Any views expressed within media held on this service are those of the contributors, should not be taken as approved or endorsed by the University, and do not necessarily reflect the views of the University in respect of any particular issue.
In working on the project for the University of Edinburgh, our team from Code Your Future is thrilled to present our project, ‘Crowdsourcing User Judgements for Gaelic Normalisation’. Aimed at Gaelic speakers, this project will collect user inputs on passages of historical Gaelic writing that have been updated to modern orthography by an AI model developed by the University of Edinburgh. Through hard work, collaboration, innovation and problem-solving, we have hugely enhanced a previous research project, ‘An Gocairː An Automatic Gaelic Standardiser’ and not only met but exceeded our goals.
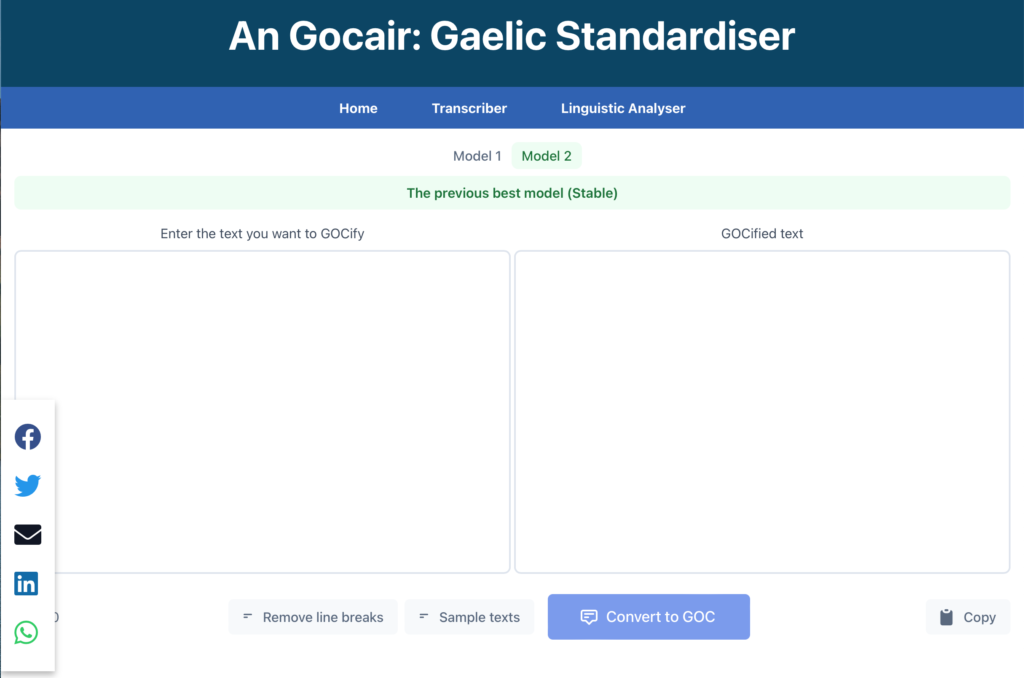
The ‘An Gocair’ Web App
Our team used the PERN stack as it uses a common framework and program language so it can be easily modified to enhance user experience and interactions in the future. In today’s globalised world, it is useful to be able to launch this application from any device and location. We have admin features in our application to give researchers more control over the data, and user sign-in features that allow users to sign in from social media accounts. Throughout the project, there were challenges in terms of adhering to project requirements. Those challenges were an opportunity for us to learn. So we valued our team members’ creativity, experimentation and unique skills to find solutions to the problems that aligned with our project objective.
The Reinforcement Learning with Human Feedback App – for crowdsourcing Gaelic speaker judgements on AI-corrected texts
Our project followed an agile mindset that prioritises interactions, customer collaborations and responsiveness to change. As a result, we adapted agile values and principles focusing on short development cycles like creating simpler tasks, allocating them to the team members and receiving constant feedback from the team lead. Also, the agile approach helped us to manage time efficiently through sprint planning, daily standup meetings and optimising our time allocation and productivity.
