, and the last four tracks are separate signals from each of the four microphones. In this way, as long as I recorded the input channel number for each microphone, I could easily tell which microphone was recording the current signal in post-editing. After checking, since our two pairs of microphones were placed back-to-back, the recorded signal did not have phase problems and the mixed signal from the first two tracks could be used directly (provided that the balance of each track was adjusted during recording). There was another unexpected gain in the process: if the recorder was powered through the computer, it would last much longer than four AA batteries. But I couldn’t rule out at the time that it was because the room was warmer, so I still brought an extra H6 recorder as plan b when I was formal recording.