By using React we have made every feature into a component so it can be easily modified in the future. By using the Passport module we have made the application more secure. Implementing it into the application was a challenge, however, and took a lot of the time. Before coming up with the passport, we tried a few different authentication tools but they did not give us the ability to be used as login with other social media accounts.
Our project relies on data and the Postgres database management system is useful for storing and managing our data efficiently. Our database Schema design considers scalability in mind to handle a growing dataset and increased user load. We also implemented proper encryption and access control, to protect users’ data and maintain user privacy through admin features.
Decoding Hidden Heritages in Gaelic Traditional Narrative with Text-Mining and Phylogenetics
This exciting new three-year study is funded by the AHRC and IRC jointly under the UK–Ireland collaboration in digital humanities programme. It brings together five international universities, two folklore archives and two online folklore portals.
October 2021–Sept 2024
‘Morraha’ by John Batten. From Celtic Fairy Tales (Jacobs 1895)
Summary
This project will fuse deep, qualitative analysis with cutting-edge computational methodologies to decode, interpret and curate the hidden heritages of Gaelic traditional narrative. In doing so, it will provide the most detailed account to date of convergence and divergence in the narrative traditions of Scotland and Ireland and, by extension, a novel understanding of their joint cultural history. Leveraging recent advances in Natural Language Processing, the consortium will digitise, convert and help to disseminate a vast corpus of folklore manuscripts in Irish and Scottish Gaelic.
The project team will create, analyse and disseminate a large text corpus of folktales from the Tale Archive of the School of Scottish Studies Archives and from the Main Manuscript Collection of the Irish National Folklore Collection. The creation of this corpus will involve the scanning of c.80k manuscript pages (and will also include pages scanned by the Dúchas digitisation project), the recognition of handwritten text on these pages (as well as some audio material in Scotland), the normalisation of non-standard text, and the machine translation of Scottish Gaelic into Irish. The corpus will then be annotated with document-level and motif-level metadata.
Analysis of the corpus will be carried out using data mining and phylogenetic techniques. Both the data mining and phylogenetic workstreams will encompass the entire corpus, however, the phylogenetic workstream will also focus on three folktale types as case studies, namely Aarne–Thompson–Uther (ATU) 400 ‘The Search for the Lost Wife’, ATU 425 ‘The Search for the Lost Husband’, and ATU 503 ‘The Gifts of the Little People’. The results of these analyses will be published in a series of articles and in a book entitled Digital Folkloristics. The corpus will be disseminated via Dúchas and Tobar an Dualchais, and via a new aggregator website (under construction) that will include map and graph visualisations of corpus data and of the results of our analysis.
Project team
UK
Principal Investigator Dr William Lamb, The University of Edinburgh (School of Literatures, Languages and Cultures)
Co-Investigator Prof. Jamshid Tehrani, Durham University (Department of Anthropology)
Co-Investigator Dr Beatrice Alex, The University of Edinburgh (School of Literatures, Languages and Cultures)
University of Edinburgh
Language Technician, Michael Bauer
Louise Scollay, Copyright Administrator
Ireland
Co-Principal Investigator Dr Brian Ó Raghallaigh, Dublin City University (Fiontar & Scoil na Gaeilge)
Co-Investigator Dr Críostóir Mac Cárthaigh, University College Dublin (National Folklore Collection)
Co-Investigator Dr Barbara Hillers, Indiana University (Folklore and Ethnomusicology)
While some of our research group has been busy creating the world’s first Scottish Gaelic Speech Recognition system, others been creating the world’s first Scottish Gaelic Text Normaliser. Although it might not turn the heads of AI enthusiasts and smart device lovers in the same way, the normaliser is an invaluable tool for unlocking historical Gaelic, enhancing its use for machine learning and giving people a way to correct Gaelic spelling with no hassle.
Rob Thomas
Why do we need a Gaelic text normaliser? Well, this program takes pre-standardised texts, which can vary in their orthography, and rewrites them in the modern Gaelic Orthographic Conventions (GOC). GOC is a document published by the SQA which details the modern standards for writing in Gaelic. Text normalisation is an important step in text pre-processing for machine learning applications. It’s also useful when reprinting older texts for modern readers, or if you just want to quickly spellcheck something in Gaelic.
I joined the project towards the end and have been fast at work trying to understand Gaelic orthography, how it has developed over the centuries, and what is possible in regards to automated normalisation. I have been working alongside Michael ‘Akerbeltz’ Bauer, a Gaelic linguist with extensive credentials. He has literally written the dictionary on Gaelic as well as a book on Gaelic phonology: it is safe to say I am in good hands. We have been working together to find a way of teaching a program exactly how to normalise Gaelic text. Whereas a human can explain why a word should be spelt a specific way, programming this takes quite a bit of figuring out.
An early ancestor to Scottish Gaelic (Archaic Irish) was written in Ogham, and interestingly enough was carved vertically into stone.
Luckily historical text normalisation is a well-trodden path, and there are plenty of papers and theses online to help. In her thesis, Eva Pettersson describes four main methods for normalising text and, inspired by these, we got started. The first method relies on possessing an extensive lexicon of the target language, which we so happen to have, thanks to Michael.
Lexicon Based Normalisation
This method relies upon having a large lexicon stored that can cover the majority of words in the target language. Using this, you can check to see if a word is spelt correctly, whether it is in a traditional spelling, or if the writer has made a mistake.
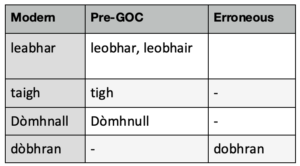
The advantage of this method is that you do not have to be an expert in the language yourself (lucky for me!). Our first step was finding a way to integrate the world’s most comprehensive digital Scottish Gaelic dictionary, Am Faclair Beag. The dictionary contains traditional and misspelt words mapped to their correct spellings. This meant that we can have the program go through a text and swap words if it identifies one that needs correcting.
The table above shows some modern words with pre-GOC variants or misspellings. Michael has been collecting Gaelic words and their spelling variants for decades. If our program finds a word that is ‘out of dictionary’, we pass it on to the next stage of normalisation, which involves the hand crafting of linguistic rules.
‘An Gocair’
Rule-based Text Normalisation
Once we have filtered out all of the words that can be handled by our lexicon alone, we try to make use of linguistic rules. It’s not always easy to program a rule so that a computer can understand it. For example, we all know the English rule ‘i before e except after c’ (which of course is an inconsistent rule in English). We can program this by getting the computer to catch all the i’s before e’s and make sure they don’t come after a c.
With guidance from Michael, we went about identifying rules in Gaelic that can be intuitively programmed. One common feature of traditional Gaelic is the replacement of vowels with apostrophes at the end of words if the following word begins with a vowel. This is called ellipsis and is due to the fact that, if one were to speak the phrase, one wouldn’t pronounce both vowels: the writer is simply writing how they would speak. For example, native Gaelic speakers wouldn’t say is e an cù a tha ann ‘it is the dog’: they would say ’s e ’n cù a th’ ann, dropping three vowels. But in writing, we want these vowels to appear – at least for most machine learning situations.
It is not always straightforward working out which vowel an apostrophe replaces, but we can use a rule to help us. Gaelic vowels come in two categories, broad (a, o, u) and slender (e, i). In writing, vowels conform to the ‘broad to broad and slender to slender rule’, so when reinstating a vowel at the end of a word we need to check the form of the first vowel to the left of our apostrophe and ensure that, if it is a broad vowel, we add in a matching vowel.
Pattern Matching with Regular Expression
For this method of normalisation we make use of regular expressions for catching common examples that require normalisation, but are not covered by the lexicon or our previous rules. For example, consider the following example, which is a case of hyper-phonetic spelling, when a person writes like they speak:
Tha sgian ann a sheo tha mis’ a’ toir dhu’-sa.
Here, the word mis’ is given an apostrophe as a final character, because the following word begins with a vowel. GOC suggests that we restore the final vowel. To restore this vowel, we’re helped by the regularity of the Gaelic orthography, a form of vowel harmony, whereby each consonant has to be surrounded either by slender letters (e, i) or broad letters (a, o, u). So in the example above we need to make sure the final vowel of mis’ is a slender vowel (mise), because the first vowel to the left is also slender. We have managed to program this and, using a nifty algorithm, we can then decipher what the correct word should be. When the word is resolved we check to see if the resolved form is in the lexicon and if it is, we save it and move on to the next word.
Evaluation
Now you might be wondering how I managed to learn Scottish Gaelic so comprehensively in five months that I was able to write a program that corrects spelling and also confirm that it is working properly. Well, I didn’t. From the start of the task, I knew there was no way I would be able to gain enough knowledge about the language that I could confidently assess how well the tool was performing. Luckily I did have a large amount of text that was corrected by hand, thanks to Michael’s hard work.
To be able to verify that the tool is working, I had to write some code that automatically compares the output of the tool to the gold standard that Michael created, and then provide me with useful metrics. Eva Peterssonn describes in her thesis on Historical Text Normalisation two such metrics: error reduction and accuracy. Error reduction provides you with the percentage of errors in a text that are successfully corrected using the following formula:
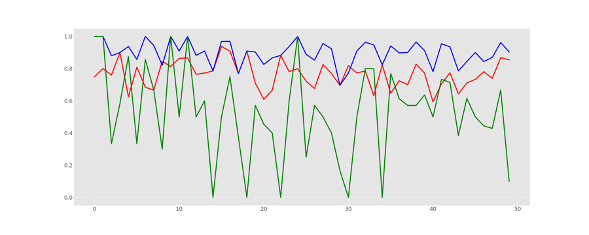
Accuracy simply evaluates the number of words in the gold standard text which has an identical spelling in the normalised version. Below you can see the results of normalisation on a test set of sentences. The green line shows the percentage or errors that are corrected whilst the red and blue line show the accuracy before and after normalisation, respectively. As you can see the normaliser manages to successfully improve the accuracy, sometimes even to 100%.
From GOC to ‘An Gocair’
With a play of words on GOC, we have named the program An Gocair ‘The Un-hooker’. We have tried to make it as easy as possible to update it with new rules. We hope to have the opportunity to create more rules in the future ourselves. The program will also improve with the next iteration of Michael’s fabulous dictionary. We hope to release the first version of An Gocair to the world by the end of October 2021. Keep posted!
Acknowledgement
This program was funded by the Data-Driven Innovation initiative (DDI), delivered by the University of Edinburgh and Heriot-Watt University for the Edinburgh and South East Scotland City Region Deal. DDI is an innovation network helping organisations tackle challenges for industry and society by doing data right to support Edinburgh in its ambition to become the data capital of Europe. The project was delivered by the Edinburgh Futures Institute (EFI), one of five DDI innovation hubs which collaborates with industry, government and communities to build a challenge-led and data-rich portfolio of activity that has an enduring impact.
In ourlast blog post, we outlined some of the data preparation that is necessary to train the acoustic model for our Scottish Gaelic speech recognition system. This includes normalization and alignment. Normalization is where speech transcriptions are stripped of punctuation, casing, and any unspoken text. Alignment is where each word in a transcription is stamped with a start and end time to show where it occurs in an audio recording.
After these steps, speech data can be used to train an acoustic model. Once combined with our lexicon and language model (as described in our last blog post), this forms the full speech recognition system. In this blog post, we explain the function of the acoustic model and outline two common forms. We also report on our most recent Gaelic speech recognition results.
The Acoustic Model
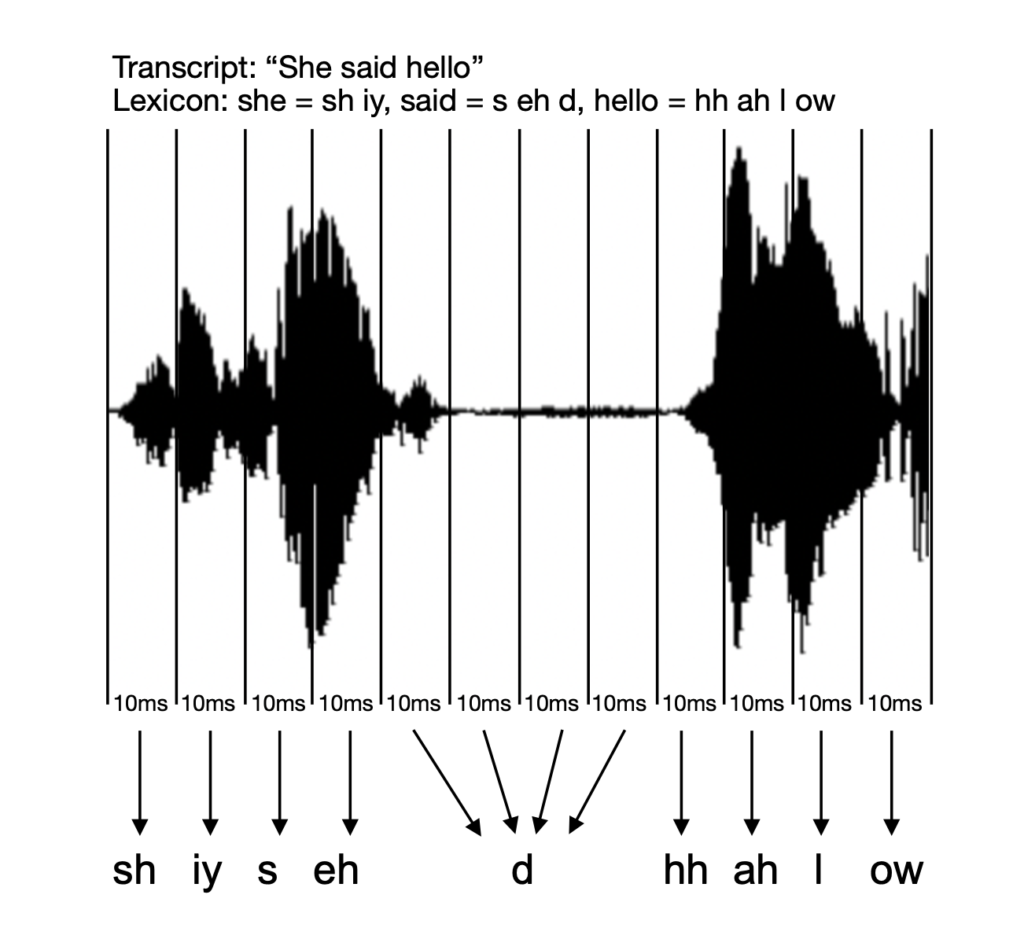
The acoustic model is the component of a speech recogniser that recognises short speech sounds. Given an audio input where a speaker says, “She said hello”, for example, the acoustic model will try to predict which phonemes make up that utterance:
Audio Input
Acoustic Model Output
Speaker says “She said hello”
sh iy s eh d hh ah l ow
The acoustic model is able to recognise speech sounds by relying on its component phoneme models. Each phoneme model provides information about the expected range of acoustic features for one particular phoneme in the target language. For example, the ‘sh’ model will capture the typical pitch, energy, or formant structure of the ‘sh’ phoneme. The acoustic model uses the knowledge from these models to recognise the phonemes in an input stream of speech, based on its acoustic features. Combining this prediction with the lexicon, as well as the prediction of the language model, the system can transcribe the input sentence:
ASR System Component(s)
Output, given a speaker saying: “She said hello”
Acoustic Model Prediction
sh iy s eh d hh ah l ow
+ Lexicon
sh iy = she
s eh d = said
hh ah l ow = hello
+ Language Model Prediction
She said hello
Training the Acoustic Model
In order to train our acoustic model, we feed it a large quantity of recorded speech in the target language. These are split up into sequences of 10ms ‘chunks’, or frames. Alongside the recordings, we also feed in their corresponding time-aligned transcription:
Aligned Gaelic speech
Using the lexicon, the system maps each word in the transcript to its component phonemes. Then, according to the start and end times of that word, it can estimate which phoneme is being pronounced during each 10ms frame where the word is being spoken. By gathering acoustic information from every frame in which each particular phoneme is pronounced, the set of phoneme models can be generated.
Training procedure for the Acoustic Model
Types of Acoustic Model: Gaussian Mixture Models vs Deep Neural Networks
Early acoustic modelling approaches incorporated the Gaussian Mixture Model (GMM) for building phoneme models. This is a generative type ofmodel, meaning that it recognises the phonemes in a spoken utterance by estimating, for every 10ms frame, how likely each phoneme model is to generate that frame. For each frame, the phoneme label of the model with the highest likelihood is output.
More recent, state-of-the-art approaches use the Deep Neural Network (DNN) model. This is a discriminative model. The model directly classifies each input frame of speech with a predicted phoneme label, based on the discriminatory properties of that frame (such as its pitch or formant structure). The outputs of the two models are therefore the same – a sequence of phoneme labels – but generated in different ways.
The reason that the DNN has overtaken the GMM in speech recognition applications is largely due to its modelling power. DNNs are models with a number of different ‘layers’, and consequently a larger number of parameters. Parameters are variables contained within the model, whose values are estimated from the training data. Put simply, having more parameters enables DNNs to retain much more information about each phoneme than GMMs, and as such, they perform better on speech recognition tasks.
Another key difference between the two types of acoustic model is the training data they require. For GMMs, we can simply input recordings with their time-aligned transcriptions, as we already prepared using Quorate’s English aligner. On the other hand, training the DNN requires that every frame of each recording is classified with its corresponding Gaelic phoneme label. We obtain these labels by training a GMM acoustic model, which, once trained on the Gaelic recordings and time-aligned transcriptions, can be used for forced alignment. During forced alignment, each frame of the speech data is aligned to a ‘gold standard’ phoneme label. This output can then be used to train the DNN model directly.
Speech Recognition Results
Having carried out the training of our GMM and DNN acoustic models, we are now in a position to report our first speech recognition results. We initially trained our models using only the Clilstore data, which amounted to 21 hours of speech training data. Next, we added the Tobar an Dualchais data to our training set, which increased the size of the dataset to 39.9 hours of speech (NB: the texts in this data are transcriptions of traditional narrative from the School of Scottish Studies Archives, made by Tobar an Dualchais staff). Finally, we added data from the School of Scottish Studies Archives via theAutomatic Handwriting Recognition Project to train our third, most recent model, on 63.5 hours of speech.
We evaluated our models on a subset of the Clilstore data, which was excluded from the training data. This evaluation set comprises 54 minutes of speech, from 21 different speakers. Each recording was passed through the speech recogniser to produce a predicted transcription. We then measured the system’s performance using Word Error Rate (WER). The WER value is the proportion of words that the speech recogniser transcribes incorrectly for each input recording. The measure can also be inverted to reflect accuracy.
As can be seen from the table below, our results have been encouraging, especially considering that DNN models perform best when trained on much larger quantities (100s of hours) of data. We are particularly pleased to report that our latest model passed below 30% WER (i.e. > 70% accuracy), an initial goal of our Gaelic speech recognition project.
Model
Training Corpus (hours of speech)
Word Error Rate (WER)
Accuracy
WER Reduction (from previous model)
A
Clilstore (21)
35.8%
64.2%
–
B
Clilstore
+ Tobar an Dualchais (39.9)
31.0%
69.0%
4.8%
C
Clilstore
+ Tobar an Dualchais
+ Handwriting (63.5)
28.2%
71.8%
2.8%
To showcase our speech recogniser’s current performance, we have put together some demo videos. These are subtitled with the speech recogniser’s predicted transcription for each video. Please note that the subtitles will have imperfections, given that we are using our speech recogniser (with 71.8% accuracy) to generate them. Take a look by clicking this link!
Demo video screenshot
Next Steps…
With just 2 months left of the project, the countdown is on! We plan to spend this time adding a final dataset to the model’s training data, with the hopes of further reducing the WER of our system. After this, we plan to experiment with speech recognition techniques, such as data augmentation, to maximise the performance of the system on the data we have collected thus far. Make sure to look out for further updates coming soon!
Acknowledgements
With thanks to Data-Driven Innovation Initiative for funding this part of the project within their ‘Building Back Better’ open funding call
Dr Loïc Boizou (Vytautas Magnus University) and Dr William Lamb (University of Edinburgh) have collaborated on a new bilingual website that provides a linguistic toolkit for Scottish Gaelic. Called Mion-sgrùdaiche Cànanachais na Gàidhlig or the Gaelic Linguistic Analyser, the site provides users with tools for analysing the words and structures of Gaelic sentences. The information provided by these tools can be used for additional natural language processing (NLP) tasks, or just for exploring the language further. This new website presents the tools together for the first time and provides users with two ways of interacting with them: a graphical interface and a command line method.
‘Like black magic’
The website’s development goes back to the late 1990s, when Lamb was working on his PhD. In order to investigate grammatical variation in Gaelic, Lamb constructed the first linguistically annotated corpus of Scottish Gaelic, spending over a year annotating 80,000 words of Gaelic by hand. He says, ‘It was a slog. Typing in 100,000 tags by hand… just don’t do it. I developed a nasty case of repetitive strain injury and vowed never to do this sort of thing by hand again.’ After returning to the University of Edinburgh in 2010, after 10 years at Lews Castle College Benbecula, he revisited his corpus to develop an automatic part-of-speech tagger and make the corpus available to other researchers. Today, the corpus is known as the ‘Annotated Reference Corpus of Scottish Gaelic’ or ARCOSG and is available freely online.
The corpus forms the backbone of two of the tools on the new website: the part-of-speech tagger and the syntactic parser. They were created using machine learning techniques, modelling the kinds of patterns that you find in Gaelic speech and writing. Lamb said, ‘what you can do today even with a relatively small amount of text is tremendously exciting. When we looked at developing a POS tagger in the 90s, we would have had to program each type of pattern manually to enable the computer to recognise it properly. Now, you can just run the corpus through a set of algorithms and the computer works the patterns out itself. It’s like black magic’.
Dr Will Lamb
The lemmatiser was developed in a different way, using a form of the popular online dictionary, Am Faclair Beag. Lamb explains: ‘When we were working on the part-of-speech tagger in 2013 or 14, Sammy Danso and I got in touch with Michael Bauer and Will Robertson, who put together the fantastic Am Faclair Beag. We were going to try to leverage some of the information in the dictionary, and they generously offered their data for this purpose. While that plan didn’t materialise, I was able to create a root finder or lemmatiser with it years later, which we used to help create the first neural network for Gaelic. The lemmatiser sat in the virtual cupboard for a while, until I was contacted by Loïc in 2017. Loïc wanted to create a proper Gaelic lemmatiser, and I was onboard.’
Dr Loïc Boizou
Dr Loïc Boizou is a Swiss French NLP specialist working in Lithuania (Vytautas Magnus University) who is interested in computational tools for under-resourced languages. He received his PhD in Natural Language Processing at Inalco (Institute of Eastern Languages and Civilisations) in Paris. About the project, he said, ‘I am very supportive of cultural diversity and Gaelic is one of the few endangered languages that provides serious opportunities for distance learning, thanks to Sabhal Mòr Ostaig. I really enjoyed learning the language and I decided to use my NLP skills to give it a bit of a boost. I learned about Will’s corpus and found we could cooperate very nicely.’
Roots, Trees and Tags
The website provides different ways of exploring Gaelic text. Lemmatisation is simplest of the tools and involves retrieving a word’s root form. If you were to input a sentence like tha na coin mhòra ann (‘the big dogs are here’), the website would return ‘bi’, ‘cù’ and ‘mòr’ as the lemmas (root forms) of bha, coin and mhòra. The website also offers part-of-speech tagging, which provides grammatical information about words in a sentence. Using the previous example, the website’s algorithms would assign ‘POS tags’ to each word, as in the third tab-separated value in each line below (glossed in inverted commas):
tha bi V-p 'Verb: present tense'
na na Tdpm 'Article: pl masc def'
coin cù Ncpmn 'Noun: common pl masc nom'
mhòra mòr Aq-pmn 'Attributive adjective: plur masc nom'
ann e Pr3sm 'Prep pronoun: 3rd person sing masc'
The grammatical information in this example is quite precise, but such precision comes at a cost: the default tagger is subject to error about 9% of the time. For users who want simpler POS tags and more accurate tagging, the website also offers a ‘simplified tagset’ option, which provides 95% accuracy. The same sentence above, submitted with this option would provide the following:
tha bi Vp 'Verb: present tense'
na na Td 'Article: definite'
coin cù Nc 'Noun: common'
mhòra mòr Aq 'Adjective: attributive'
ann e Pr 'Prepositional pronoun'
In addition to lemmatisation and POS-tagging, the site also offers syntactic parsing, using a syntactically annotated corpus developed by Dr Colin Batchelor (Royal Society of Chemistry). Again, using the same sentence, the website returns the following if parsing is selected:
1 tha bi V-p 0 root
2 na na Tdpm 3 det
3 coin cù Ncpmn 1 nsubj
4 mhòra mòr Aq-pmn 3 amod
5 ann e Pr3sm 1 xcomp:pred
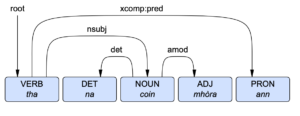
The number in the 4th column indicates which element in the sentence the word is governed by. In the case of tha, the number is 0, because it is the syntactic root. Both na and mhòra, on the other hand, are parts of a noun phrase governed by element 3, coin. This is a numerical way of displaying the kind of information that is often conveyed in a syntactic tree, such as in the example below. The information in column 5 indicates the function of the element in the sentence. For example, the function of coin is nsubj or ‘nominal subject’. More information on Dr Batchelor’s parser can be found here.
Syntactic tree for tha na coin mhòra ann
Next Steps
When asked what the next steps are for the language, Lamb explains that it’s an exciting time: ‘Well, this is really just an interim step and there is a lot to do. For a start, we hope to improve the accuracy of the tools gradually and perhaps augment them. Gaelic is, in some ways, in a very fortunate position when it comes to language technology. Advanced tools are starting to come online — like Google Translate, a handwriting recogniser and speech synthesiser — and we can exploit great resources like DASG, ARCOSG and recordings from the School of Scottish Studies Archives to push into territory that would have seemed like science fiction a few years ago.’
The dream is artificial general intelligence. ‘Elon Musk is famous for saying that one day, he’d like to die on Mars – just not on impact. Before I kick the proverbial bucket, I’d like to chat with a computer that has better Gaelic than I do’.
ARCOSG has been used for a range of projects including a voice synthesiser and syntactic parser. It has been newly revised and made compatible with the popular Natural Language Toolkit (NLTK): release available here.
A simplified version of the corpus has also been released, ARCOSG-S, which uses a less complex tag scheme (41 tags vs 246). It is available here.
With funding from UoE Challenge Investment Fund (Aug 2019), a small team of us have been busy developing the first handwriting recogniser for Scottish Gaelic. To do this, we have used Transkribus, a sophisticated, machine-learning based platform and on-line text repository.
Automatic transcription of Gaelic handwriting using Transkribus
The work began with the Digital Imaging Unit scanning about 2500 pages of handwritten manuscripts from the School of Scottish Studies Archives, supplemented by some additional scanning at the Centre for Research Collections.
Scanning manuscripts at the Centre for Research Collections
Once we received the texts, research assistant Michael Bauer manually transcribed about 18,000 words, which we used to generate our first Gaelic handwriting model. This achieved an impressive Character Error Rate (CER) of 2.53% – accuracy about 97.5%, but this was developed from and tested on one writer’s hand. We used this model to help transcribe a further 18,000 words and trained a second model. Again, this involved only one hand, but achieved a CER of 1.90%.
Using the updated model, we are moving towards our target of 500k words. We have focussed the transcription efforts recently on increasing the number of hands involved, so that our next model is more generalisable and useful. The project will finish in July 2020, when we intend to make the Gaelic handwriting recogniser available to the public through Transkribus.